本文主要是介绍RK3568笔记三十二:PaddleSeg训练部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、环境
1、Autodl配置
PyTorch 1.7.0Python 3.8(ubuntu18.04)Cuda 11.0
2、所需环境需求
- OS: 64-bit
- Python 3(3.6/3.7/3.8/3.9/3.10),64-bit version
- pip/pip3(9.0.1+),64-bit version
- CUDA >= 10.2
- cuDNN >= 7.6
- PaddlePaddle (the version >= 2.4)
3、开发板:ATK-DLRK3568
二、搭建环境
1、创建环境
conda create -n paddleseg_env python=3.8
2、激活
source activate
conda activate paddleseg_env
3、安装PaddlePaddle
python -m pip install paddlepaddle-gpu==2.4.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple
验证
>>> import paddle
>>> paddle.utils.run_check()# If the following prompt appears on the command line, the PaddlePaddle installation is successful.
# PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.# Confirm PaddlePaddle version
>>> print(paddle.__version__)

4、安装PaddleSeg
1) 下载地址
PaddlePaddle/PaddleSeg at release/2.8 (github.com)
2)安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -v -e .
5、测试
sh tests/install/check_predict.sh
三、训练
1、下载数据集
开源数据集:https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip
下载后把数据放到 data目录下,没有目录新创建一个
2、train
export CUDA_VISIBLE_DEVICES=0 # Linux上设置1张可用的卡python tools/train.py --config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml --do_eval --use_vdl --save_interval 500 --save_dir output
上述训练命令解释:
--config指定配置文件。--save_interval指定每训练特定轮数后,就进行一次模型保存或者评估(如果开启模型评估)。--do_eval开启模型评估。具体而言,在训练save_interval指定的轮数后,会进行模型评估。--use_vdl开启写入VisualDL日志信息,用于VisualDL可视化训练过程。--save_dir指定模型和visualdl日志文件的保存根路径。
开始训练

训练的模型权重保存在output目录下,如下所示。总共训练1000轮,每500轮评估一次并保存模型信息,所以有iter_500和iter_1000文件夹。评估精度最高的模型权重,保存在best_model文件夹。后续模型的评估、测试和导出,都是使用保存在best_model文件夹下精度最高的模型权重。
output├── iter_500 #表示在500步保存一次模型├── model.pdparams #模型参数└── model.pdopt #训练阶段的优化器参数├── iter_1000 #表示在1000步保存一次模型├── model.pdparams #模型参数└── model.pdopt #训练阶段的优化器参数└── best_model #精度最高的模型权重└── model.pdparams
train.py脚本输入参数的详细说明如下。
| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| iters | 训练迭代次数 | 否 | 配置文件中指定值 |
| batch_size | 单卡batch size | 否 | 配置文件中指定值 |
| learning_rate | 初始学习率 | 否 | 配置文件中指定值 |
| config | 配置文件 | 是 | - |
| save_dir | 模型和visualdl日志文件的保存根路径 | 否 | output |
| num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 0 |
| use_vdl | 是否开启visualdl记录训练数据 | 否 | 否 |
| save_interval | 模型保存的间隔步数 | 否 | 1000 |
| do_eval | 是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model | 否 | 否 |
| log_iters | 打印日志的间隔步数 | 否 | 10 |
| resume_model | 恢复训练模型路径,如:output/iter_1000 | 否 | None |
| keep_checkpoint_max | 最新模型保存个数 | 否 | 5 |
3、模型评估
python tools/val.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--model_path output/iter_1000/model.pdparams

4、模型预测
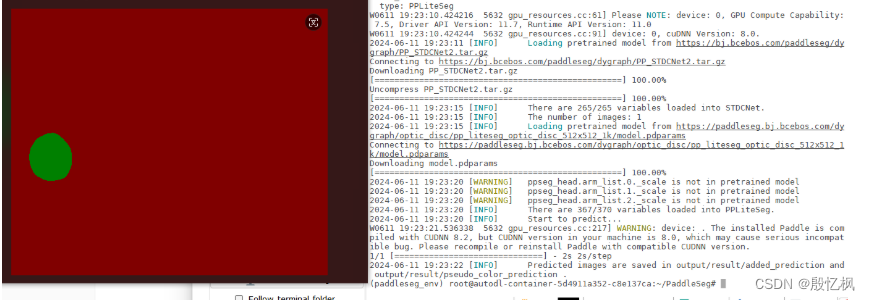
python tools/predict.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--model_path output/iter_1000/model.pdparams \--image_path data/optic_disc_seg/JPEGImages/H0003.jpg \--save_dir output/result

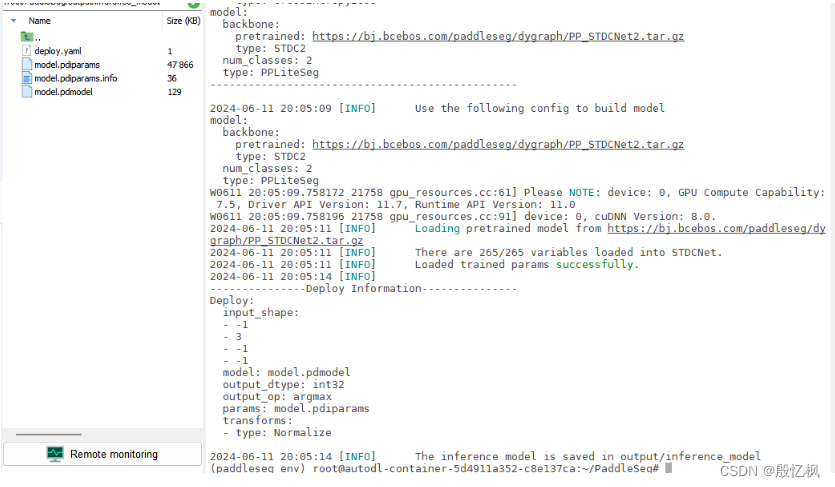
5、导出预测模型
PaddleSeg训练好模型J是动态的,将模型导出为预测模型、使用预测库进行部署,可以实现更快的推理速度。
将训练出来的动态图模型转化成静态图预测模型
python tools/export.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--model_path output/best_model/model.pdparams \--save_dir output/infer_model
四、模型导出
1、导出ONNX模型
pip install paddle2onnx
pip install tensorrt
pip install pycuda
pip install onnx
pip install protobuf==3.20.0
python deploy/python/infer_onnx_trt.py \--config <path to config> \--model_path <path to model> \--width <img_width> \--height <img_height> # 注意使用是转换后的静态图预测模型
python deploy/python/infer_onnx_trt.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--model_path output/infer_model/model.pdparams \--width 512 \--height 512 
虽然报错,但导出成功
2、RKNN导出
到处RKNN需要rknn环境,自行搭建
python convert.py ../model/pp_liteseg_cityscapes.onnx rk3568

这篇关于RK3568笔记三十二:PaddleSeg训练部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







