本文主要是介绍自然场景文本检测CTPN原理详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自然场景文本检测CTPN流程详解
标签: 文本检测 CTPN tensorflow
说明: 借鉴了网上很多资源,如有侵权,请联系本人删除!
摘要
对于自然场景中的文本检测,难点是:字体多变、遮挡、不规则变化等,其实对于实际的应用场景,针对自己的需求可以采用通用的目标检测框架(faster Rcnn,SSD,Yolo,Retina)等网络,或许也能满足项目的需求。
而CTPN等用于文本检测的方法,对自然场景的文本检测具有更强的鲁棒性,就是针对文本检测较SSD,Yolo等可能具有更高的精度;其次文本检测中涉及到旋转和仿射变化等,此时,通用的目标检测框检就不合适。

CTPN优点
- 采用固定宽度的anchor,只做一个h回归
- 特征提取的过程中采用VGG作为base net 再加上一个conv3×3_512,再以W方向为序列(sequence),512为特征数(input feature),经过双向LSTM。主要目的,提高特征之间的练习
- 这里有一个疑问,既然在W方向送入LSTM,进行了特征增强,那是否可以在H方向增强特征的联系。
网络模型与前向传播过程
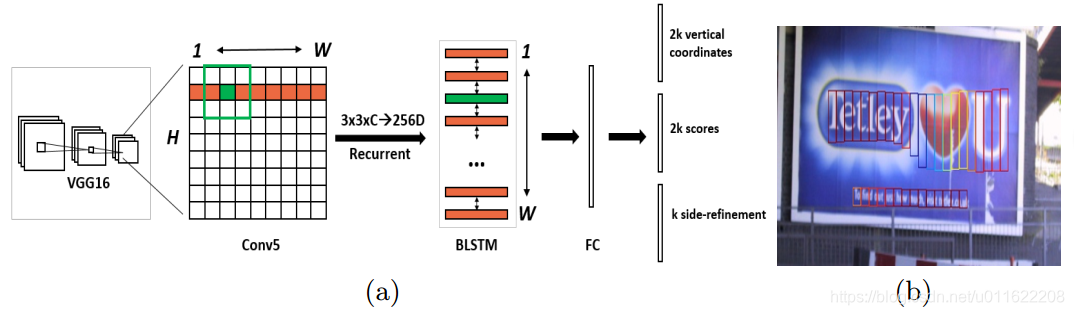
模型结构如上图所示
整个模型的前向传播过程如下(以1张图片为例):
- 采用VGG16作为base net进行特征提取。假设经过VGG之后的feature map为:W×H×C。
- 增加一个conv3×3_512的卷积层,(这一步网上好多说是用3×3的窗口做滑窗,我看tensorflow的源码,就是做了一个卷积,具体可查原论文和official code)。这一步的输出还是为:feature map:W×H×C=512。
- 将上一步的feature map reshape为LSTM的输入格式,LSTM采用128个隐藏节点的双向Bilstm,输出之后再接256×512的线性层,线性层输出之后再reshape为1×W×H×C,即和输入尺寸一样;在tensorflow中上一步的feature map reshape为:[1 × H, W, C=512],应该是(batch, steps, inputs)的格式,因为是增强特征在W方向的联系,于是应该以W为steps。这一步的输出为:feature map:1×W×H×C=512。
- 线性回归层512×(10×4)做anchor的坐标预测,512:每个点的特征数,10:每个点有10个不同高度的anchors,4:一个anchor有4个坐标点(xmin,xmax,ymin,ymax);线性回归层512×(10×2)做类别预测,2:两个类别,是文本,不是文本。这一步的输出为:box_coordinate_pred:1×W×H×(104),box_label_pred:1×W×H×(102),
- 共生成W×H×10个anchors,采用和faster rcnn类似的策略对每个anchor,指定target_box和target_label
- 计算交叉熵和坐标点的L1smooth loss。tensorflow源码中还回归输出了inside_weights和outside_weights,两个都为:1×W×H×(10*4),这个不知道怎么用的。
训练
对于每一张训练图片,总共抽取128个样本,64正64负,如果正样本不够就用负样本补齐。这个和faster rcnn的做法是一样的。
测试 TODO
- TO DO …
Tricks
- 采用densenet,resnet等最新的base net,这里安利一下pytorch,tensorflow的模型建模和调试确实没有pytorch方便
- 对H方向也采用一定策略(LSTM或其他方法)进行特征增强
reference
- CTPN/CRNN的OCR自然场景文字识别理解(一)
- https://github.com/eragonruan/text-detection-ctpn
这篇关于自然场景文本检测CTPN原理详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





