本文主要是介绍MYSQL部分术语及原理解释(缓冲池、LRU、redo log buffer、WAL、Checkpoint、LSN),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、缓冲池 Buffer Pool
- 二、 LRU List、Free List、Flush List
- 三、 重做日志缓存redo log buffer
- 四、WAL与Checkpoint
- 五、LSN
总结来自《MySQL技术内幕 InnoDB存储引擎》 第二版
一、缓冲池 Buffer Pool
InnoDB存储引擎的MySQL是基于磁盘的数据库系统。缓冲池是一片内存区域,在数据库读取页的操作,首先将磁盘读到的页存放在缓冲池中,再次读取时先判断该页是否在缓冲池中,若在,则命中buffer读取页,否则读取磁盘的页。以此来解决CPU速度与磁盘速度之间的鸿沟,提高整体性能。
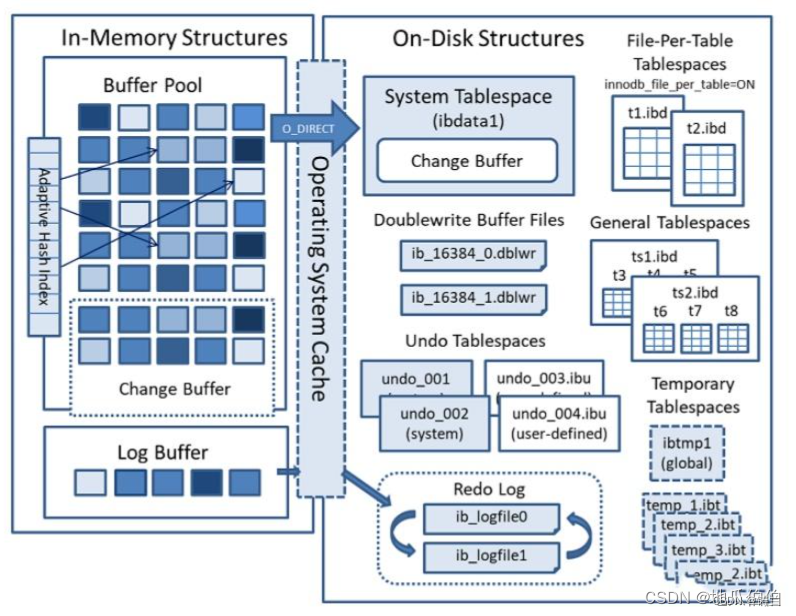 其中buffer pool 内容
其中buffer pool 内容
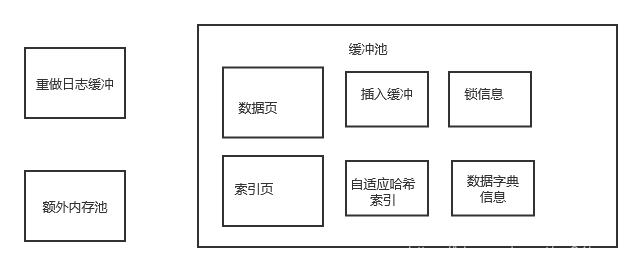
1. 索引页(Index Pages)
索引页存储了InnoDB表的索引结构,包括主键索引(聚集索引)和辅助索引(非聚集索引)。这些索引页被加载到缓冲池中,以加速对表中数据的查找和访问。当执行查询操作时,InnoDB会首先检查所需的索引页是否已经在缓冲池中,如果在,则直接从缓冲池中读取,这称为缓冲池命中;如果不在,则需要从磁盘加载到缓冲池中,这称为缓冲池未命中。
2. 数据页(Data Pages)
数据页存储了InnoDB表的实际数据行。在InnoDB中,数据是按页存储的,每个数据页通常包含多行数据。当需要读取或修改表中的数据时,相关的数据页会被加载到缓冲池中。通过将数据页缓存在内存中,InnoDB可以快速地读取和修改数据,而无需每次都从磁盘加载。
3. Undo页(Undo Pages)
Undo页存储了旧版本的数据,用于支持事务的ACID属性中的隔离性(Isolation)和持久性(Durability)。当执行一个事务时,对数据的修改不会立即生效,而是先记录在Undo页中。如果其他事务需要读取被修改的数据,它可以通过Undo页来获取数据修改前的版本,从而实现多版本并发控制(MVCC)。此外,如果事务失败或回滚,Undo页中的数据可以用于恢复数据到事务开始前的状态。
4.插入缓存(Insert Buffer)
插入缓存是InnoDB中用于优化非聚集索引插入操作的一种机制。当向一个包含非聚集索引的表中插入数据时,如果相关的索引页不在缓冲池中,InnoDB不会立即将索引键插入到索引页中,而是将其存储在插入缓存中。当相关的索引页被加载到缓冲池时,插入缓存中的索引键会被合并并插入到索引页中。这样可以减少磁盘I/O操作,并提高插入操作的性能。
需要注意的是,插入缓存只适用于非唯一索引的插入操作,并且在某些情况下,如缓冲池足够大或表很小,插入缓存可能不会被使用。
5. 自适应哈希索引(Adaptive Hash Index)
自适应哈希索引是InnoDB存储引擎的一个特性,用于自动根据访问模式创建哈希索引。当某些索引值被频繁访问时,InnoDB会将这些索引值存储在自适应哈希索引中,以加速对这些值的查找。自适应哈希索引是完全自动的,不需要用户手动创建或维护。当哈希索引不再被频繁使用时,InnoDB会自动删除它们以释放内存。
6. InnoDB的锁信息(Lock Information)
InnoDB存储引擎使用锁来确保并发访问时的数据一致性和完整性。在缓冲池中,InnoDB会维护锁信息,以跟踪哪些数据页或行被锁定,以及锁的类型(如共享锁或排他锁)。这些锁信息对于实现事务的隔离性和并发控制至关重要。当事务尝试访问被其他事务锁定的数据时,它会根据锁的类型和事务的隔离级别来决定是等待锁释放还是立即返回错误。
二、 LRU List、Free List、Flush List
LRU List(Latest Recently Used):最近最少使用链表,用于管理缓存页的访问顺序和淘汰策略。MySQL 使用的是优化过的LRU列表(加入一个midpoint的位置,最新访问的页并不防砸LRU列表首部而是放在midpoint的位置,为了解决原始LRU 列表会导致因为普通一次性的SQL查询访问页会将活跃的热点数据会被刷新出缓存池的问题)。
Free List:用于管理Buffer Pool中当前未被使用的空闲页。当一个页被从LRU链表或其他链表中移除时,它会被加入到free链表中。当需要加载新的页到Buffer Pool时,InnoDB会首先从free链表中获取空闲页。如果free链表为空,InnoDB则需要从LRU链表中淘汰页来腾出空间。
Flush List:脏页列表,用于管理那些被修改过(即脏页)并且需要被刷新到磁盘上的缓存页。当一个事务提交或Buffer Pool中的空闲空间不足时,InnoDB会选择一些脏页加入到flush链表中,并在适当的时机(checkpoint)将它们刷新到磁盘上。flush链表确保了脏页能够按照一定的顺序和优先级被刷新,从而保证了数据的持久性和一致性。
脏页既存储在LRU list中又存储在Flush List表中,LRU列表用来管理缓冲池中页的可用性,Flush列表用来管理将页刷新到磁盘,二者互不影响。
三、 重做日志缓存redo log buffer
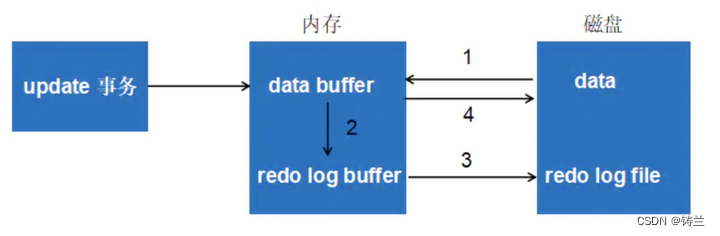 InnoDB存储引擎首先将redo log重做日志信息放入缓存区,按照一定频率将其刷新到重做日志文件,redo log buffer 默认为8MB
InnoDB存储引擎首先将redo log重做日志信息放入缓存区,按照一定频率将其刷新到重做日志文件,redo log buffer 默认为8MB
3种情况会将redo log buffer的内容刷新到 redo log
- Master Thread 每秒将redo log buffer刷新到redo log
- 每个事务提交时会将 redo log buffer 缓冲刷新到redo log
- 当redo log buffer 剩余空间小于1/2时,刷新到redo log
四、WAL与Checkpoint
WAL(Write Ahead Log):当前事务数据库系统普通使用WAL策略,即当事务提交时,先写重做日志,再修改页(如上图redo log 写盘步骤)。此方法是为了解决发生宕机而导致数据丢失时,可通过重做日志完成数据恢复,保证事务的ACID的D(durability 持久性)要求。
Checkpoint:检查点。
redo log 不可能非常大,否则数据库发生故障后恢复数据的时间、代价非常大,缓冲池大小也有限,脏页不可能一直不刷新到磁盘。
checkpoint解决以下几个问题
- 缩短数据库的恢复时间
- 缓冲池 buffer pool 不够用时,将脏页刷新到磁盘
- 重做日志不可用时,刷新脏页
当数据库宕机时,数据库不需要重做所有日志因为checkpoint之前的页已经刷新回磁盘。这样就缩短了恢复时间。
缓冲池大小不够用时,根据LRU算法回溢出最少使用的页,若此页为脏页就需要强制执行checkpoint,将页的新版本刷新到磁盘。
重做日志大小有限,旧版本、不再需要的重做日志,这部分空间就可以覆盖重用。若此时重做日志还需要使用,则必须强制产生checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
五、LSN
LSN(Log Sequence Number):用来标记版本的8字节数字。
缓冲池中的每个页、重做日志、checkpoint 都有LSN
这篇关于MYSQL部分术语及原理解释(缓冲池、LRU、redo log buffer、WAL、Checkpoint、LSN)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








