本文主要是介绍【Oracle生产运维】数据库服务器负载过高异常排查处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
在Oracle数据库运维工作中,经常会遇到Oracle数据库服务器平均负载(load average)突然异常升高,如果放任不管,严重的情况下会出现数据库宕机、服务器重启等重大故障。因此,当发现数据库服务器平均负载异常高的时候,必须予以重视,并立即开展处理工作。
很多刚工作或者是没这方面处理经验的同学可能遇到这种情况就会开始慌张,不知从何下手,无法快速定位出引起负载异常的原因。
下面介绍我在工作中常用的排查思路供大家参考。截图的结果皆在实验环境中截取,与实际生产环境有较大出入,只作为操作演示。
1 负载过高现象
巡检发现、监控平台或者在操作系统中执行命令,显示load average值异常过高。
Linux常用的load average监控命令:
[oracle@oracle11g ~]# sar -q 1 5
此命令可以查看当前的平均负载,以及一分钟以来、五分钟以来和十五分钟以来的平均负载。
引起Oracle数据库服务器负载异常增高的原因有很多不同情况,以下是比较常见的情况:
- 大量排序、SQL解析、慢SQL引起CPU过高;
- 大量直接路径读、全表扫描、并发读写引起IO繁忙。
2 确认高负载类型
需要确认负载突然异常增高是CPU还是IO或者共同引起的,缩小问题范围,为下一步定位具体原因做准备。
登录数据库服务器,切换到orace用户。
2.1 检查平均负载
[oracle@oracle11g ~]$ sar -q 1 5
Linux 2.6.32-642.el6.x86_64 (oracle11g) 06/09/2024 _x86_64_ (1 CPU)05:34:11 AM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
05:34:12 AM 0 382 0.49 0.43 0.47
05:34:13 AM 0 382 0.49 0.43 0.47
05:34:14 AM 0 382 0.49 0.43 0.47
05:34:15 AM 0 382 0.49 0.43 0.47
05:34:16 AM 0 382 0.49 0.43 0.47
Average: 0 382 0.49 0.43 0.47
说明:
- runq-sz:运行队列,也就是等待运行的进程数;
- plist-sz:进程创建的总数,包括线程;
- ldavg-1:最后1分钟的平均负载;
- ldavg-5:最后5分钟的平均负载;
- ldavg-15:最后15分钟的平均负载。
如果runq-sz值很高,表明可能是CPU资源使用率过高引起的,若值低可能是IO过高引起的。
这里只是一个初步判断,需要执行下面的命令确认猜测。
2.2 检查CPU使用率
1)执行top命令查看所有进程的cpu和内存使用情况
[oracle@oracle11g ~]$ top -c
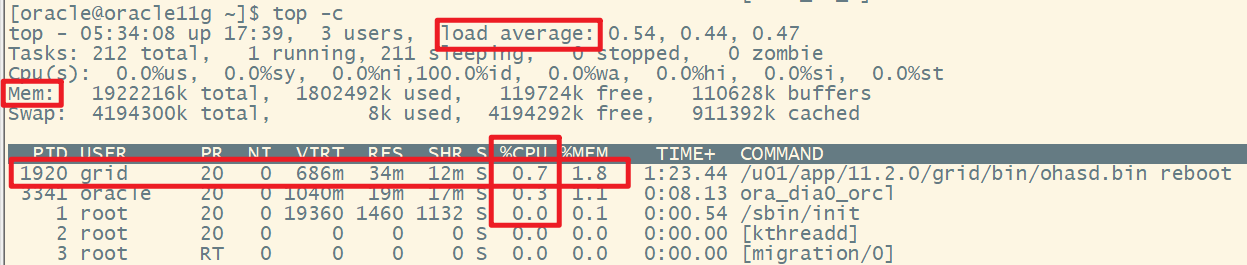
主要观察排在前几位的进程的%CPU,一般当负载异常时,前面两三个进程的%CPU会在100%。
top命令也可以看到平均负载load average的情况。
2)执行iostat命令查看CPU平均利用率
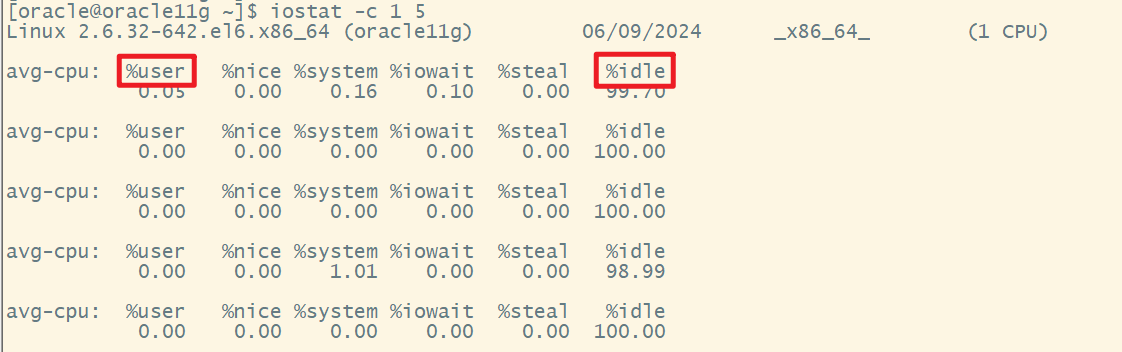
说明:
- %user:用户空间的cpu使用率;
- %idle:空闲的cpu。
如果%idle过高,说明CPU使用率过高。
2.3 检查I/O传送速率
1)查看IO等待
%iowait为CPU等待IO的百分比,如果非常高,则说明IO有瓶颈。
[oracle@oracle11g ~]$ iostat -c 1 5
Linux 2.6.32-642.el6.x86_64 (oracle11g) 06/09/2024 _x86_64_ (1 CPU)avg-cpu: %user %nice %system %iowait %steal %idle0.05 0.00 0.16 0.10 0.00 99.70avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 1.01 0.00 0.00 98.99avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 0.00 0.00 100.00avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 1.00 1.00 0.00 98.00avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 1.02 0.00 98.98
2)查看IO速率
[oracle@oracle11g ~]$ sar -b 1 5
Linux 2.6.32-642.el6.x86_64 (oracle11g) 06/09/2024 _x86_64_ (1 CPU)05:42:33 AM tps rtps wtps bread/s bwrtn/s
05:42:34 AM 12.12 4.04 8.08 129.29 97.98
05:42:35 AM 12.12 0.00 12.12 0.00 114.14
05:42:36 AM 8.08 0.00 8.08 0.00 97.98
05:42:37 AM 15.15 4.04 11.11 129.29 130.30
05:42:38 AM 43.43 7.07 36.36 226.26 502.02
Average: 18.18 3.03 15.15 96.97 188.48
说明:
- tps:每秒钟的I/O操作总数。这个值如果持续很高,可能表明磁盘I/O非常繁忙;
- rtps:每秒钟的读操作数。高读操作数可能表明有大量的数据被读取;
- wtps:每秒钟的写操作数。高写操作数可能表明有大量的数据被写入;
- bread/s:每秒钟从物理设备读入的数据量,单位为 块/s。块的大小通常为512字节;
- bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s;
- rb/c 和 wb/c:分别是每次读取和写入操作的平均块数。如果这个值很低,可能表明有许多小的I/O请求,这可能导致磁盘性能问题。
3 定位问题,找出引起高负载的SQL语句
Oracle数据库问题的大部分原因基础都是由SQL语句引起的。
假设经过上面的排查,确定为CPU使用率高引起的高负载,下面通过几个脚本定位到引起CPU使用率过高的SQL语句。
3.1 直接找到引起高负载的TOP SQL
登录数据库,检查近xx分钟的资源使用率(CPU、IO)TOP5的SQL:
SQL>
select ash.sql_id,sum(decode(ash.session_state,'on cpu',1,0)) "cpu",sum(decode(ash.session_state,'waiting',1,0)) -sum(decode(ash.session_state,'waiting',decode(en.wait_class,'user i/o',1,0),0)) "wait",sum(decode(ash.session_state,'waiting',decode(en.wait_class,'user i/o',1,0),0)) "io",sum(decode(ash.session_state,'on cpu',1,1)) "total"from v$active_session_history ash,v$event_name enwhere sql_id is not null and en.event#=ash.event# and ash.sample_time > sysdate -&min/(24*60)group by ash.sql_idorder by sum(decode(ash.session_state,'on cpu',1,1)) desc;
根据sql_id找到对应的sql_text:
SQL> select SQL_TEXT from v$sqltext where sql_id = '&sql_id' order by piece;
3.2 根据进程号找出SQL
前面查看cpu负载的时候使用了top命令,输出的信息中就包含有进程号PID,根据这个PID可以定位到具体是哪条SQL语句。

将异常的PID代入Oracle的几个常用的性能视图:
SQL>
set long 999999999999999999
set pages 200
select st.sql_id,st.sql_testfrom v$sqltext st,v$session se,v$process pwhere st.sql_id = se.sql_idand se.paddr = p.addrand p.spid = '&PID'order by st.piece;
得到的sql_test即为引起CPU高负载的SQL语句。
3.3 根据等待事件判断找出SQL
此方法需要对常见的等待事件比较熟悉。
查看当前正在执行的会话和相应等待事件:
SQL>
set lines 300
col machine for a20
col username for a20
col event for a30
col program for a25
col state for a10
select inst_id,sid,serial#,sql_id,sql_hash_value shv,event,username,program,machine,blocking_instance bi,blocking_session bs,seconds_in_wait wait_mfrom gv$sessionwhere (event not like '%dbms%' and event not like '%gcs remote%' and event not like '%mon timer%'and event not like '%SQL Net%' and event not like '%Streams AQ%' and event not like '%jobq slave wait%'and event not like '%ASM background timer%' and event not like '%DIAG idle wait%'and event not like '%VKTM logical idle Wait%' and event not like '%ges remote message%' and event not like '%Space Manager slave idle wait%' and event not like '%class slave wait%' and event not like '%wait for unread message on broadcast channel%' and event not like '%pmon timer%')and status = 'ACTIVE' and wait_class != 'idle'and sql_id is not null order by event,sql_id desc;
主要看出现大量重复的sql_id和event。
注意,当同时存在大量与CPU和IO相关的等待事件时,应根据前面排查的结果侧重分析。即,当明确了是CPU问题时,就应带看CPU相关的等待事件对应的sql_id。
3.4 查看ASH或AWR报告
生成ASH报告或AWR报告需要将快照时间段设置在高负载期间。
当负载异常持续事件是短时间(10-20分钟)时,生成ASH报告。当负载异常持续事件是长时间(1小时以上)时,生成AWR报告。
分析报告也是需要对等待事件比较熟悉,此处就不对ASH报告和AWR报告的分析方法做说明,请自行查阅资料。
报告生成方法:
------ASH
# su - oracle
$ cd
$ sqlplus / as sysdba
SQL> @?/rdbms/admin/ashrpt.sql------AWR
# su - oracle
$ cd
$ sqlplus / as sysdba
SQL> @?/rdbms/admin/awrrpt.sql
报告生成的目录在oracle用户家目录下。
4 问题处理
找出引起高负载的问题SQL语句后,反馈给业务或应用或开发进行检查处理,同时也需要配合他们进行分析。
这篇关于【Oracle生产运维】数据库服务器负载过高异常排查处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





