本文主要是介绍Java8 - IdentityHashMap源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
先来看看源码中的部分注释,这能够让我们对这个容器有一个初步的了解:
This class implements the Map interface with a hash table, using reference-equality in place of object-equality when comparing keys (and values). In other words, in an IdentityHashMap, two keys k1 and k2 are considered equal if and only if(k1==k2). (In normal Map implementations (like HashMap) two keys k1 and k2 are considered equal if and only if (k1==null ? k2==null : k1.equals(k2)).).
This class is not a general-purpose Map implementation! While this class implements the Map interface, it intentionally violates Map’s general contract, which mandates the use of the equals method when comparing objects. This class is designed for use only in the rare cases wherein reference-equality semantics are required.
A typical use of this class is topology-preserving object graph transformations, such as serialization or deep-copying. To perform such a transformation, a program must maintain a “node table” that keeps track of all the object references that have already been processed. The node table must not equate distinct objects even if they happen to be equal. Another typical use of this class is to maintain proxy objects. For example, a debugging facility might wish to maintain a proxy object for each object in the program being debugged.
This class provides all of the optional map operations, and permits null values and the null key. This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
从上面这几段注释中,我们大致可以了解到:IdentityHashMap 是一个实现了 Map 接口的哈希表,它使用了引用相等来替代对象相等,即只有 k1 == k2 的情况下,才认为这两个对象相等。(以往容器判断相等的方式都是通过 if(k1 == null ? k2 == null : k1.equals(k2)),判断值是否相等来判断的。)所以,这个容器允许存在多个键相等(但引用不相等)的键值对。另外,这个容器允许 null 键和 null 值,但不保证元素遍历的顺序。
注释中还提到,这个容器不是一个通用的 Map 实现,它故意违反 Map 的约定来应对特殊情况下的需求,例如序列化、深拷贝或者维护代理对象等。
二、线性探测法
与以往的 Hash 容器不同,IdentityHashMap 处理哈希冲突的方式是通过线性探测法。下面先简单对线性探测法做一个介绍,如果还不是很清楚,可以自行查阅其他资料。
对于使用线性探测法的哈希表来说,可以在一个桶里存储一个键值对,当然也可以键值各存储一个桶,键值严格相邻,而 IdentityHashMap 采用的就是后者,如下图所示:

对于线性探测法,在添加元素的时候如果产生了冲突,会检查下一个位置是否可以存储元素,可以的话则存储,否则继续检查下一个位置,直至找到能存储的位置为止,过程如图所示:
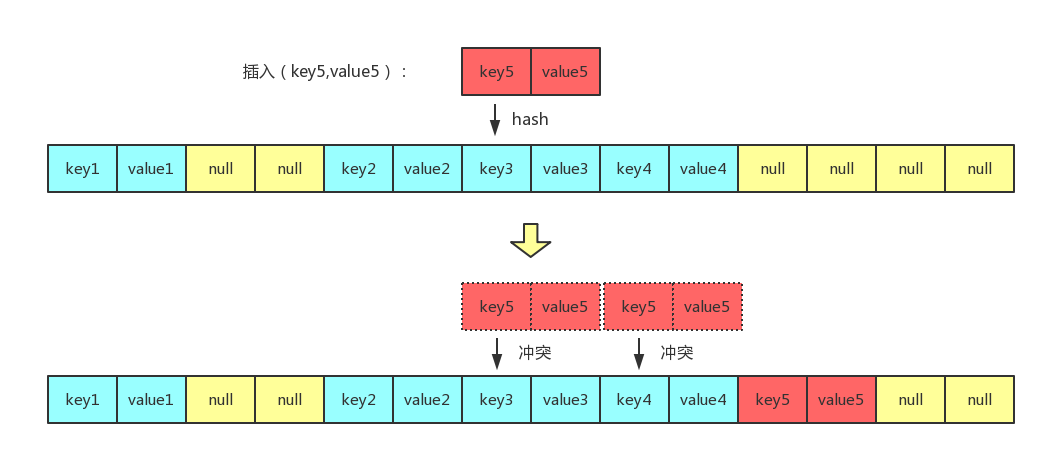
而获取元素的过程跟添加元素差不多,也是先通过哈希定位到一个桶,然后一直比较key的引用是否相等,如果相等则表示找到了,否则会一直跟下一个键值对比较,直至遇到 null 的桶才表示该哈希表中不存在此键值对。所以对于线性探测法的哈希表来说,至少需要保证有一个 key 为 null 的桶,否则会发生死循环。
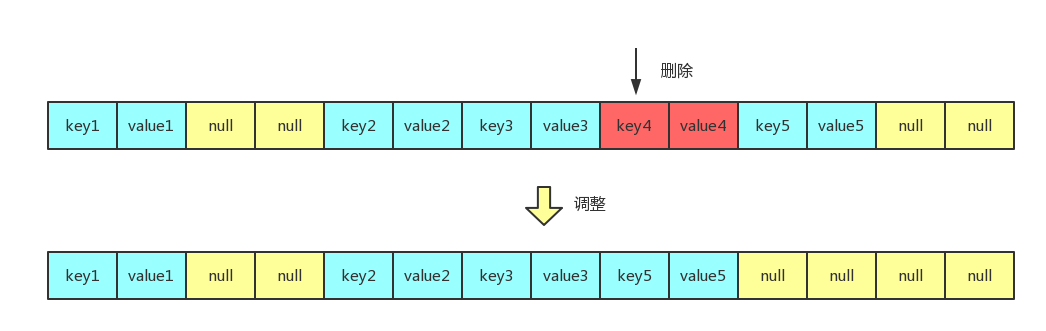
对于线性探测法来说,删除某个元素之后需要对哈希表进行一定程度的调整,否则就有可能出现找不到对应键值对的情况。例如上图,如果我直接把 key4 删除了而不做调整,那么在找 key5 的时候,会先定位到 key3,很显然 key3 不是我们要找的,所以它会与 key3 的下一个位置进行比较,此时它会发现该位置为 null,表示哈希表中不存在 key5,然而实际上 key5 是存在的。所以对于线性探测法来说,删除元素之后是必须对部分键值对作出调整,例如上图删除 key4 后调整的结果如下图所示,此时再获取 key5 的值就可以获取到了。
三、属性
//哈希表的默认容量
private static final int DEFAULT_CAPACITY = 32;//哈希表的最小容量
private static final int MINIMUM_CAPACITY = 4;//哈希表的最大容量
private static final int MAXIMUM_CAPACITY = 1 << 29;//哈希表
transient Object[] table; // non-private to simplify nested class access//哈希表中键值对的个数
int size;//替代null键的对象
static final Object NULL_KEY = new Object();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这里需要注意一下,容量是指能容纳的键值对个数,而不是指哈希表的长度,对于 IdentityHashMap 来说,哈希表的长度等于两倍的哈希表的容量。IdentityHashMap 没有在属性中定义负载因子的大小,而是通过代码来体现,它的负载因子的大小为 2/3,也就是说哈希表默认容量为 32 的情况下,当表中超过 21 个键值对之后,就需要进行扩容了。另外,在属性中还有一个 NULL_KEY 对象,我们往 IdentityHashMap 中插入的所有 null 键都会被这个对象所替代。虽然该容器定义的最大容量为 MAXIMUM_CAPACITY,但是实际上最多只能存储 MAXIMUM_CAPACITY-1 个键值对,这是因为该容器采用线性探测法来处理冲突,所以它必须保证至少有一个为 null 的桶来避免死循环。
四、方法
1、构造方法
//无参构造方法
public IdentityHashMap() {init(DEFAULT_CAPACITY);
}//指定初始容量
public IdentityHashMap(int expectedMaxSize) {if (expectedMaxSize < 0)throw new IllegalArgumentException("expectedMaxSize is negative: " + expectedMaxSize);init(capacity(expectedMaxSize));
}//指定map对象
public IdentityHashMap(Map<? extends K, ? extends V> m) {// Allow for a bit of growththis((int) ((1 + m.size()) * 1.1));putAll(m);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
IdentityHashMap 的构造方法一眼就看完了,其中有两个关键的方法 capacity 和 init 的源码如下:
//根据expectedMaxSize计算容量大小
private static int capacity(int expectedMaxSize) {// assert expectedMaxSize >= 0;return (expectedMaxSize > MAXIMUM_CAPACITY / 3) ? MAXIMUM_CAPACITY :(expectedMaxSize <= 2 * MINIMUM_CAPACITY / 3) ? MINIMUM_CAPACITY :Integer.highestOneBit(expectedMaxSize + (expectedMaxSize << 1));
}//初始化哈希表
private void init(int initCapacity) {// assert (initCapacity & -initCapacity) == initCapacity; // power of 2// assert initCapacity >= MINIMUM_CAPACITY;// assert initCapacity <= MAXIMUM_CAPACITY;table = new Object[2 * initCapacity];
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
其中,capacity 方法中的 Integer.highestOneBit 方法的作用是仅保留二进制中最高位的 1,其他位全置 0。例如,15 的二进制表示为 1111,那么通过此方法计算之后得到的结果将会是 1000,即最终的结果为 8。另外,我们还发现 init 方法中为哈希表进行初始化时,是两倍的 initCapacity 大小,也就是说使用默认容量 DEFAULT_CAPACITY 创建的哈希表长度是 64,而不是32,这是因为 IdentityHashMap 采用的键值对存储方式决定的。
在开始研究 IdentityHashMap 常用的方法之前,我们先来看几个与接下来内容相关的方法:
//哈希方法
private static int hash(Object x, int length) {int h = System.identityHashCode(x);// Multiply by -127, and left-shift to use least bit as part of hashreturn ((h << 1) - (h << 8)) & (length - 1);
}//计算下一个键的位置
private static int nextKeyIndex(int i, int len) {return (i + 2 < len ? i + 2 : 0);
}private static Object maskNull(Object key) {return (key == null ? NULL_KEY : key);
}static final Object unmaskNull(Object key) {return (key == NULL_KEY ? null : key);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在 hash 方法中,是通过 identityHashCode 方法来获取对象的哈希值。identityHashCode 是一个 native 方法,它是通过对象的内存地址来计算哈希值的,默认情况下 identityHashCode 方法返回的哈希值是跟 hashCode 方法一致的,但是很多对象都会对 hashCode 进行重写,所以这里就直接使用 identityHashCode 方法,而没有采用 hashCode 方法。
nextKeyIndex 方法的作用是计算下一个键的位置,因为 IdentityHashMap 是通过键值各占一个桶来存储的,所以计算下一个键的位置是 i+2,而不是 i+1。
2、添加元素
我们先来看一看源码,再稍作解释,可以结合第二部分的图片一起看,会更容易理解。
public V put(K key, V value) {final Object k = maskNull(key);retryAfterResize: for (;;) {final Object[] tab = table;final int len = tab.length;//获取哈希值int i = hash(k, len);//通过线性探测法查找元素for (Object item; (item = tab[i]) != null; i = nextKeyIndex(i, len)) {if (item == k) {@SuppressWarnings("unchecked")V oldValue = (V) tab[i + 1];tab[i + 1] = value;return oldValue;}}final int s = size + 1;// Use optimized form of 3 * s.// Next capacity is len, 2 * current capacity.//当键值对个数超过表长的1/3的时候,进行扩容if (s + (s << 1) > len && resize(len))continue retryAfterResize;modCount++;tab[i] = k;tab[i + 1] = value;size = s;return null;}
}//扩容
private boolean resize(int newCapacity) {// assert (newCapacity & -newCapacity) == newCapacity; // power of 2//新容量为原来的2倍int newLength = newCapacity * 2;Object[] oldTable = table;int oldLength = oldTable.length;if (oldLength == 2 * MAXIMUM_CAPACITY) { // can't expand any further//判断if (size == MAXIMUM_CAPACITY - 1)throw new IllegalStateException("Capacity exhausted.");return false;}if (oldLength >= newLength)return false;Object[] newTable = new Object[newLength];//rehashfor (int j = 0; j < oldLength; j += 2) {Object key = oldTable[j];if (key != null) {Object value = oldTable[j+1];oldTable[j] = null;oldTable[j+1] = null;int i = hash(key, newLength);while (newTable[i] != null)i = nextKeyIndex(i, newLength);newTable[i] = key;newTable[i + 1] = value;}}table = newTable;return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
IdentityHashMap 在添加元素时,首先会先查看哈希表中有没有引用相等的元素,有的话则直接更新旧值即可,没有才执行插入操作。在插入之前,会先判断需不需要进行扩容,而判断的依据是 “s + (s * 2) > len”,s 表示当前键值对的个数,len 表示当前哈希表的长度,也就是说当键值对的个数超过表长的 1/3 的时候,就会进行扩容。我们知道,在 IdentityHashMap 中,一个键值对占用两个桶,所以也就相当于,当占用的桶的个数超过 2/3 的时候,就进行扩容,这也是前文所说的负载因子为 2/3 的由来。另外,我们在 resize 方法中可以看出,每次扩容都扩成旧容量的两倍,并且还会伴随着一次运算量极大的 rehash 过程。
3、获取元素
与添加元素相比,获取元素的代码非常简单,这里就不多作解释了,结合第二部分的图片,应该是非常容易理解的。
public V get(Object key) {Object k = maskNull(key);Object[] tab = table;int len = tab.length;int i = hash(k, len);while (true) {Object item = tab[i];if (item == k)
return (V) tab[i + 1];if (item == null)
return null;i = nextKeyIndex(i, len);}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4、删除元素
相比起拉链法,线性探测法的删除操作开销很大,在删除元素之后,还需要对其影响到的元素做调整,最坏的情况下需要对所有的元素进行调整,时间复杂度达到了 O(n),而拉链法在删除之后不需要作调整。当然,对于拉链法来说,当所有键值对都映射到同一个桶的时候,最坏情况下也是 O(n),但是 Java8 的 HashMap 使用了红黑树来应对这一种情况,使得最坏的情况下变成了 O(logn)。如果对 Java8 的 HashMap 不了解的,可以看我的另一篇文章。
IdentityHashMap 删除操作的源码如下,可以结合第二部分的图片一起看,会更容易理解。
public V remove(Object key) {Object k = maskNull(key);Object[] tab = table;int len = tab.length;int i = hash(k, len);//找到元素对应的位置,while (true) {Object item = tab[i];if (item == k) {modCount++;size--;@SuppressWarnings("unchecked")V oldValue = (V) tab[i + 1];tab[i + 1] = null;tab[i] = null;//删除元素后需要进行调整closeDeletion(i);return oldValue;}if (item == null)return null;i = nextKeyIndex(i, len);}
}//调整键值对的位置
private void closeDeletion(int d) {Object[] tab = table;int len = tab.length;Object item;for (int i = nextKeyIndex(d, len); (item = tab[i]) != null; i = nextKeyIndex(i, len) ) {int r = hash(item, len);if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {tab[d] = item;tab[d + 1] = tab[i + 1];tab[i] = null;tab[i + 1] = null;d = i;}}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
五、总结
1、IdentityHashMap 是通过引用相等来判断键是否相等的,它是一个允许 null 值和 null 键、允许重复键的 Map 容器。
2、IdentityHashMap 解决哈希冲突的方式是采用线性探测法。
3、IdentityHashMap 默认的初始容量为 32 ,扩容每次扩为原来的两倍。
这篇关于Java8 - IdentityHashMap源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



