本文主要是介绍RT-DETR 详解之查询去噪( DeNoise),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
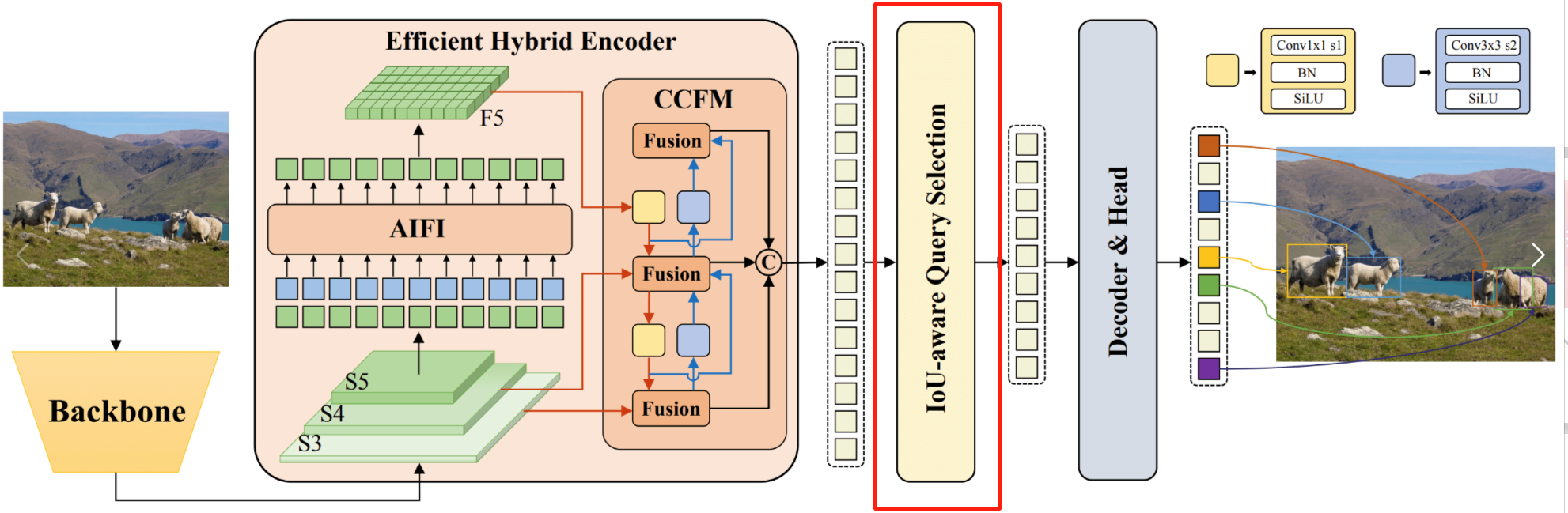
前面我们已经讲解了RT-DETR的基本结构与Efficient Hybrid Encoder部分,在这篇博客里,博主将主要记录RT-DETR的第二个创新点:Uncertainty-minimal Query Selection
查询向量选择为什么重要?
关于 Query Selection(查询向量选择),大家应该并不陌生,这个方法可谓在DETR领域大杀四方,如DAB-DETR对查询向量进行重构理解,将其解释为Anchor,DN-DETR通过查询降噪来应对匈牙利匹配的二义性所导致的训练时间长的问题,DINO提出从Encoder中选择Top-k特征进行学习等一系列方法,这都无疑向我们证明,查询向量很重要,选择好的Query能够让我们事半功倍。
RT-DETR改进查询选择的思路
在RT-DETR中,Query selection 的作用是从 Encoder 输出的特征序列中选择固定数量的特征作为 object queries ,其经过 Decoder 后由预测头映射为置信度和边界框。
前面已经说过,现有的 DETR 变体都是利用这些特征的分类分数直接选择 Top-K 特征。然而,由于分类分数和 IOU 分数的分布存在不一致,分类得分高的预测框并不一定是和 GT 最接近的框,这导致髙分类分数低 IOU 的框会被选中,而低分类分数高 IOU 的框会被丢弃,这将会损害检测器的性能。
因此,RT-DETR考虑通过在训练期间约束检测器对高 IOU 的特征产生高分类分数,对低 IOU 的特征产生低分类分数。故而,作者提出了 Iou-aware Query selection。从而使得模型根据分类分数选择的 Top-K 特征对应的预测框同时具有髙分类分数和高 IOU 分数。
那么,RT-DETR到底是怎么做的呢?大家且听我娓娓道来。
RT-DETR预处理特征
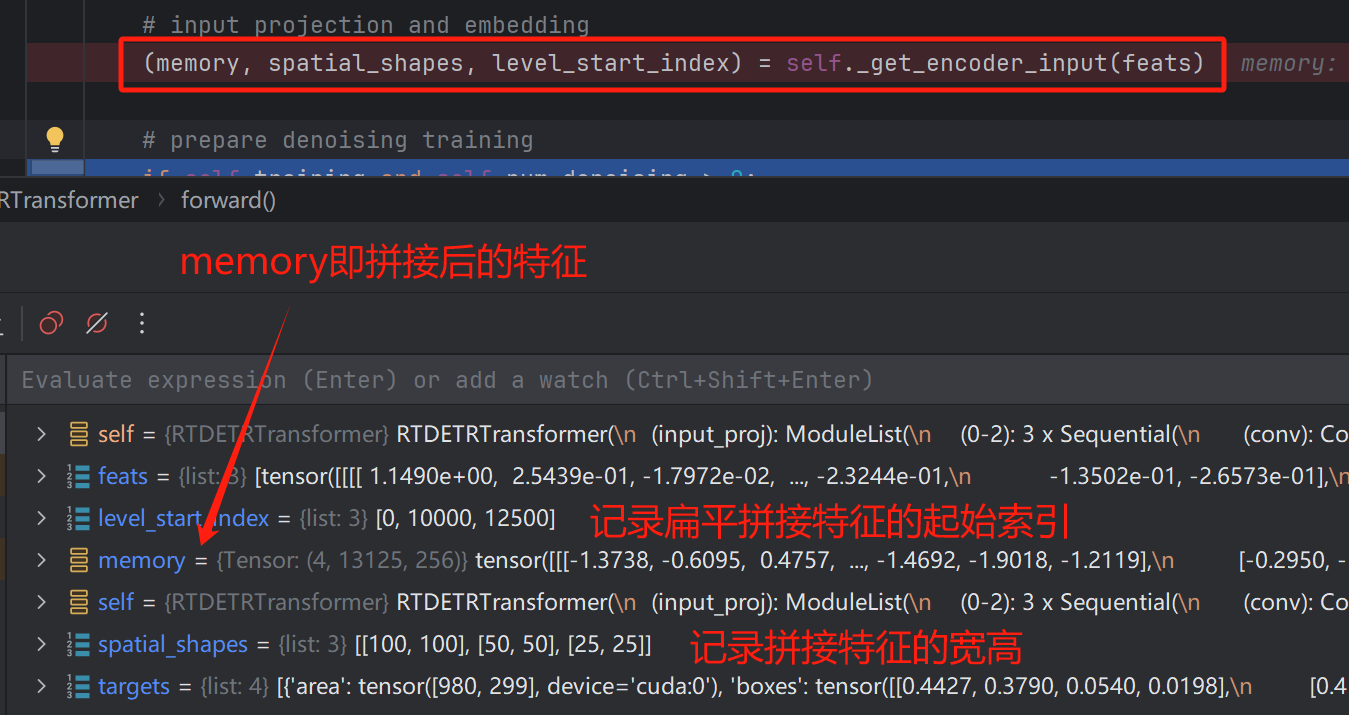
进入到Decoder中后,首先是对Encoder输入的特征进行一个特征融合,将原本的三层特征展平拼接,得到扁平特征。
Encoder输入特征:

扁平融合后的特征:
随后,便可以进行真正的Decoder中的运算了。
在讲解Uncertainty-minimal Query Selection之前,RT-DETR还做了一个DeNoise的操作,该方法并非是RT-DETR所提出的,但其在这里使用了,这个方法便是查询去噪方法。
查询去噪方法
denoising 方法并非是RT-DETR所提出的,其是由DN-DETR所提出的,用于改善由于匈牙利匹配的二义性所导致的模型训练收敛慢的问题,在这里,RT-DETR使用了,denoising是一个很好的创新点,并且也具有十分大的改进空间,大家在想创新点时可以考虑它。
其实,在博主先前的博客DN-DETR详解中,博主已经讲解过DeNoising的实现过程了,今天就带着大家回顾一遍:
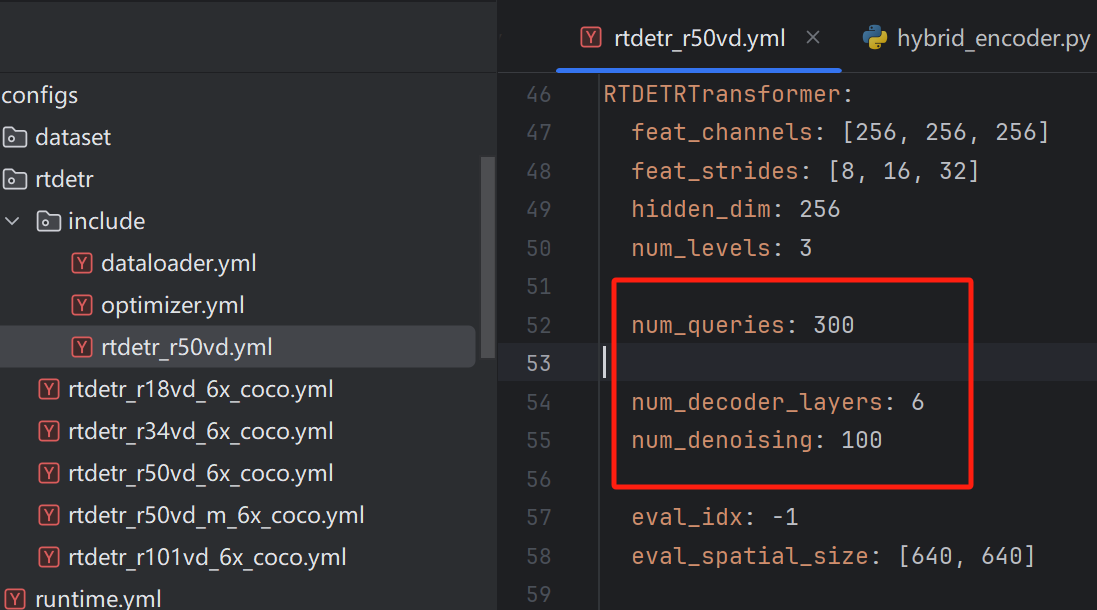
参数讲解
首先关于DeNoising的相关参数,都是在rtdetr_r50中定义好的。
随后便是判断是否使用DeNoising,该方法只在训练时使用:
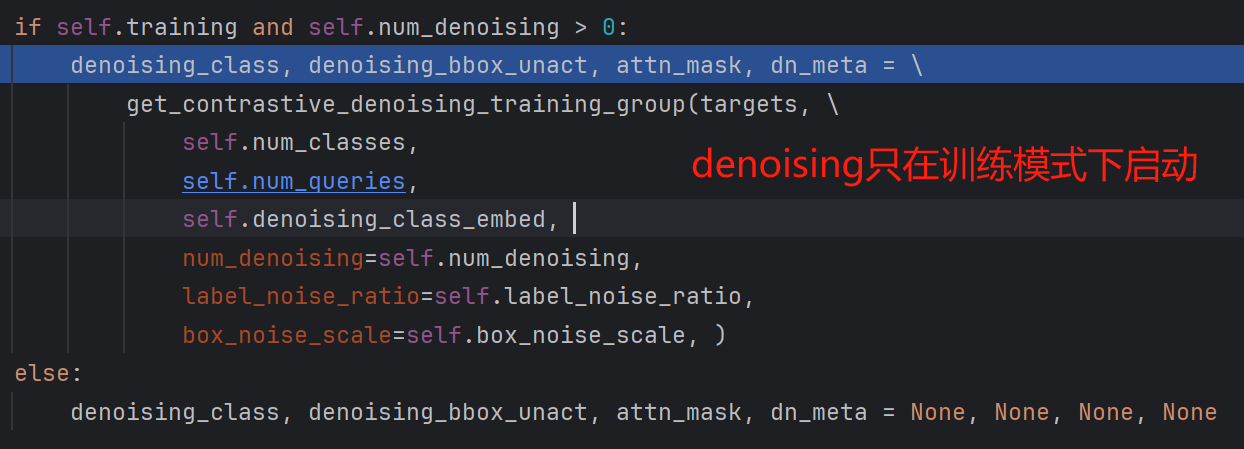
接着便是如何生成噪声查询向量了,该部分代码的实现在denoising.py中。
加噪思路
在讲解这部分代码前,大家可以看一下博主画的这张图,了解一下DeNoising的实现思路

噪声组设计
我们进入denosing.py文件中,首先看一下传入的参数
label_noise_ratio为类别添加噪声的比例,此处设置为0.5,即有一半的类别要改变
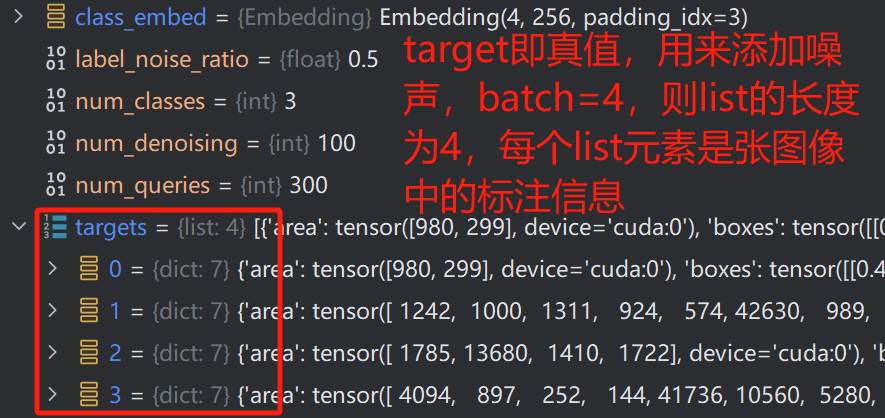
这块代码是十分具有代表性的
首先是确定每张图像中标注样本的个数,保存在num_gts中,随后选出最大的,这个是方便我们在后面划分组时使用,因为num_denoising的熟练为100,是我们确定好的,每个batch(批次)内划分创建噪声,因此,噪声组的数目num_group=num_denoising//max(num_gts)
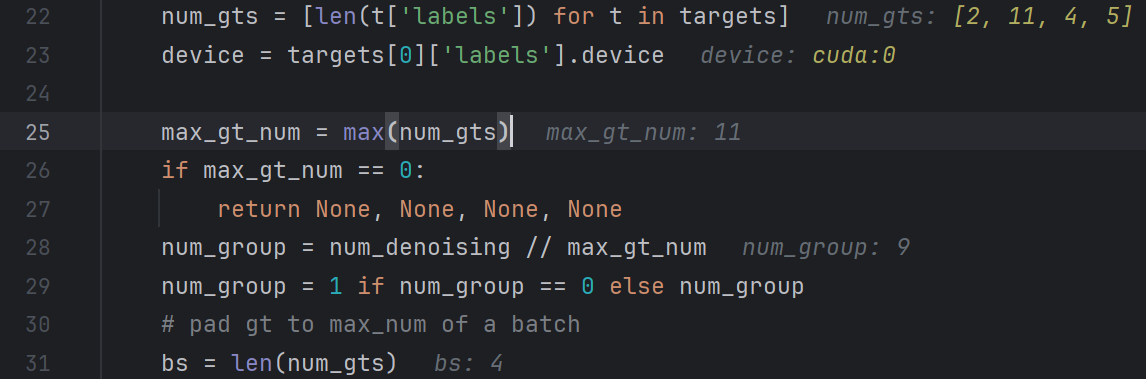
随后,生成对应的输入类别,输入标注框以及真值掩膜,其维度为:
input_query_class:(4,11)第一个3代表batch大小,11为该batch内图像中标注样本的最大值input_query_box:(4,11,4)最后一个四代表w,h,x,yinput_gt_mask:(4,11)真值掩膜
这里类别初始化值 num_class 为3,代表背景

为其赋予对应的值
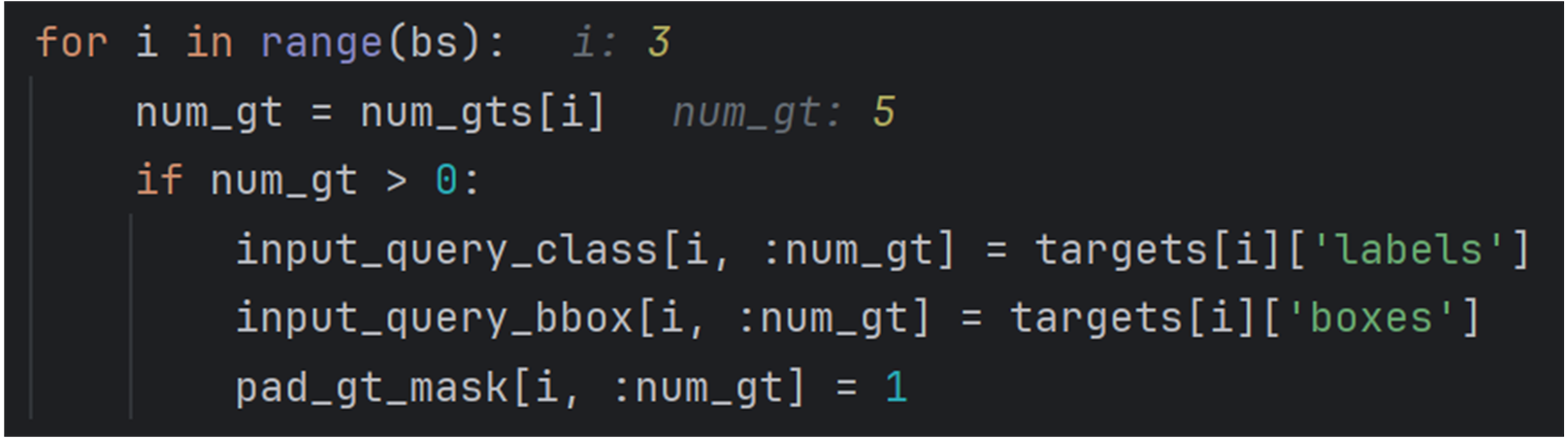
其对应位置会被赋值(绿色),比如input_class则会是对应类别,mask则是True

随后开始创建噪声了,要分正负样本,还要分9组,所以为 2*9,这里用到了一个torch提供的函数:
tile函数(A,reps)
A:输入的数组(array)
reps:数组A重复的次数;可以有两种形式(数字和二维元组)
tile的本意有“铺以瓷砖,铺以瓦”的意思,即将数组视为瓷砖,在一个平面上将此数组平铺开来(数字对应一维,元组对应二维 tuple(纵铺个数,横铺个数)
这里使用的是元组,即纵铺为1,横铺为2*9,这很好理解,其要生成的是很多batch

得到的变量对应维度为:

可以看到,此时input_query_class的值如下,其是按照图像来划分的,第一张图像中只有两个样本,因此每11个数中只有2个不为3,而第二张图像中有11个样本,则没有出现3。
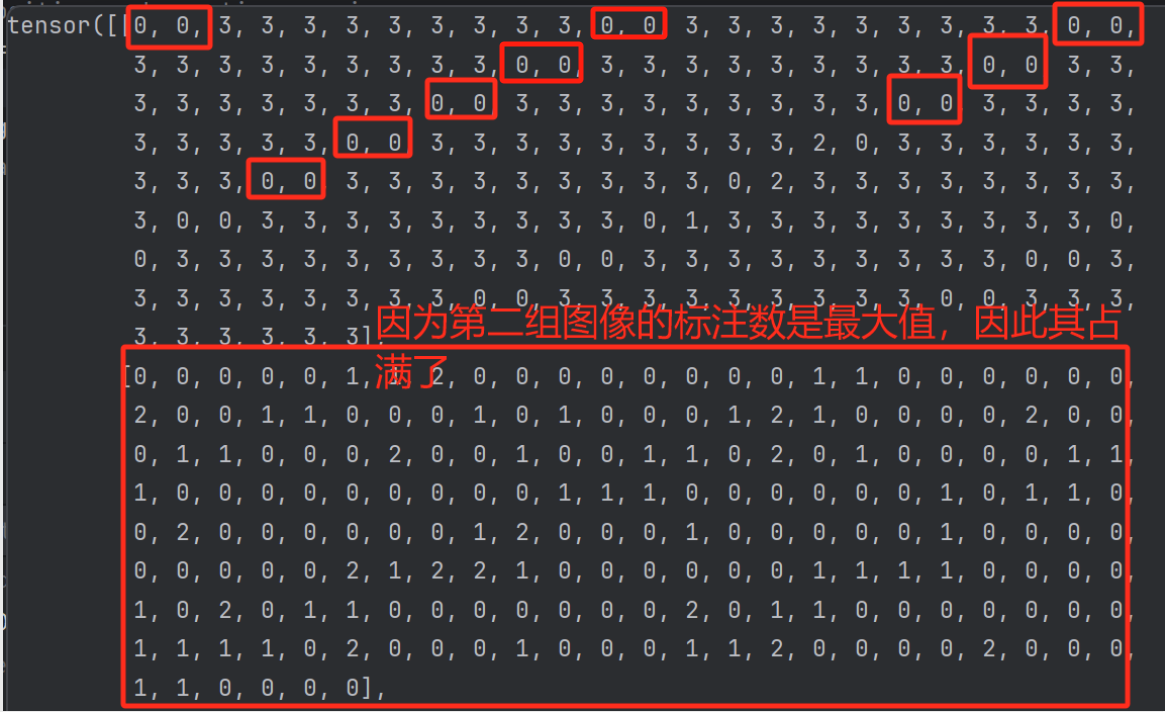
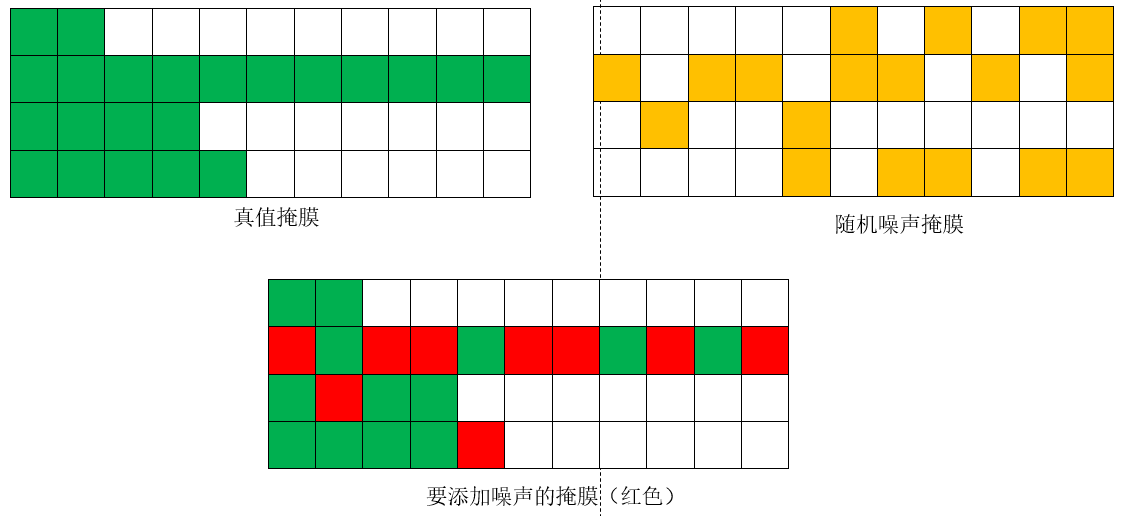
如下图所示(注意,这里我为方便显示,将设置num_group=3,则生成的样本组数为2*3=6)绿色代表有样本,白色代表无样本。

生成对应的正负样本掩膜,划分正负样本,隔一组切换一次正负样本。

生成的掩膜如下,黄色为正样本,红色为负样本,这意味着红色样本的标注框偏移,大小变化会更大,即噪声更大

将正负样本掩膜与标注位置掩膜结合,并获取每个正样本的坐标

dn_positive_idx的值如下:,我们以第一张图片为例,其内有2个标注,则在第一组正样本的坐标为0,1,第二组正样本为22,23,(中间隔了一个负样本组)
添加类别噪声
接下来便是生成类别噪声了,首先是生成噪声比例的掩膜mask,随后根据掩膜生成随机类别new_label,最后判断判断input_query_class对应位置是不是应该添加噪声,最终生成噪声input_query_class。

添加标注框噪声
添加标注框噪声,完整代码如下:

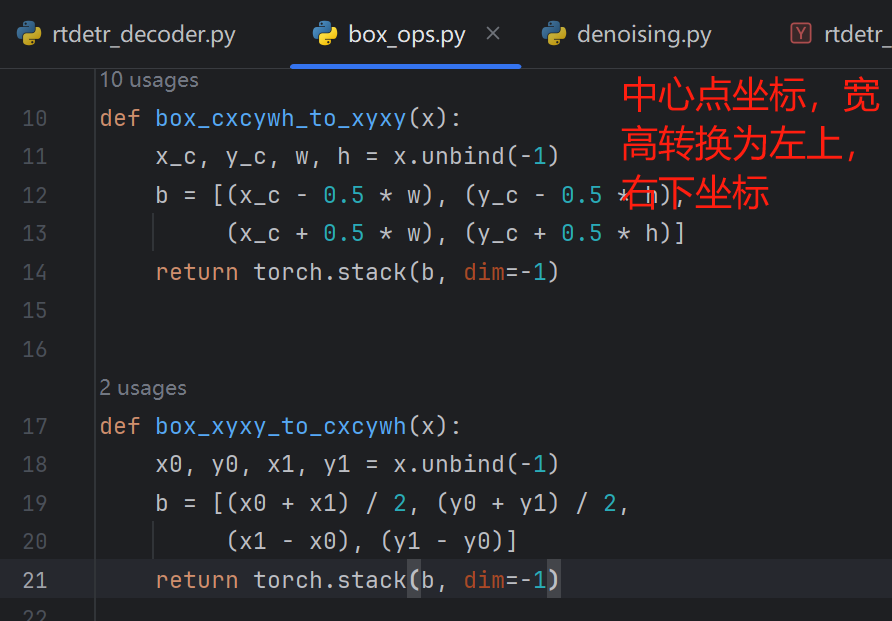
首先进行一个转换,因为原本的标注文件中给出的是中心点坐标与宽高的标注个数,我们先将其转变为左上和右下坐标,方便添加噪声。
diff是根据目标框的宽高获取一个缩放的比例,其维度为torch.Size([4, 198, 4]),其中使用宽高乘以0.5,能够保证将来中心点偏移不会超出原本的标注框。
diff = torch.tile(input_query_bbox[..., 2:] * 0.5, [1, 1, 2]) * box_noise_scale
rand_sign是目标框位移的方向,torch.randint_like(input_query_bbox, 0, 2) * 2.0 - 1.0生成的值在-1到1之间,将其作用在坐标上,即可实现上下作用的平移
随后对正样本以及负样本添加不同程度的噪声区别:
rand_part = (rand_part + 1.0) * negative_gt_mask + rand_part * (1 - negative_gt_mask)
将偏移方向(rand_sign)与缩放程度(diff)相乘可以得到两个坐标点偏移后的位置:
rand_part *= rand_sign
known_bbox += rand_part * diff
最终将偏移后的坐标转换为中心点宽高的形式,并构造查询向量:
input_query_bbox = box_xyxy_to_cxcywh(known_bbox)input_query_bbox = inverse_sigmoid(input_query_bbox)
遮蔽掩膜设计
这是DN-DETR中最精巧的设计了,这个屏蔽掩膜是什么东西呢,其实是为了让真值加噪生成的查询向量与Encoder输入的查询向量有所区分,因为如果Decoder对上述两者不区分的话,虽然加噪组添加了噪声,但相比于Encoder输出的查询向量也是十分强的,这就会导致作弊,因此,加噪组查询向量与原始查询向量需要加以区分,而这个做法便是遮蔽掩膜,其实这个掩膜与前面噪声构造时的很相似。
同时,不同的噪声组之间也是需要相互屏蔽的。
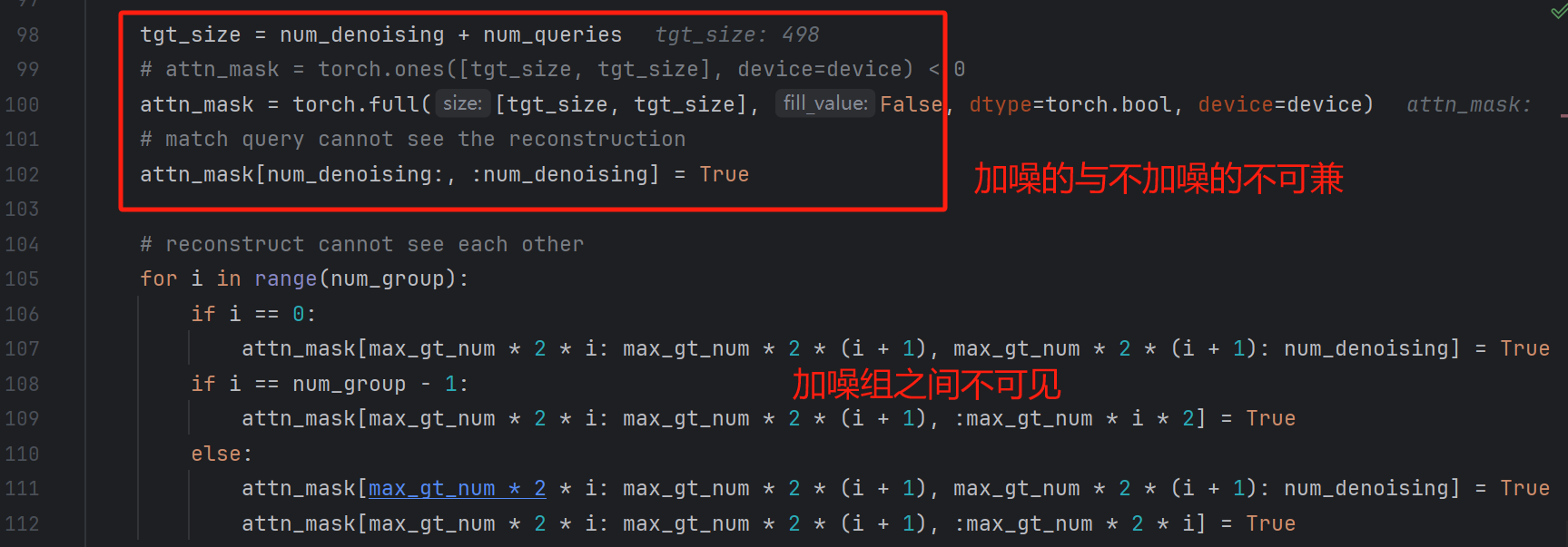
如下图所示,绿色即为True,即为可见的,白色即为不可互相见的。

最终,加噪完成后得到的数据为:
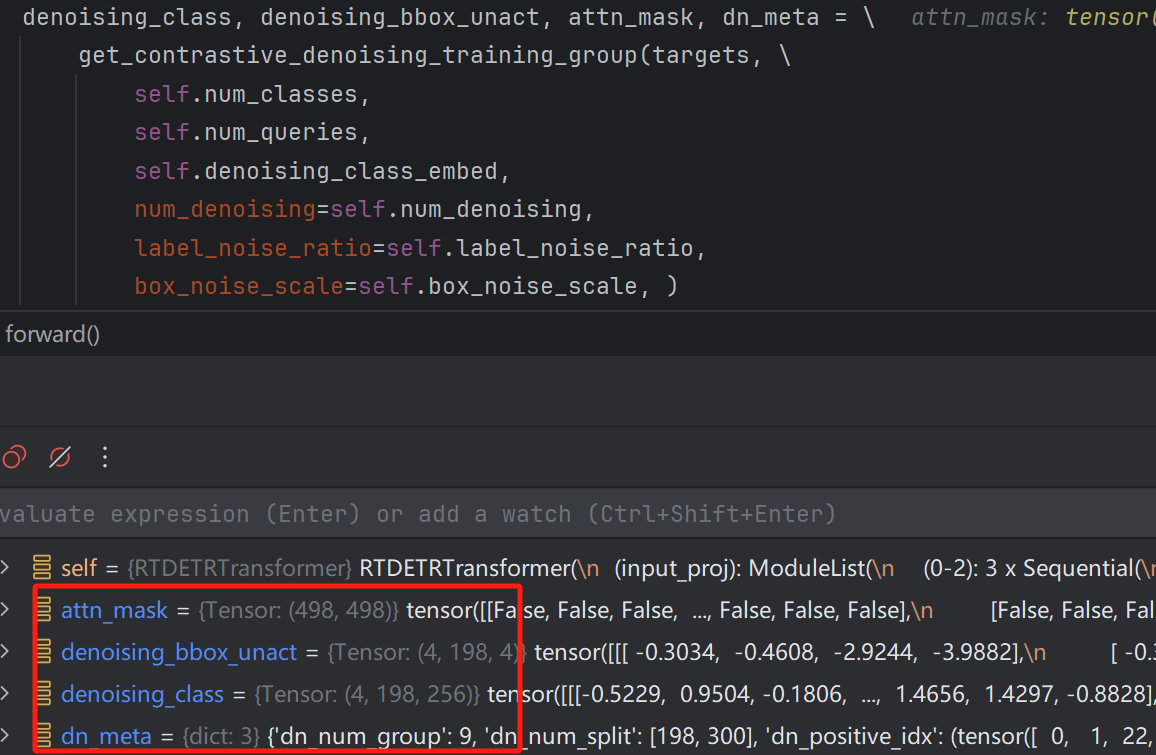

至此,便完成了查询加噪的过程,随后这些查询向量会与Encoder输出的特征向量进行Uncertainty-minimal Query Selection操作,这个我们下一章再讲。
码字不易,给个赞呗。
这篇关于RT-DETR 详解之查询去噪( DeNoise)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





