本文主要是介绍游戏服务器工程实践一:百万级同时在线的全区全服游戏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我应该有资格写这篇文章,因为亲手设计过可以支撑百万级同时在线的全区全服类型的游戏服务器架构。
若干年前我在某公司任职时,参与研发过一款休闲类型的游戏,由 penguin 厂独代。研发的时候,p 厂要求我们的游戏服务器要能支撑百万以上的同时在线,并且要能在 30 分钟内扩容 100 万在线。
在经历了 p 厂好几轮的 TDR (Technical Design Review) 后,游戏稳稳上线了。上线后最高同时在线 (pcu) 到达 30 万左右,虽然没有达到 100 万,但从服务器运行状况来看,完全可以稳稳支撑百万以上的。
做过这种架构之后,再看原神这种大 dau 的开放世界游戏,或者鸣潮这种号称有 3100 万预约的,都不觉得有啥难,反而由于开放世界的游戏偏单机向,服务器负载更小。而像王者荣耀这种 pcu 接近千万级的 moba 也不难,只是个 “开房间类型” 的游戏而已,它的服务器难点主要是在网络同步这一块。
虽然大型互联网应用的规模是远超游戏的,但游戏也有其特殊性,对于延迟特别敏感,并且往往有一部分服务器节点必须是有状态的,所以游戏服务器架构有自己的难点,不能照搬互联网那一套。
本文会介绍这类游戏服务器的架构如何搭建,如何实现水平扩容、高可用、容灾的目标。在具体的部署上,也会提供自建和公有云两种方案。
1. 全区全服
此处提到的全区全服,是指所有玩家在一个大通服里一起游戏,不需要像 mmo 那样,登录后还需要选一个区。
全区全服的游戏,战斗是 “开房间式” 的,匹配够 n 个人就开始一盘游戏,有时候 n 可能为 1,一般的 sns 游戏,io 类游戏,都是全区全服的。
目前世面上几乎所有的全区全服类型的游戏都可以归类为开房间类型的,区别只是房间人数的多少而已。举几个例子:开放世界的,pve 的时候可以理解为单人房间,pvp 的时候是多人房间;棋牌类型的,n个人一桌,这一桌可以定义为一个房间;moba 类型的,像王者,也是几个人一个房间。
btw,棋牌类型的,早期的架构都是房间+桌子,整个游戏分 n 个房间,一个房间分 n 个桌子,一个桌子坐 n 个人。当下已经完全没必要那样设计了,统一抽象成房间就行,更容易做负载均衡。
2. 总体架构
一切的难点都是因为量级太大,当 pcu 到达百万级的时候,水平扩容&负载均衡成为最关键的问题,整个架构的各个组成部分都要设计成可以水平扩容的。除此之外,还要做到高可用、容灾。
2.1 架构图
以下是一个实际可用的服务器架构:

2.2 工作过程
以 “玩家登录并战斗” 为场景,简单说明一下工作过程:
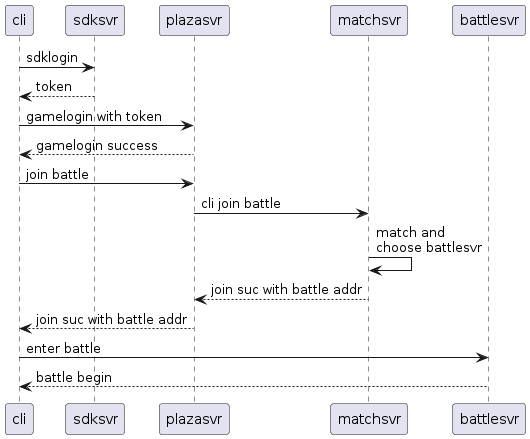
用文字描述就是:
1、客户端通过 sdksvr 完成 sdk 登录授权,获得一个 token;
2、客户端以 token 作为凭证连接上 plazasvr,拉取游戏数据;
3、客户端发送加入战斗请求到 plazasvr,plazasvr 转发给 matchsvr,matchsvr 完成匹配后,从 battlesvr 集群中选择一台 battlesvr 来承担这局战斗;
4、客户端连上分配下来的 battlesvr 进行战斗;
3. 架构说明
以上架构图里展示的,无论是基础的网络负载层、数据层,或是自己开发的游戏服务层,都设计成可以水平扩容的。
下面具体讲下架构的各个组成部分:主要作用,如何做到水平扩容、高可用、容灾。
3.1 网络负载层
这一层主要是为游戏服务层的 sdksvr 集群、plazasvr 集群提供负载均衡的功能。
| 集群 | 功能 | 自建方案 | 公有云方案 |
|---|---|---|---|
| nginx集群 | 为sdksvr提供7层(http)负载均衡 | dns+nginx集群 | LB组件的7层LB功能,比如腾讯云的CLB,阿里云的SLB,华为云的ELB |
| lvs集群 | 为plazasvr提供4层(tcp)负载均衡 | dns+lvs集群 | LB组件的4层LB功能,比如腾讯云的CLB,阿里云的SLB,华为云的ELB |
说明:
- 自建方案,主要是运维的活,采用常规的 高可用 + 容灾方案 即可;
- 自建方案,如果并发连接数特别夸张,需要考虑采用 F5 之类的硬件;
- 公有云方便很多:弹性更大,上限更高,扩容简单,更稳定,费用可能更低;
3.2 游戏服务器层
这一层由我们自己开发的游戏服务器构成。
3.2.1 各服务器的作用
| 服务器 | 作用 |
|---|---|
| sdksvr | 为玩家提供登录、注册、充值、版本更新、停服公告等功能;为外部厂商提供充值回调、推广回调等功能 |
| plazasvr | 为玩家提供游戏接入点;提供除了战斗之外的所有功能; |
| battlesvr | 为玩家提供战斗功能 |
| matchsvr | 为玩家提供战斗匹配;对 battlesvr 进行调度&负载均衡 |
| managesvr | 为运营人员提供后台管理功能;为运营人员提供统计数据查看功能 |
3.2.2 各服务器的特性
| 服务器 | 面向 | 通讯协议 | 水平扩容 | 负载均衡 | 高可用 | 容灾 |
|---|---|---|---|---|---|---|
| sdksvr | 玩家&外部厂商 | http | 支持,无状态web服务器 | 支持,由前置的的nginx集群提供负载均衡 | 支持,冗余部署即可 | 支持,无状态的,宕机不丢数据 |
| plazasvr | 玩家 | tcp + protobuf + 长连接 | 支持,用户可连接任意plazasvr接入游戏 | 支持,由前置的lvs集群提供负载均衡 | 支持,冗余部署即可 | 支持,不cache数据,宕机不丢数据 |
| battlesvr | 玩家 | (udp or tcp) + protobuf + 长连接 | 支持,battle 可在任一个 battlesvr 运行 | 支持,由 matchsvr 进行匹配调度 | 支持,冗余部署即可 | 不支持,cache了战斗状态,宕机会丢失所在svr上的战斗 |
| matchsvr | 无 | 不接受用户连接 | 不支持 | 不支持 | 支持,冗余部署即可,主备模式 | 支持,不cache数据,宕机不丢数据 |
| managesvr | 运营人员 | http | 支持,无状态web服务器 | 支持,但没必要,若需要可部署前置的nginx集群提供负载均衡 | 支持,冗余部署即可 | 支持,无状态的,宕机不丢数据 |
3.2.3 plazasvr 实现细节
避免重复登录
用户可以连接到任一个 plazasvr 来接入游戏,但需要避免同个用户登录到多个 plazasvr,这个可以通过在 redis 上记录用户的登录服来避免重复登录,plazasvr 在处理登录前先从 redis 取数据判断,如果已经在别服登录,则先踢了别服的,再登录本服。
自我保护
plazasvr 由网络层的 lvs 负载均衡的,lvs 并不知道 plazasvr 的实际压力,所以它需要自我保护,设定一个合理的人数上限,这个可以通过压测,获得一个 80% 性能消耗的人数阈值。
plazasvr 内部可以维护一个在线人数计数,超过阈值就拒绝连接,而客户端在被拒绝后,应该立刻重新请求,让 lvs 重新负载到别的空闲 plazasvr 上。
3.2.4 battlesvr 实现细节
是否被直连
延迟敏感型的游戏,battlesvr 应该直接暴露给玩家直连,这样可以最大化的减少延迟。
延迟不敏感的,假如交互的数据量很少,也可以把 battlesvr 隐藏起来,由 plazasvr 中转数据。
tcp or udp
延迟敏感型的游戏,比如 moba,fps 等,应该使用 udp,找一个靠谱的 rudp 实现即可,比如 kcp,可以做到 “以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度” [1]。
对于延迟不敏感的,用 udp 或 tcp 都关系不大。
容灾
battlesvr 算是这套架构里面唯一的有状态服务器了,而有状态服务器基本上做不到容灾的,一个 battlesvr 宕机,那么在它上面运行着的 battle 也是无法恢复的。
如果是战斗场景状态少,并且延迟不敏感的游戏,比如棋牌、卡牌,可以考虑把场景状态实时的写入内存数据库(比如 redis)来实现容灾,但比较少游戏这么做。
3.2.5 matchsvr 实现细节
matchsvr 是匹配服务器,它的功能就是接受玩家的匹配请求,把这些玩家放到一个池子里,然后把匹配到一起的 n 个玩家放到某个 battlesvr 上,让它们连上去战斗。工作的时候,它可以把所有玩家的匹配请求写入内存数据库中,再按一定频率从中取玩家出来做匹配。
匹配的工作量并不大,所以 matchsvr 并不需要做水平扩容,只需要做到高可用+容灾就够了。
高可用方面,可以将它设计为 “主备模式”,冗余部署,依赖 etcd 进行选主,当主宕机的时候,备可以选举成为主,接替工作。
容灾方面,由于 matchsvr 不 cache 数据,数据都放在内存数据库中(redis),所以不会丢数据,只要保证好 redis 的高可用+容灾即可,而这方面 redis 是有成熟的方案的。
3.2.6 其他功能服务器
上面列出的服务器完全可以实现基本的玩法了,在有些情况下,可能需要额外增加一些功能服务器,但要慎重,总原则是尽量不要盲目增加。
很多功能,其实围绕数据库去设计就行了,像好友、公会、聊天这些,完全可以用 数据库 + plazasvr 实现的。
3.3 数据层
这里面包含了 mysql,redis,etcd,数据仓库。
etcd 提供服务发现及选主功能,本身负载不重,没所谓 sharding 问题,只要做好奇数节点部署,做到高可用及容灾就行了。
“数据仓库” 这里范指流水日志的存储及统计的基本设施,流水日志包括登录、注册、充值、游戏行为、财富变化等,依靠这些流水日志可以统计出留存,rto等数据报表,可以做用户画像,使用当下成熟的 log 采集+大数据计算方案即可。除了自研,还可以考虑接入第三方的统计,比如 “数数” 等,可能整体成本会更低。
剩下的 mysql 、redis,最主要解决的是 sharding 问题。
mysql 用于存储游戏的业务数据,也可以用其他数据库替代,比如 Posgresql,mongodb。
redis 用于 1、存储游戏运行时数据,比如防止用户重复登录的登录服记录、匹配战斗的用户池;2、大型排行榜;3、一些展示性的 cache 数据。其中 1 跟 2 是有持久化需求的。
3.3.1 mysql
mysql 要实现 sharding,自建跟公有云都有不同的方案。
有三种方式实现 sharding,按位置不同,分为业务层,中间件,数据源。
业务层,即在代码逻辑上自己根据某些 sharding key 进行 sharding,可以是 range base,也可以 hash,但无论怎么做,耦合都是高的,过去的游戏服务器挺多使用这种方式做 sharding 的,但放到当下,其实没必要,有其他更优的方案。
中间件,即在业务代码与数据库之间增加一层代理,这种方案,业务代码不需要做什么改变,只要指定 sharding key 就行了。
数据源,省去中间件,在数据库这一层直接实现 sharding,或者说水平分表,一些新的分布式数据库如 TiDB 就支持动态 sharding。
中间件方式
自建的话,选择不多,这篇文章《ShardingSphere 5.x 系列【3】分库分表中间件技术选型》[2]提到了 ShardingSphere 这款中间件,可以尝试一下,文章里面也对某Cat 进行了批判,跟我的个人体验完全一致,总之,千万不要使用某 Cat。
公有云的话,选择也不多,华为云有一款 “分布式数据库中间件 DDM” [3],可以尝试一下。
数据源方式
自建的话,目前看,只有 TiDB 是稍微靠谱的。
公有云的话,腾讯云的 TDSQL for Mysql [4]是可以的, p 厂做游戏还是有经验的,之前我司被独代的游戏,用的就是 p 厂改造的 mysql 引擎 tspider,支持透明的分库分表。
mysql以外
可以考虑 MongoDB,它本身就支持 sharding,并且文档化数据库跟游戏对于数据 keyvalue 用法很匹配。
MongoDB 从 4.2 版本开始支持自定义分片键了,游戏一般不需要范围查询,所以用 uid 作为分片键,且基于 Hash 去做 sharding,可以使用数据分布得很均匀,sharding 效果会很好。
总结起来:
| 方案 | 中间件 | 数据源 |
|---|---|---|
| 自建 | ShardingSphere | TiDB or MongoDB |
| 公有云 | 华为云的 DDM | 腾讯云的TDSQL or MongoDB |
3.3.2 redis
在本架构中,redis 是比较重要的,存储服务器运行数据的,是需要做持久化的,需要高可用&容灾。数据规模比较大,所以 sharding 是有必要的。
自建的话,可以使用 redis cluster 来实现 sharding。
公有云的话,可以直接使用它们提供的集群版本,基本上各大公有云都有对应实现的,甚至有自研的兼容 redis 协议的性能更高的内存数据库,都是可以使用的,问题不大。
但关于 redis 的数据可靠性,有一点是需要清楚的,就是 redis 即使开了 aof,也不一定能保证在 redis 宕机的时候不丢数据,因为为了性能考虑,aof 通常也是用每秒 fsync 的方式的,所以如果宕机,可能会有 1 秒的数据丢失的。
大排行榜
现在应该比较少策划会做全服排行榜的了,但如果做的话,有一些是需要考虑的。
假设周活几千万人,那么周排行榜也差不多就要几千万人排行,这么巨的数据,是不应该放到集群版的 redis,需要放到单独的 redis 中,并且在删除排行榜的时候,不能够直接用 del 命令,会卡很久的,应该在代码逻辑里循环的分批删除,直到删完。
4. 设计细节
4.1 自动重连&失败重试
服务器虽然运行在内网,但内网之间的连接也可能偶尔出现中断的,服务器一定要能自动重连。
另外,服务器与数据库的连接,也可能偶尔出现中断的,服务器不单要能正常的重连 db,还要做数据写入的失败重试,比如有时候需要在线对数据库做扩容处理,往往会造成1分钟内的读写失败。所以一定要做失败重试,并且要设定合理的重试间隔。
4.2 热更新
无论用什么语言,至少做到配置热更新。
如果用 lua 写逻辑的,至少做到可以热修复 bug,虽然 lua 有闭包,比较难以更新,但已经有办法的,可以使用 debug 库重新绑定 upvalue 的方式生成新闭包。
以上目的都是做到更好的运营,减少服务器重启对玩家的影响。
4.3 能拉就不要推
客户端与服务端的交互,能拉数据的就不要推,否则以后优化会很麻烦。尽量让客户端发 request 来获取数据,不要让服务端主动 push。这样做的好处是,主动权放到客户端那边,它可以根据不同的运行环境做不同的适配,调整拉取数据的时机,或者有选择性的拉取自己需要的数据,这样更灵活。
比如同时有 app 端和 h5 端,而 h5 端要轻量化,有些数据是不需要的,那么它可以自己选择拉或不拉一些数据。
4.4 docker 化
对于架构中无状态的部分,完全可以将它 docker 化,这样在扩容,缩容的时候都更敏捷。
5. 性能与故障排查
5.1 压力测试
无论怎么强调都不过分,只有全面的压力测试,才能确保上线稳定,要尽可能模拟足够多的场景,并且在这个阶段,就要把服务器集群接入 prometheus 之类的,看看各方面的指标是否正常,log 也要接入 log 归档服务,自动识别出 log 报错。
5.2 监控
上线前,就要把整个服务器集群都成功的接入 prometheus 之类的 metrics 工具,除了常规的硬件指标:cpu、内存、硬盘、网络,还有业务相关的指标,比如数据相关的收包量、发包量、广播量,各个服的在线人数,战斗人数,战斗个数,这些都要精确到各个具体的进程上,既要能看大盘,又要能看具体个服。
做好性能监控,是一个服务端主程的基本修养。它能带来几个基本好处:
-
发现问题,很多东西是测试不出来的,线上才会出问题,指标可以清楚告诉我们哪里运行不正常了。
-
扩容参考,运营经常会导量,做活动,作为主程,你就要评估,撑不撑得住,要不要提前扩容。
-
优化参考,无论做什么优化,都要基于数据,不要空想,不要纸上谈兵。
5.3 log
log 对于排查错误,提早发现错误太重要了。对于线上运营的游戏,有几个方面要做好的:
-
预防问题,要在问题恶化前提前发现,要能在海量 log 中发现一行毫不起眼的报错,无论是业务主动输出,还是被动输出的 stack 报错。
-
快速诊断,出现问题,要跟时间赛跑,第一时间通过 log 诊断到病根,以最快的速度解决。
另外,log 也可以拿来统计得到一些指标性的数据,比如像 nginx 的 access log,可以拿来统计接口的调用比例。
工程化部署
自建会比较麻烦,需要搭建一套采集+存储+查询的 log 系统,开源的可用 ELK 三件套,即 ElasticSearch、Logstash、Kibana。
如果用公有云,会方便很多,腾讯云有日志服务 CLS,阿里云有日志服务 SLS,华为云有云日志服务 LTS。这几家的日志服务使用起来都是大同小异的,不会存在被绑定的问题。使用起来,体验都很丝滑,接入很简单,支持日志目录的模糊匹配,log 告警都支持正则筛选。
6. 糟糕的设计
下面列举的都是一些(我认为)糟糕的设计。
6.1 “数据库服务器”
经常看到一些文章里面,画的游戏服务器架构图里面会有 dbsvr 这种东西,它的作用大致是作为 gamesvr 和 db 之间的媒介:gamesvr -> dbsvr -> db 。
其实这是很没必要的做法,dbsvr 的存在只会增加单点故障的风险,直接 gamesvr -> db 就好了。
6.2 用 redis cache 玩家核心数据
这是一个愚蠢的设计(我犯过这个错)。大致做法就是用 redis 完全 cache 玩家数据,读的时候从 redis 先读,读不到就从 mysql 读并写入 redis;写的时候就双写 redis 和 mysql。
这种做法的初衷就是为了应对读多写少,但副作用太大了,挺容易就造成数据不一致的,特别是涉及玩家财富的东西,不一致是很可怕的。
我的建议是,redis 不要拿来 cache 玩家数据,玩家数据应该只存在 mysql 这类数据库中。
6.3 微服务化
实际上,上面的架构已经算是某种程度的微服务化了,只不过粒度很大。游戏服务器一来有状态,二来对于延迟要求特别高,互联网的那套所谓微服务化并不适合套在这里。
7. 参考
[1] skywind3000. kcp. Available at https://github.com/skywind3000/kcp.
[2] 云烟成雨TD. ShardingSphere 5.x 系列【3】分库分表中间件技术选型. Available at https://blog.csdn.net/qq_43437874/article/details/135850829, 2024-02-19.
[3] 华为云. 分布式数据库中间件 DDM. Available at https://www.huaweicloud.com/product/ddm.html.
[4] 腾讯云. TDSQL 水平分表. Available at https://cloud.tencent.com/document/product/557/10521.
这篇关于游戏服务器工程实践一:百万级同时在线的全区全服游戏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




