本文主要是介绍OSPF LSA头部详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LSA概述
LSA是OSPF的本质 , 对于网工来说能否完成OSPF的排错就是基于OSPF的LSDB掌握程度 .
其中1/2类LAS是负责区域内部的 类似于设备的直连路由 . 加上对端的设备信息
3 类LSA是区域间的 指的是Area0和其他Area的区域间关系 , 设计多区域的初衷就是避免大型OSPF环境LSA太多的问题 .
4/5类LSA放到一起 , 如果OSPF需要进行引入的操作 , 不管是其他协议的数据库比如is-is , bgp 还是引入静态路由和直连路由 , 进行引入操作的设备就成为了ASBR , 但是其他区域并不知道ASBR的网络位置(只能知道ASBR的Router-id) , 此时就需要4类lsa指明去往ASBR区域的ABR的路由
LSA头部

在OSPFv2的背景下 , 我们一般只关注12/3/57类LSA , 所有的LSA都有相同的报文头。
Optinons / Length
-
Length 即整个LSA的长度,包含了LSA的头部
-
Options 能力可选项通过几个置位来体现

这里存在2个复杂知识点 P置位和DN置位 , 我后续会单独出2篇文章来详细说明 , 简单来说P置位就是NSSA区域的ABR收到路由后通过P置位来判断是否需要把7类lsa转换成5类 , DN置位则存在OSPF VPN场景下多实例CE发布OSPF路由时携带 , 用于防止OSPF路由回传的场景
LS type / Link State ID / Advertising Router
在ospf的lsa头部中 , Type LinkState ID AdvRouter 共同用于标识是否为唯一lsa (简单理解只要3个字段都一样 , 设备就会认为是一条LSA , 其他数值发生变化时数据库不会新增 , 而是对该LSA做更新)
其中LS type和advrouter含义明确, 但是LinkState ID会跟随Lsa的类型而选用不同的取值
-
Advertising Router 产生此LSA的路由器的Router ID
-
LS type 代表LSA头部后面内容的lsa类型
-
Type1:Router-LSA。每一台OSPF都会产生唯一一条,域内泛洪。
-
Type2:Network-LSA。每个MA网络中的DR设备产生一条,域内泛洪。
-
Type3:Network-summary-LSA。由ABR产生 , 发送本区域内的路由信息给其他区域。
-
Type4:ASBR-summary-LSA。由ABR产生 , 通告给除ASBR所在区域的其他区域。
-
Type5:AS-External-LSA。由ASBR产生,发送范围整个OSPF自治系统,通告其他自治系统的路由信息。
-
Type7:NSSA-LSA。由NSSA区域内的ASBR产生,发送范围仅仅是NSSA区域。
-
-
Link State ID 是个人认为LSA中最难记忆的一个字段
他结合了LS type , 不同的组合代表着不同的含义。
Type1中Link State ID: 生成这条LSA的路由器的Router ID。
Type2中Link State ID: 描述网段上DR的端口IP地址。
Type3中Link State ID: 描述区域内网段。
Type4中Link State ID: ASBR的Route ID 。
Type5中Link State ID: 外部路由的网段。
Type7中Link State ID: 外部路由的网段。
简单总结一下 1/4 类LSA的Link State ID的值是Router ID , 3/5/7类LSA的Link State ID的值代表网段信息 , 2类则是DR的接口IP
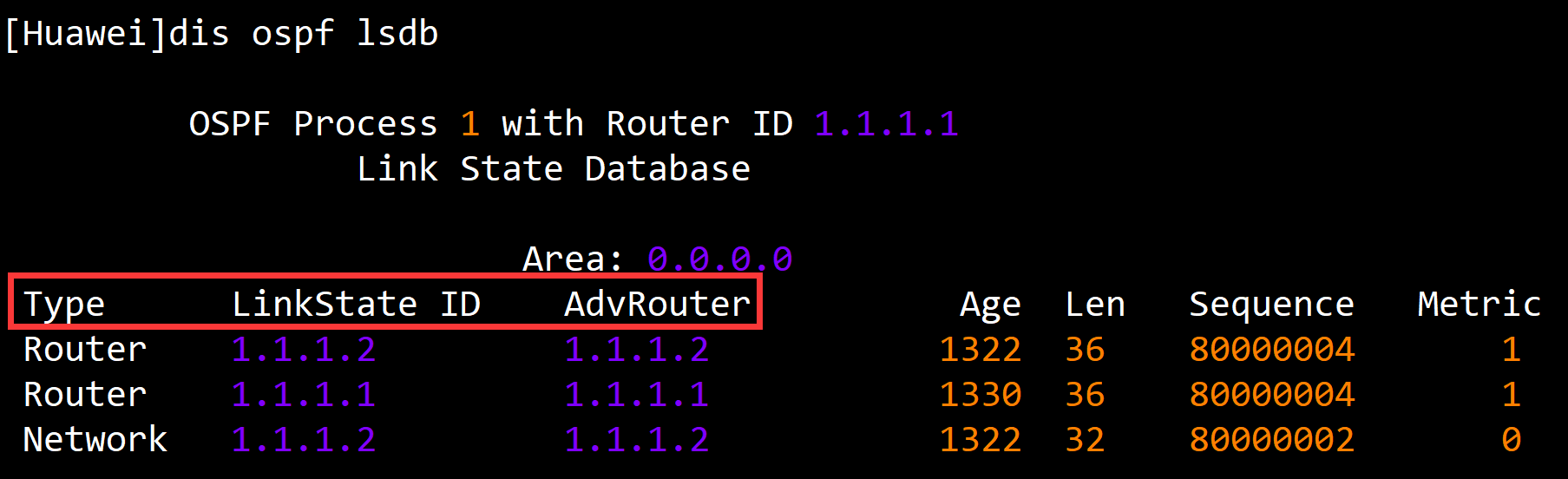
比如1类LSA的Link State ID就是route id , 所以1类LSA的 Link State ID 永远和 AdvRouter相同
2类LSA的看上去和1类LSA相同 , 但是含义完全是不一样的 , Link State ID代表了这个网段的DR接口IP地址是1.1.1.2 . 那为什么 AdvRouter也是1.1.1.2呢 , 因为2类LSA一定是DR产生的 , 可见DR的Route-id并没有进行手动的配置 , 设备自动选用了其IP地址最大的接口IP作为Router-ID
LS age / LS sequence number / LS checksum
LSA头部最后的三条字段 , 他们共同作用和上面的三兄弟类似 , 是用来比较一条LSA的新旧的 .
需要比较新旧有一个隐含的信息 , 那就是这2条进行比较的LSA的(LS type / Link State ID / Advertising Router) 信息一定是一样的 , 这个情况下才会进行比较 .
-
LS age LSA生产后的时间(秒) , 越小代表越新 , 无论是在传输途中还是LSDB中其值都在不断增涨
age有2个关键的时间点需要记忆1800秒和3600秒(华为) , 而且LSA在从接口发送出去时LSA age会+1 , 代表链路的延迟
-
LS sequence number LSA的序列号 , 越大代表越新 , LSA每次更新序列号的值就会+1
-
LS checksum LSA全部信息的校验和
来详细聊一下LS age , 之前提到的2个关键时间点 1800和3600
在华为的设计中当一条LSA age达到1800秒时 , 这个LSA的始发者就会去更新这条LSA , 在学习OSPF时你肯定会见过这段话 (触发式更新以较低的频率每30分钟发送定期更新,被称为链路状态泛洪) , OSFP的30分钟定期泛洪其实本质上就是指的LSA age 达到1800秒的时候 , 第二个关键时间3600 , 在RFC的设计中当一个LSA的age达到3600秒时这条LSA就要被删除 .
通过age3600秒就需要被删除这个设定可以得知
-
OSPF是怎么撤销路由的? 3/5/7类LSA的始发者通过发布一条一模一样 但LS age=3600的LSA传递给其他OSPF设备 , 以此实现3/5/6类LSA的撤销 , 其他设备收到一条LS Age设置为Max Age的LSA,则从LSDB中删除此LSA(如果LSDB中存在此LSA). 1/2类LSA的撤销也是发送新的LSA实现 , 但是并不是通过age=3600 , 而是发一个新的 且把需要撤销的信息删除 , 剩余的内容发送给其他设备 , 其他设备根据LSA的序列号得知此LSA更新 , 覆盖旧的LSA , 以此来实现1/2类LSA的撤销.
所以正常情况下OSPF的LSDB数据库中不可能存在age >1800的LSA , 如果存在则说明这个LSA的始发者设备出现了问题 , ospf的邻居正常情况下是未收到hello包40s就会邻居关系就会down , 但是lsdb中的lsa并不会随之删除 , 举例A设备和邻居B的ospf peer down了 , 但A不会在本设备的lsdb删除邻居B发布的las条目 , 直到超时 , 也可以手动reset ospf [ process-id ] counters maxage-lsa命令,将达到老化时间的Router LSA的计数器清零。
关于LS sequence number的细节
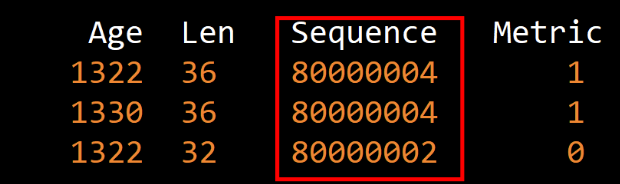
他是一个32位整数 , 数值范围0x 80000000 --> 0x 7FFFFFFF , 为什么最小值会大于最大值呢? 首先他是一个16进制的数 , 8我们可以看做是5 , 这个为了更好的表示16进制且不占用第33位字符 所以设计了一个巧妙的做法 , 80000000其实是一个负值 , 我们可以看做-50 --> 50的过程
序列号什么时候才会+1 ?
除了我之前提到了1800s 会自动更新+1之外 , 正常做更新操作都会触发这个序列号+1 , 只有LSA的始发者才有权利更新这个序列号 , 其他设备收到后先比较(LS type / Link State ID / Advertising Router)这个组合 , 判断是否为同一LSA , 如果相同则选择序列号更大的LSA加入到LSDB , 这就是OSPF的底层工作机制
如果数据库中的LSA比收到更优呢?
一般来说此场景出现在链路延迟高或者故障中 , 当一台设备发现自身存在更优LSA的情况下 , 这台设备会发送最新的LSA给消息来源者
LSA新旧的比较
最后通过一张图片来展示一下LSA的比较过程
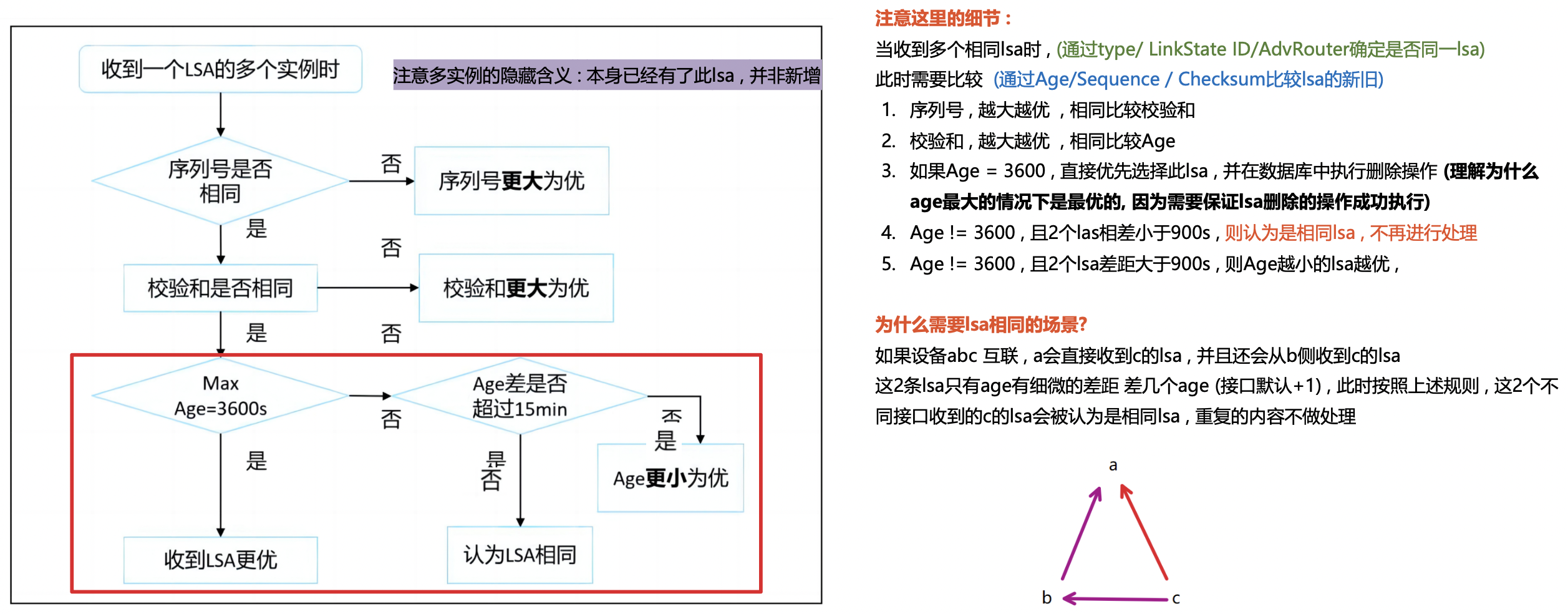
有一个小细节 , age=3600是优先判断的 , 因为需要保障执行撤销LSA的动作 , 其次如果age差小于900秒 , 则认为这是2条一样的LSA , 不再进行处理
这篇关于OSPF LSA头部详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


