本文主要是介绍Python第二语言(五、Python文件相关操作),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 文件编码的概念
2. 文件的读取操作
2.1 什么是文件
2.2 open()打开函数
2.3 mode常用的三种基础访问模式
2.4 文件操作及案例
3. 文件的写入操作及刷新文件:write与flush
4. 文件的追加操作
5. 文件操作的综合案例(文件备份操作)
1. 文件编码的概念
常见:UTF-8、GBK、Big5编码等等..与Java一样,所有的计算机编码概念都一样,类型不一样。
2. 文件的读取操作
2.1 什么是文件
内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U盘等设备。为了便于数据的管理和检索,引入了“文件”的概念。
一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中的数据。一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别。
2.2 open()打开函数
(使用Python操作文件就需要用到open函数)
# open()打开函数
# open(name, mode, encoding)
# name: 是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
# mode: 设置打开文件的模式(访问模式):只读\写入\追加等
# encoding: 编码格式(推荐UTF-8) 在这里需要用关键字参数直接指定,因为encoding不是位置参数
f = open("pythonLearn", 'r', encoding="UTF-8")
# f是`open`函数的文件对象
print(f.read()) # 读取文件内容
2.3 mode常用的三种基础访问模式
(mode是open函数的第二个参数,其作用是对文件的操作方式)
open函数中的'w'操作,当前文件打开后,既第一次打开文件的时候会清空文件,但是打开文件后,并没有关闭他,且不断的往里面写入数据,因此可以做到一个备份文件操作。
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后,如果该文件不存在,创建新文件进行写入。 |
2.4 文件操作及案例
- 当前f的代表open读取文件后的赋值
![]()
1. 文件读取操作( 文件对象.read() || 文件对象.readlines() )
- read() || readlines() 使用注意:当前文件被两个read同时读取的时候,第二个read会从第一个read读取的结尾处继续读取。
- readlines() || read() 使用注意:当次文件在之前被读取了之后,使用readlines再次读取文件 虽然方法不一样,但是文件还是被read方法所影响,相当于读取文件的时候会有一个指针,read读取完后指针指向哪个点,剩余读取文件的方法就会继续从当前指针继续读写。
1.1 文件对象.read()方法:
一个文件对象在read时只会读取一次,如果先执行了f.read()方法后,后面的read()读取不会再读取到内容;
f = open("pythonLearn", 'r', encoding="UTF-8")
print(f.read()) # 如果没有传入num, 就会表示读取文件中所有的数据
# print(f.read(4)) # 读取文件内容,可以加上: 文件对象.read(num), num表示读取文件的数据长度(单位是字节)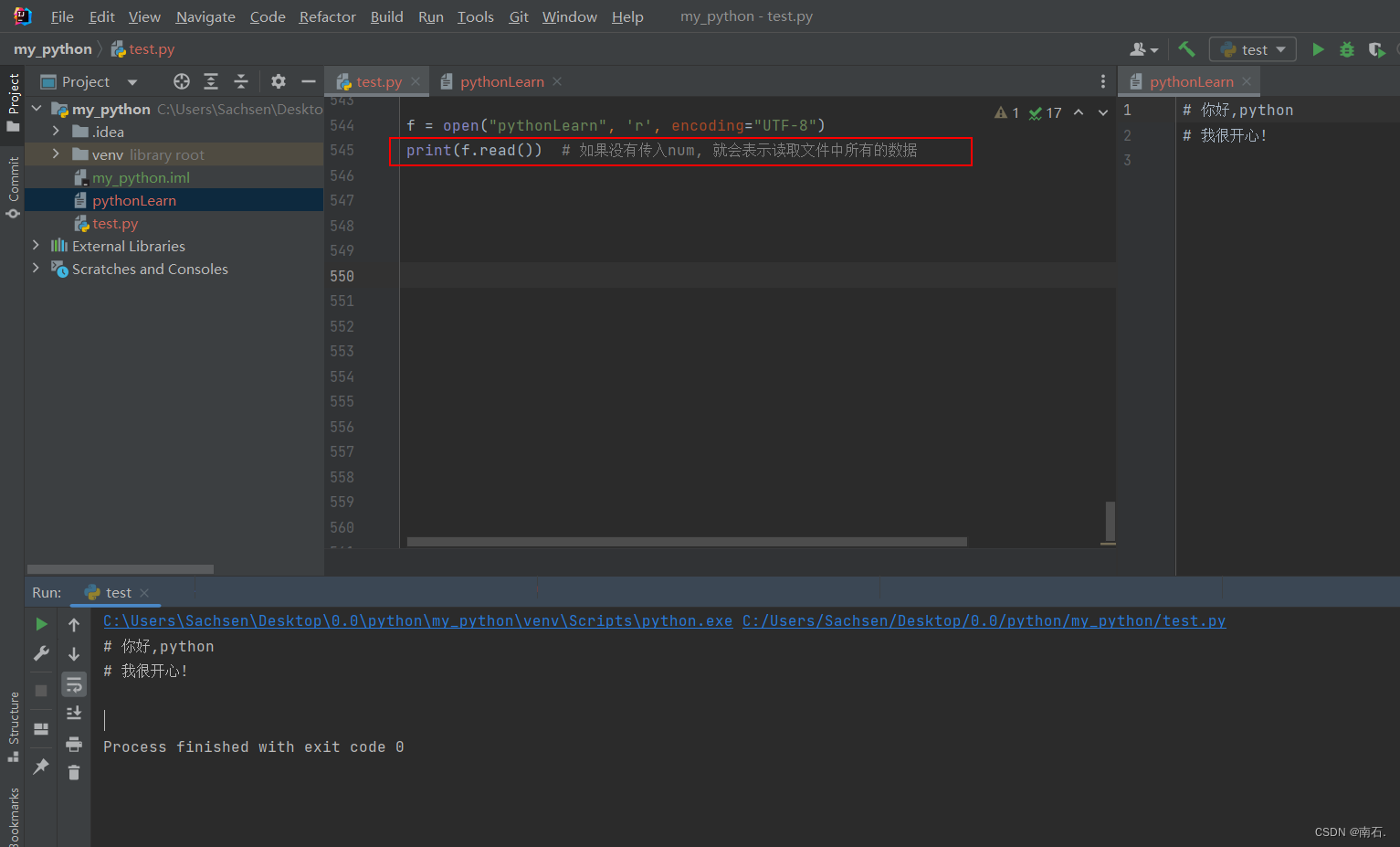
1.2 文件对象.readlines()方法:
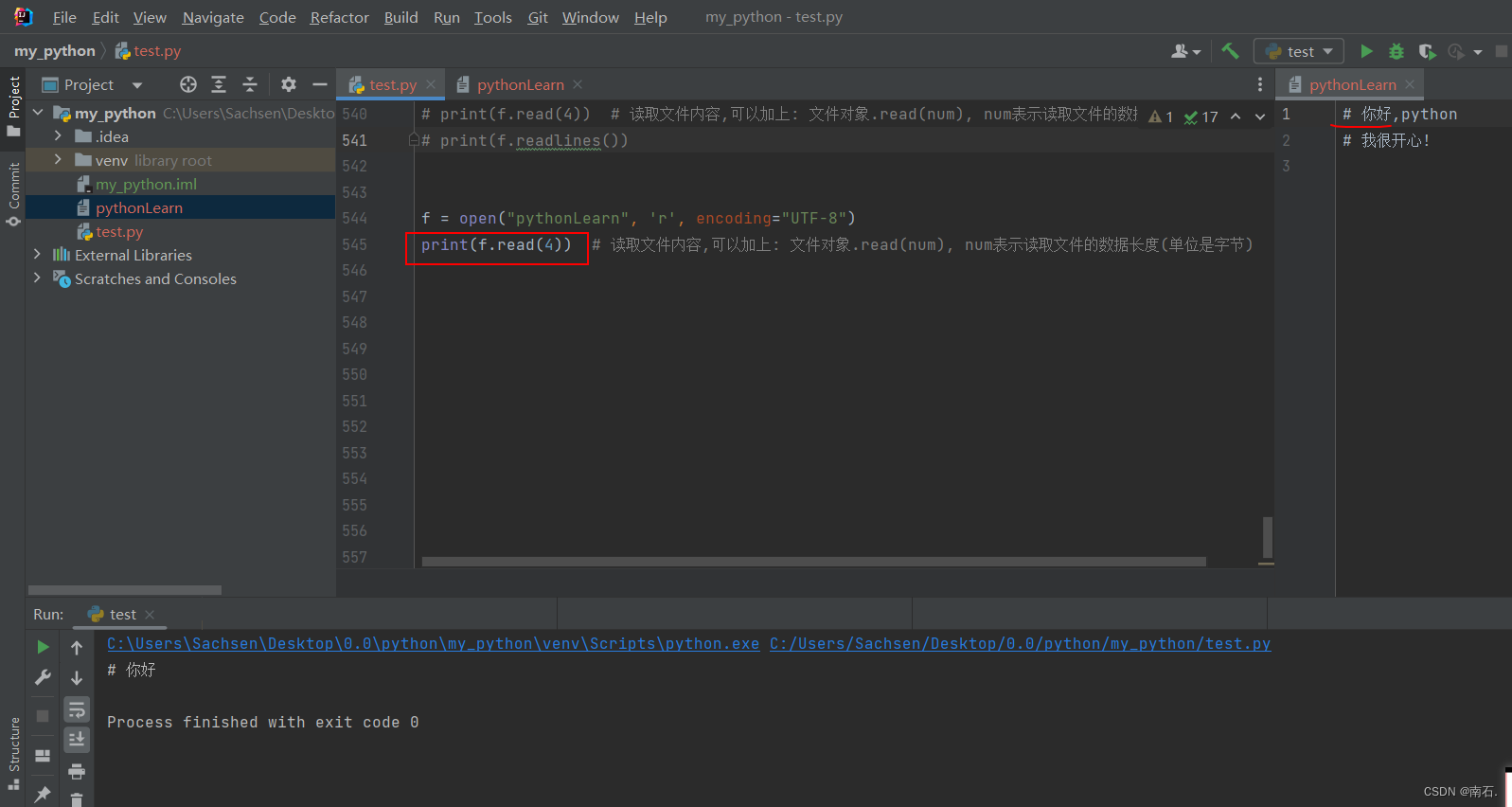
f = open("pythonLearn", 'r', encoding="UTF-8")
# 可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
print(f.readlines())f.close() # 关闭文件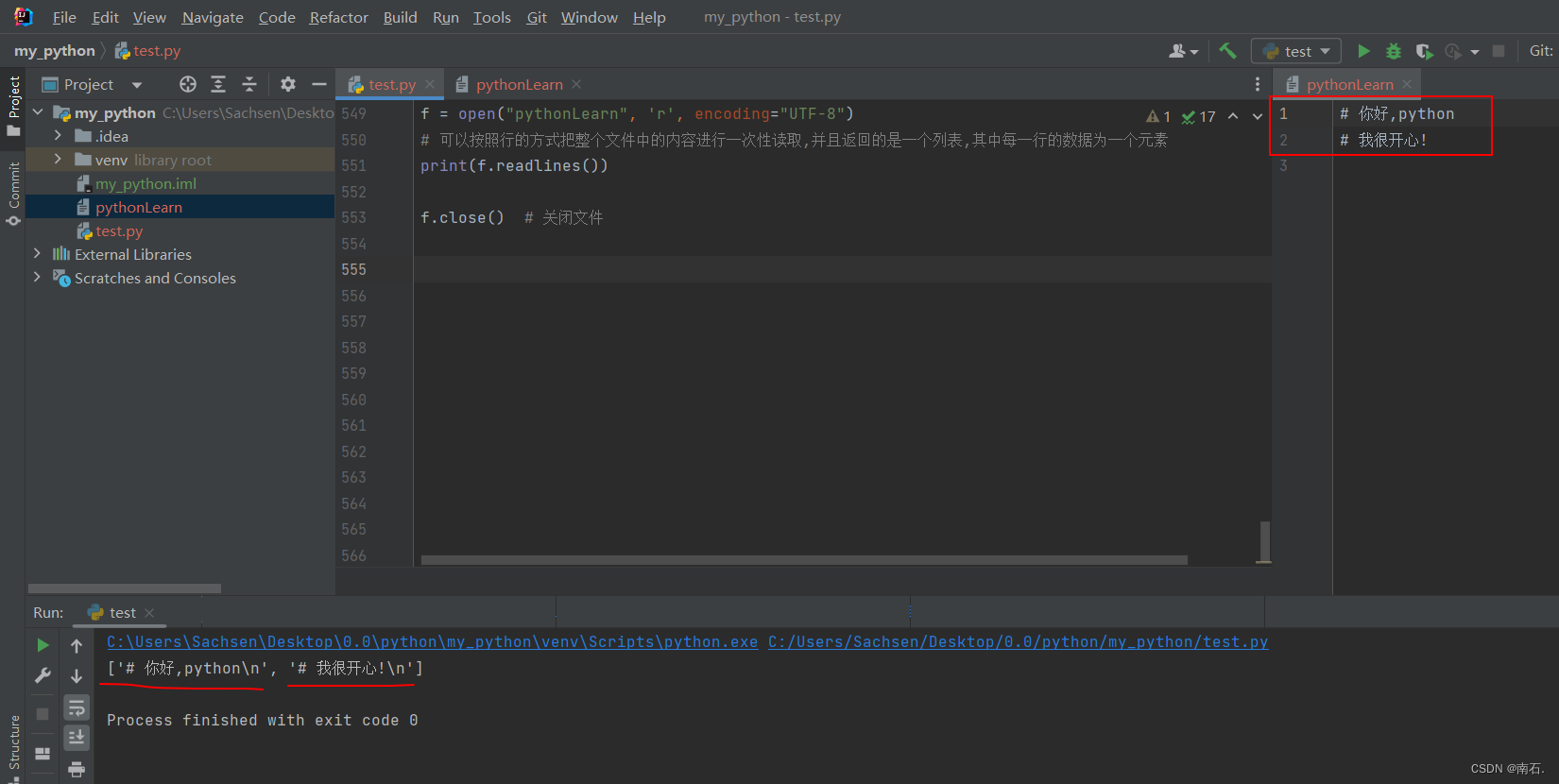
2. 文件读取操作(文件对象.readline())
它会一行一行读取数据;
f = open("pythonLearn", 'r', encoding="UTF-8")print(f"第一行数据:{f.readline()}")
print(f"第二行数据:{f.readline()}")
3. 文件的读取操作(for循环)
f = open("pythonLearn", 'r', encoding="UTF-8")for line in f:print(f"文件的行数据是:{line}") # 每一个line临时变量,记录了文件的一行数据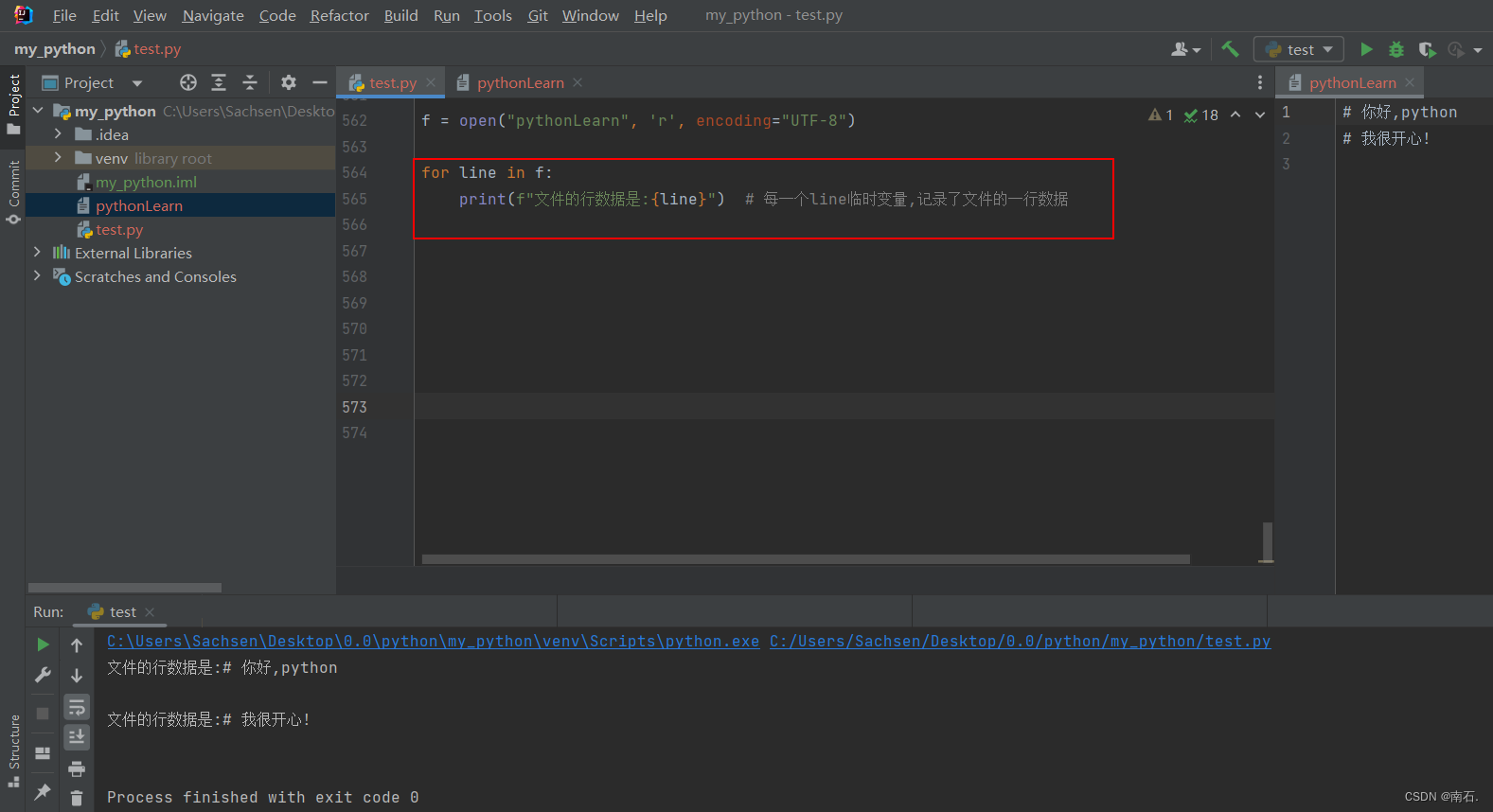
4. close关闭文件(当前文件读取完毕后都需要关闭次文件,不然次文件一直会被该程序占用)
f = open("pythonLearn", 'r', encoding="UTF-8")
f.close() # 关闭文件对象,关闭对文件的占用,如果不关闭就代表整个文件一直被python占用5. with open语法(文件操作后自动关闭)
with open("pythonLearn", 'r', encoding="UTF-8") as f:print(f.readlines()) # 在with open语句块中对文件进行操作,它会自动关闭close文件,避免遗忘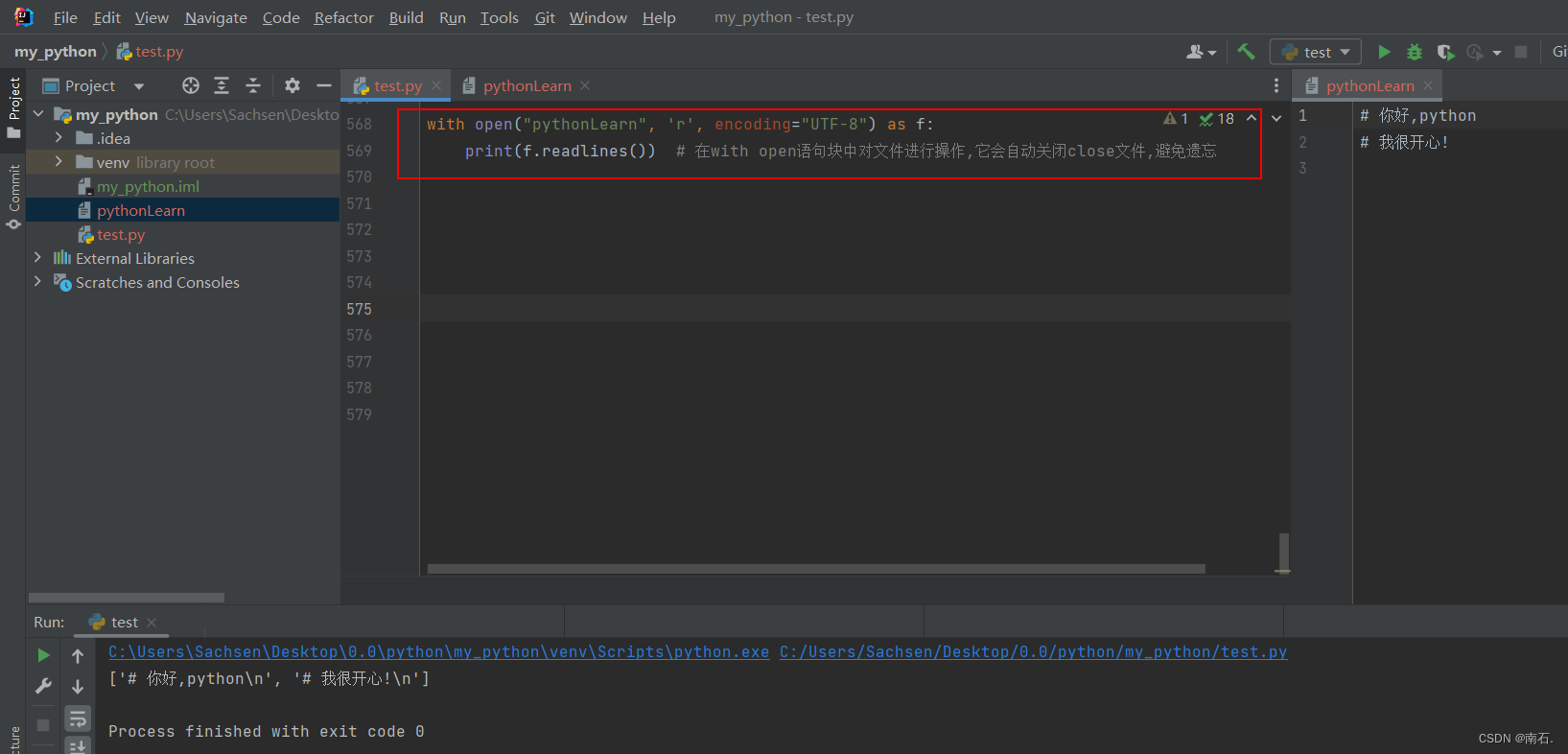
6. 读取文件中一个单词出现的次数案例
6.1 使用count对字符串的指定单词计数:
f = open("pythonLearn", 'r', encoding="UTF-8")# 方式1:读取全部内容,通过count方法统计python单词数量
count = f.read().count("python")
print(f"python在文件中出现了:{count}次")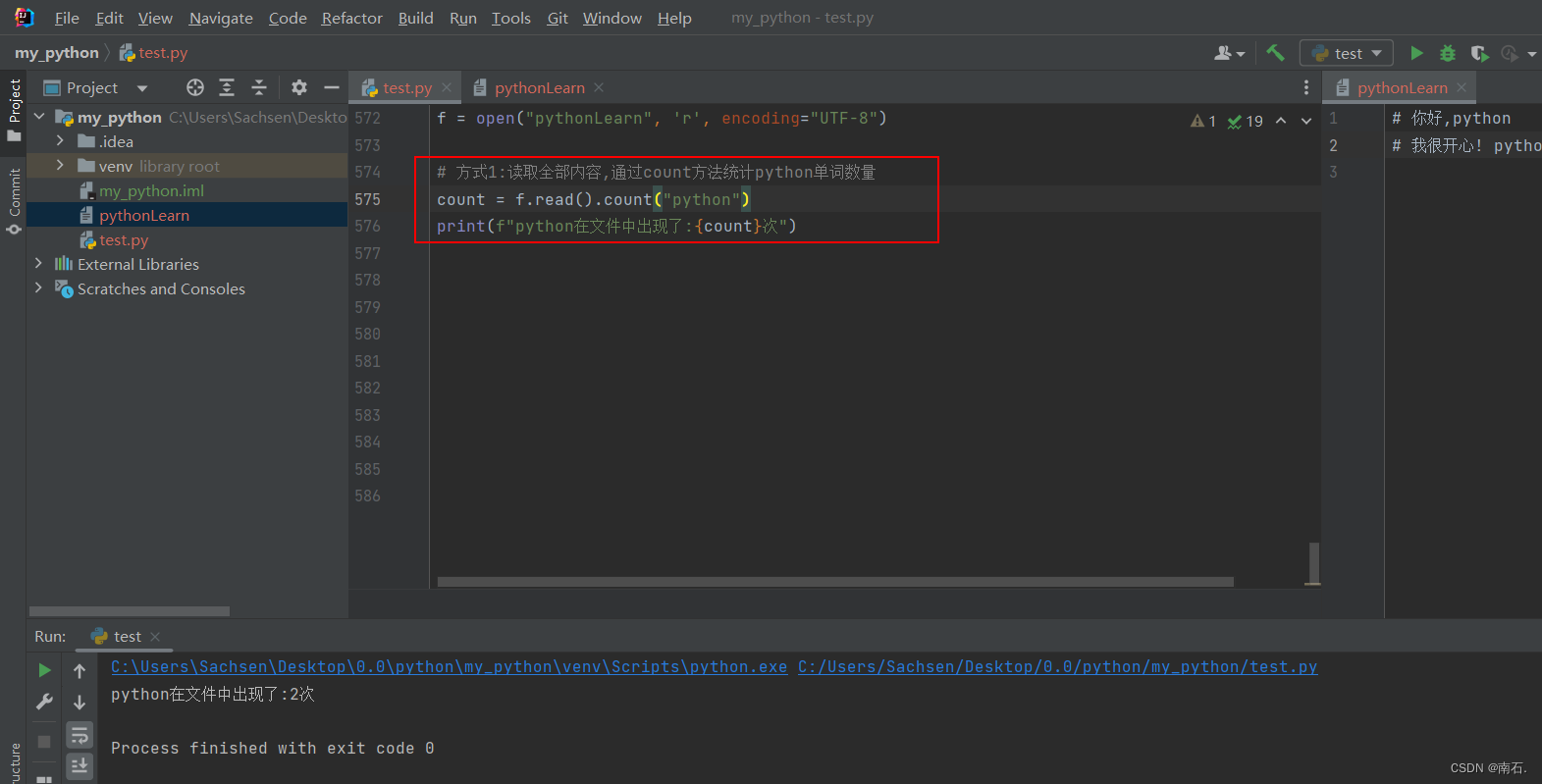
6.2 使用for循环:
f = open("pythonLearn", 'r', encoding="UTF-8")
count = 0 # 计数
for line in f:line = line.strip() # 去除开头和结尾的空格以及换行符words = line.split(",")for word in words:if word == "python":count += 1
print(f"python出现的次数是:{count}")
f.close()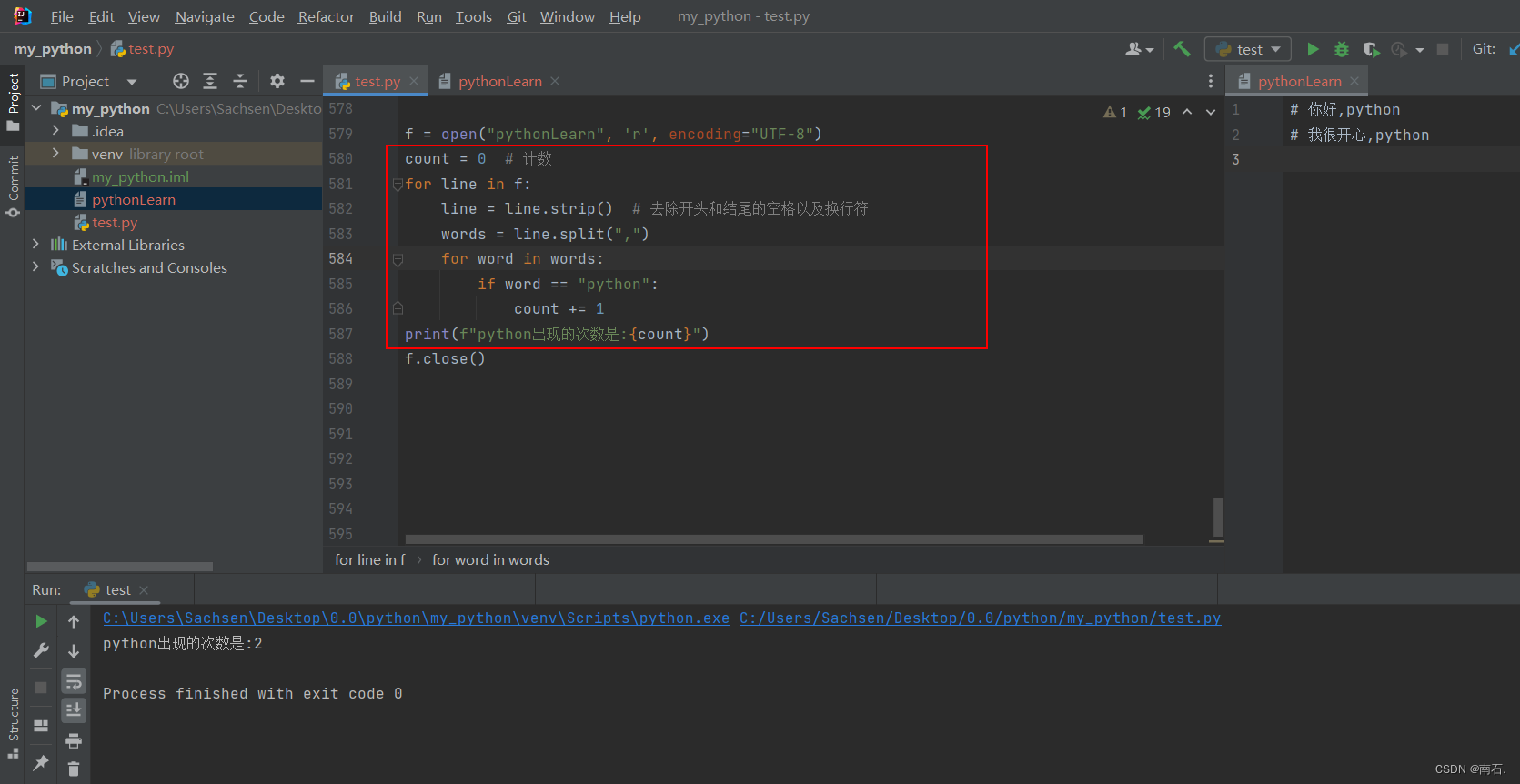
3. 文件的写入操作及刷新文件:write与flush
- write与flush需要一起使用,因为此写入只是写道了python的内存中(或叫缓冲区),在flush后才是写入到真正的文件中,或者使用close()方法,关闭后会自动flush刷新,这样做是避免频繁的操作硬盘,导致效率下降(一堆,一次性写磁盘;
- write写入文件的时候,如果此文件不存在,那么就会创建一个新文件;
# 1.打开文件
f = open('my_txt', 'w')# 2.文件写入
f.write("# 张三律师")# 3.内容刷新
f.flush()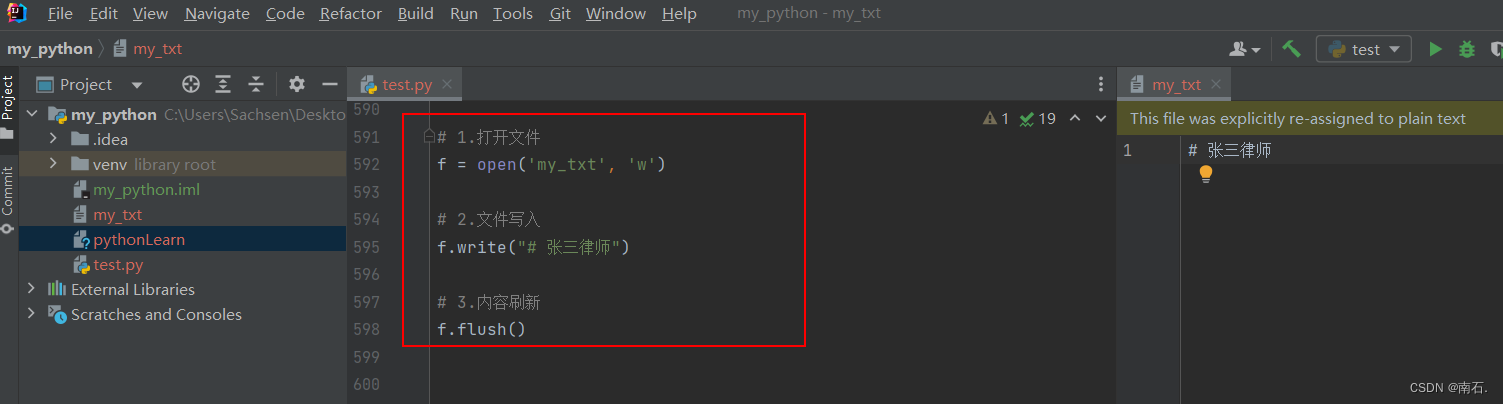
4. 文件的追加操作
- 'w' 代表mode中的第二种模式,文件存在则清空此文件,写入数据,文件不存在则创建一个新文件,插入数据;
- 'a' 代表mode中的第三种模式,追加数据在文件中;
- 文件不存在会创建文件;
- 文件存在会在最后,追加写入文件;
# 1.打开文件
f = open('my_txt', 'a')# 2.文件追加
f.write("# 尊师重道")# 3.内容刷新
f.flush()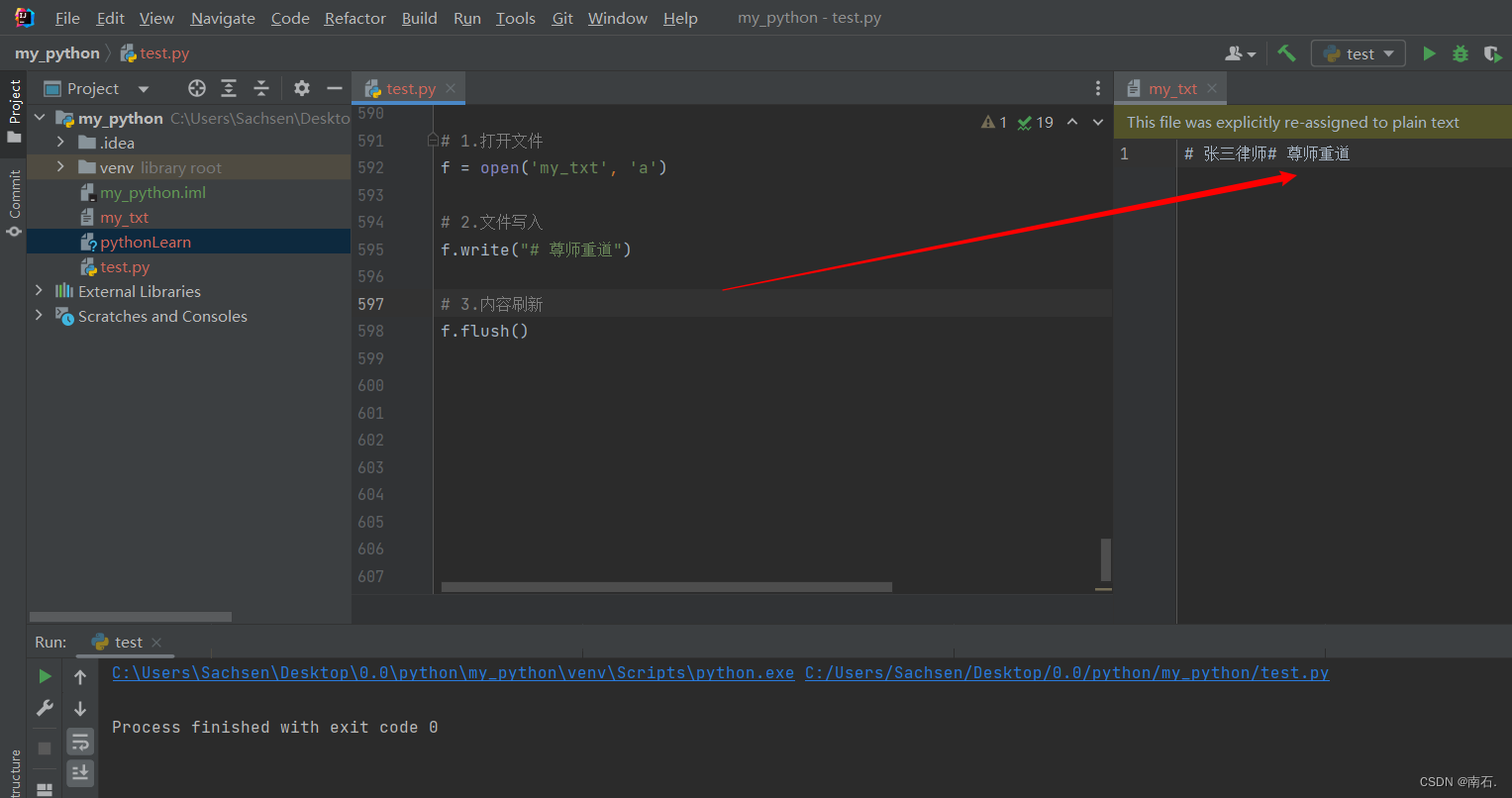
5. 文件操作的综合案例(文件备份操作)
我的思路:open函数中的'w'操作,当前文件打开后,既第一次打开文件的时候会清空文件,但是打开文件后,并没有关闭他,且不断的往里面写入数据,因此可以做到一个备份文件操作。
# 1.打开文件获取文件对象
fr = open('my_txt', "r", encoding="UTF-8")
# 准备写入的文件对象
fw = open('my_text_copy', "w", encoding="UTF-8")for line in fr:line = line.strip() # 去除字符串前后空格fw.write(line) # 写入到新文件fw.write("\n") # 写入后换行fr.close()
fw.close()这篇关于Python第二语言(五、Python文件相关操作)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






