本文主要是介绍基于深度学习的在线选修课程推荐系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于深度学习的在线选修课程推荐系统
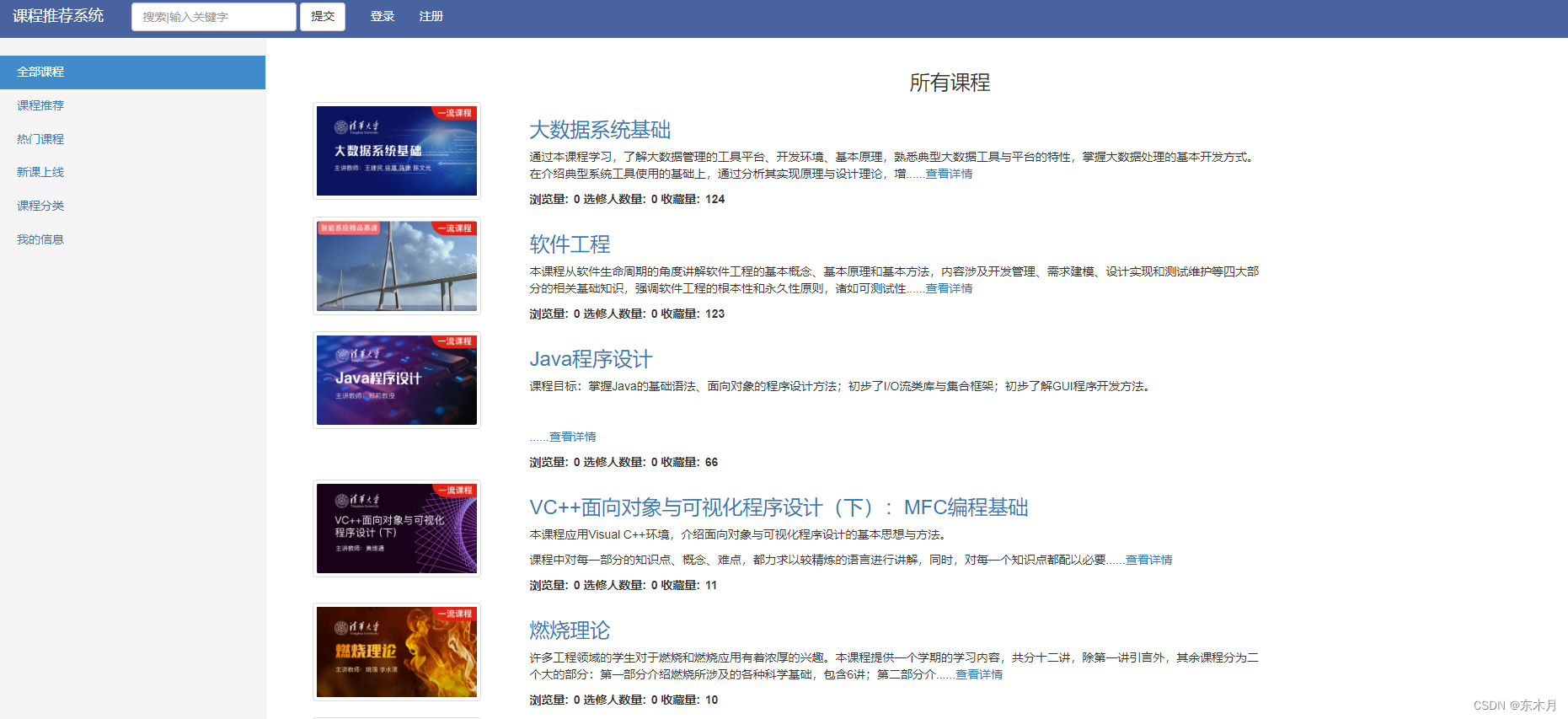
1、效果图
点我查看Demo
2、功能
可联系我-微-信(1257309054)
登录注册、点赞收藏、评分评论,课程推荐,热门课程,个人中心,可视化,后台管理,课程选修
3、核心推荐代码
使用Keras框架实现一个简单的深度学习推荐算法。Keras是建立在Python之上的高级神经网络API。Keras提供了一种简单、快速的方式来构建和训练深度学习模型。
根据用户对书籍的评分表,使用Emmbeding深度学习训练得到一个模型,预测用户可能评分高的书籍,并把前5本推荐给用户。
Emmbeding是从离散对象(如书籍 ID)到连续值向量的映射。
这可用于查找离散对象之间的相似性。
Emmbeding向量是低维的,并在训练网络时得到更新。
设计一个模型,将用户id作为用户向量,物品id作为物品向量。
分别Emmbeding两个向量,再Concat连接起来,最后加上3个全连接层构成模型,进行训练。
使用adam优化器,用均方差mse来衡量预测评分与真实评分之间的误差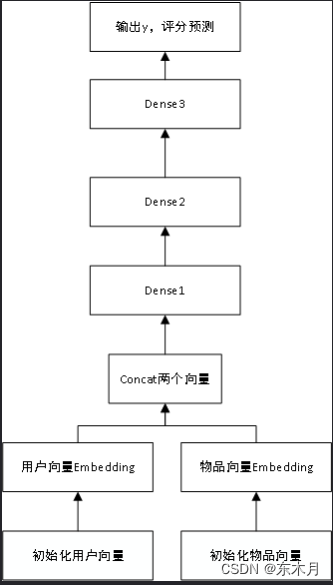
4、算法流程
1、从数据库中读取评分表信息并转成二维数组
2、数据预处理,把用户id,物品id映射成顺序字典
3、统计用户数量、物品数量
4、划分训练集与测试集
5、构建Embedding模型并进行数据训练得到模型
6、调用模型预测评分高的物品并推荐给用户5、主体核心代码
-*- coding: utf-8 -*-"""
@contact: 微信 1257309054
@file: recommend_keras.py
@time: 2024/6/8 16:21
@author: LDC
使用Keras框架实现一个深度学习推荐算法
"""import os
import django
from django.conf import settingsos.environ["DJANGO_SETTINGS_MODULE"] = "course_manager.settings"
django.setup()import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymysql
from sklearn.model_selection import train_test_split
import warningswarnings.filterwarnings('ignore')from course.models import UserSelectTypes, CourseInfo, RateCourse
from keras.layers import Input, Embedding, Flatten, Dot, Dense, Concatenate, Dropout
from keras.models import Modelfrom keras.models import load_modeldef get_select_tag_course(user_id, course_id=None):# 获取用户注册时选择的课程类别各返回10门课程category_ids = []us = UserSelectTypes.objects.get(user_id=user_id)for category in us.category.all():category_ids.append(category.id)unrec = []if course_id:unrec.append(course_id)course_list = CourseInfo.objects.filter(tags__in=category_ids).exclude(id__in=unrec).distinct().order_by("-collect_num")[:10]return course_listdef get_data():'''从数据库获取数据'''conn = pymysql.connect(host=settings.DATABASE_HOST,user=settings.DATABASE_USER,password=settings.DATABASE_PASS,database=settings.DATABASE_NAME,charset='utf8mb4',use_unicode=True)# 选择评分大于等于3的课程sql_cmd = 'SELECT course_id, user_id,mark FROM rate_course where mark >=3'dataset = pd.read_sql(sql=sql_cmd, con=conn)conn.close()return datasetdef preprocessing(dataset):'''数据预处理'''course_val_counts = dataset.course_id.value_counts()course_map_dict = {} # 课程字典for i in range(len(course_val_counts)):course_map_dict[course_val_counts.index[i]] = i# print(map_dict)dataset["course_id"] = dataset["course_id"].map(course_map_dict)user_id_val_counts = dataset.user_id.value_counts()# 映射字典user_id_map_dict = {} # 用户字典for i in range(len(user_id_val_counts)):user_id_map_dict[user_id_val_counts.index[i]] = i# 将User_ID映射到一串字典dataset["user_id"] = dataset["user_id"].map(user_id_map_dict)return dataset, course_map_dict, user_id_map_dictdef train_model():'''训练模型'''dataset = get_data() # 获取数据dataset, course_map_dict, user_id_map_dict = preprocessing(dataset) # 数据预处理n_users = len(dataset.user_id.unique()) # 统计用户数量print('n_users', n_users)n_courses = len(dataset.course_id.unique()) # 统计课程数量print('n_courses', n_courses)# 划分训练集与测试集train, test = train_test_split(dataset, test_size=0.2, random_state=42)# 开始训练# creating course embedding pathcourse_input = Input(shape=[1], name="course-Input")course_embedding = Embedding(n_courses + 1, 5, name="course-Embedding")(course_input)Dropout(0.2)course_vec = Flatten(name="Flatten-courses")(course_embedding)# creating user embedding pathuser_input = Input(shape=[1], name="User-Input")user_embedding = Embedding(n_users + 1, 5, name="User-Embedding")(user_input)Dropout(0.2)user_vec = Flatten(name="Flatten-Users")(user_embedding)# concatenate featuresconc = Concatenate()([course_vec, user_vec])# add fully-connected-layersfc1 = Dense(128, activation='relu')(conc)Dropout(0.2)fc2 = Dense(32, activation='relu')(fc1)out = Dense(1)(fc2)# Create model and compile itmodel2 = Model([user_input, course_input], out)model2.compile('adam', 'mean_squared_error')history = model2.fit([train.user_id, train.course_id], train.mark, epochs=10, verbose=1)model2.save('regression_model2.h5')loss = history.history['loss'] # 训练集损失# 显示损失图像# plt.plot(loss, 'r')# plt.title('Training loss')# plt.xlabel("Epochs")# plt.ylabel("Loss")# plt.show()print('训练完成')def predict(user_id, dataset):'''将预测评分高的课程推荐给该用户user_id'''model2 = load_model('regression_model2.h5')'''先拿到所有的课程,并去重成为course_data。再添加一个和course_data长度相等的用户列表user,不过这里的user列表中的元素全是1,因为:预测第1个用户对所有课程的评分,再将预测评分高的课程推荐给该用户。'''course_data = np.array(list(set(dataset.course_id)))user = np.array([user_id for i in range(len(course_data))])predictions = model2.predict([user, course_data])# 更换列->行predictions = np.array([a[0] for a in predictions])# 根据原array,取其中数值从大到小的索引,再只取前top10recommended_course_ids = (-predictions).argsort()[:8]return recommended_course_idsdef embedding_main(user_id, course_id=None, is_rec_list=False):'''1、获取用户评分大于等于3的课程数据2、数据预处理:把数据映射成用户向量Embedding,课程向量Embedding3、划分训练集与测试集:使用二八法则随机划分,80%的数据用来训练,20%的数据用来测试4、训练模型:分别Emmbeding两个向量,再Concat连接起来,最后加上3个全连接层构成模型,进行训练5、模型评估:通过查看训练集损失函数来查看模型优劣6、预测推荐:对用户评分过的课程进行模型预测,把预测评分高的课程推荐给用户user_id: 用户idcourse_id: 用户已经评分过的课程id,需要在推荐列表中去除is_rec_list: 值为True:返回推荐[用户-评分]列表,值为False:返回推荐的课程列表'''dataset = get_data() # 获取数据# print(dataset.head())if user_id not in dataset.user_id.unique():# 用户未进行评分则推荐注册时选择的课程类型print('用户未进行评分则推荐注册时选择的课程类型')if is_rec_list:return []# 推荐列表为空,按用户注册时选择的课程类别各返回10门return get_select_tag_course(user_id, course_id)dataset, course_map_dict, user_id_map_dict = preprocessing(dataset)# user_id需要转换为映射后的user_id传到predict函数中predict_course_ids = predict(user_id_map_dict[user_id], dataset) # 预测的课程Idrecommend_list = [] # 最后推荐的课程id# 把映射的值转为真正的课程idfor course_id in predict_course_ids:for k, v in course_map_dict.items():if course_id == v:recommend_list.append(k)print('keras_recommended_course_ids深度学习推荐列表', recommend_list)if not recommend_list:# 推荐列表为空,且is_rec_list: 值为True:返回推荐[用户-评分]列表if is_rec_list:return []# 推荐列表为空,按用户注册时选择的课程类别return get_select_tag_course(user_id, course_id)if is_rec_list:# 推荐列表不为空,且且is_rec_list: 值为True:返回推荐[用户-评分]列表return recommend_listunres = []if course_id:unres.append(course_id)# 过滤掉用户已评分的数据already_mark_ids = [d['course_id'] for d in RateCourse.objects.filter(user_id=user_id).values('course_id')]unrecommend = list(set(unres + already_mark_ids))if course_id and course_id not in unrecommend:unrecommend.append(course_id)course_list = CourseInfo.objects.filter(id__in=recommend_list).exclude(id__in=unrecommend).distinct().order_by("-collect_num")return course_listif __name__ == '__main__':train_model() # 训练模型embedding_main(2) # 调用模型6、输出效果
Epoch 1/10
1/1 [==============================] - 2s 2s/step - loss: 25.0221
Epoch 2/10
1/1 [==============================] - 0s 8ms/step - loss: 24.9007
Epoch 3/10
1/1 [==============================] - 0s 7ms/step - loss: 24.8011
Epoch 4/10
1/1 [==============================] - 0s 6ms/step - loss: 24.7061
Epoch 5/10
1/1 [==============================] - 0s 3ms/step - loss: 24.6062
Epoch 6/10
1/1 [==============================] - 0s 4ms/step - loss: 24.5012
Epoch 7/10
1/1 [==============================] - 0s 5ms/step - loss: 24.3921
Epoch 8/10
1/1 [==============================] - 0s 5ms/step - loss: 24.2739
Epoch 9/10
1/1 [==============================] - 0s 3ms/step - loss: 24.1532
Epoch 10/10
1/1 [==============================] - 0s 5ms/step - loss: 24.0253
训练完成
1/1 [==============================] - 0s 200ms/step
keras_recommended_course_ids深度学习推荐列表 [61, 98, 71, 81, 97]这篇关于基于深度学习的在线选修课程推荐系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





