本文主要是介绍利用ArcGIS对长江三角洲地区的gdp水平进行聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、导入矢量图、数据

长三角地区矢量图
长三角地区矢量图对应数据
2、连接
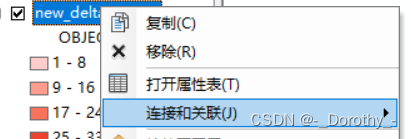
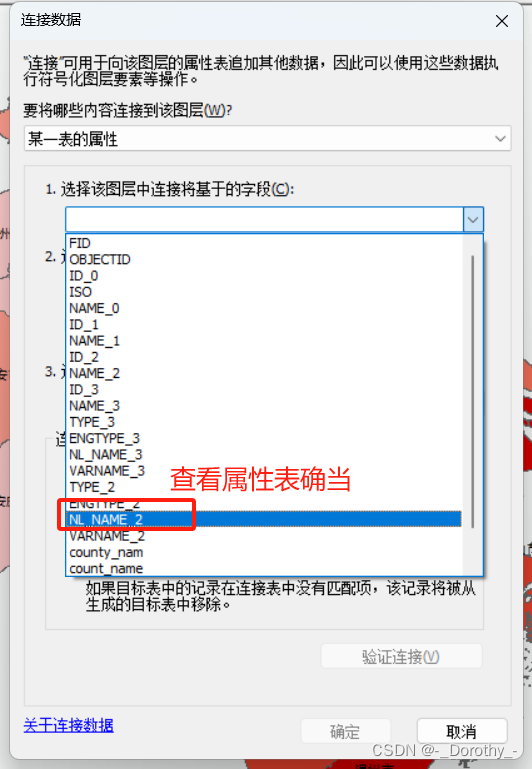
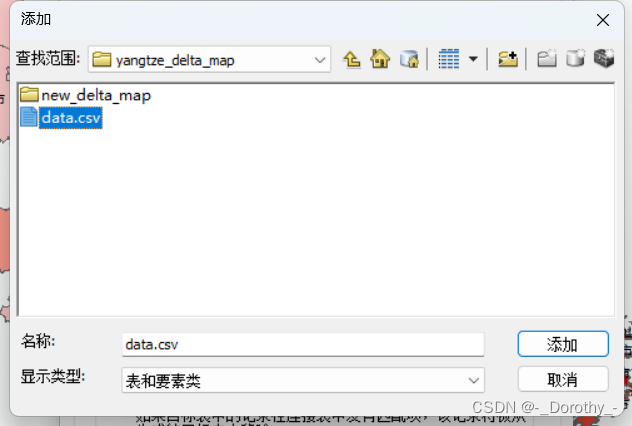
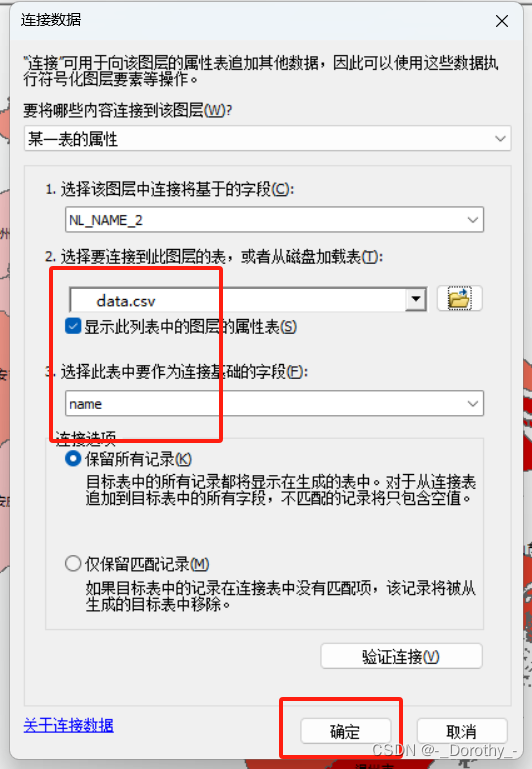
3、设置属性将人均gdp数据导入
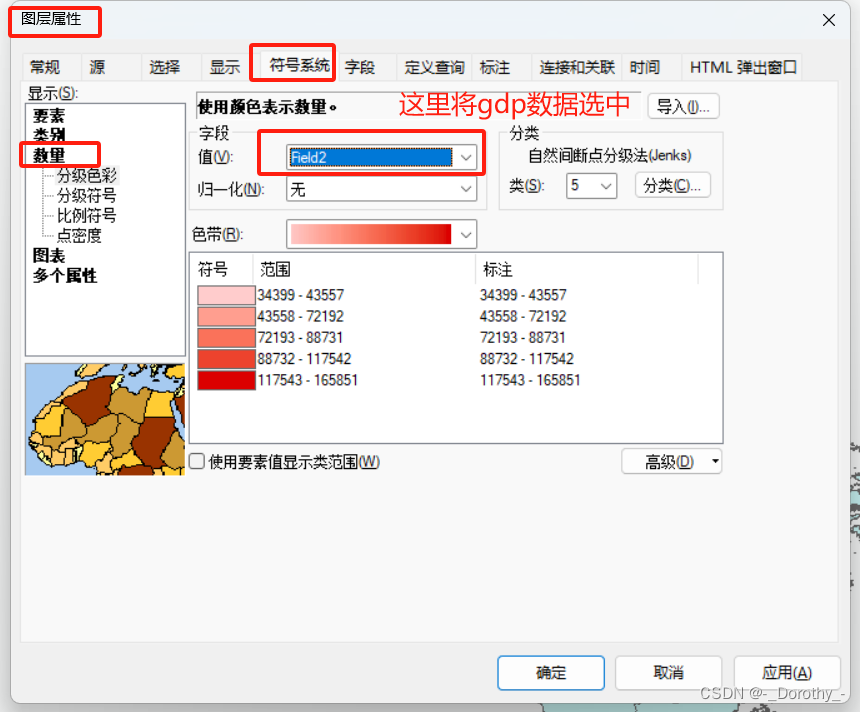
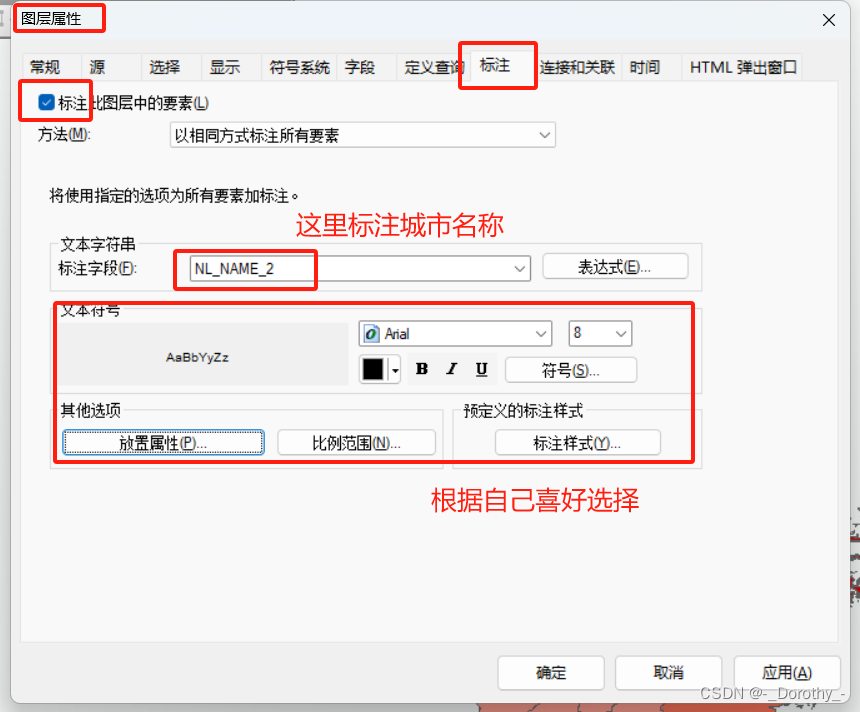
4、设置标注和图例

选择布局视图
5、聚类
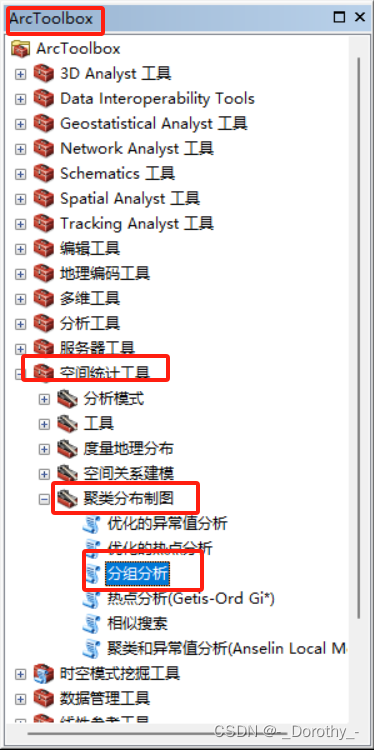
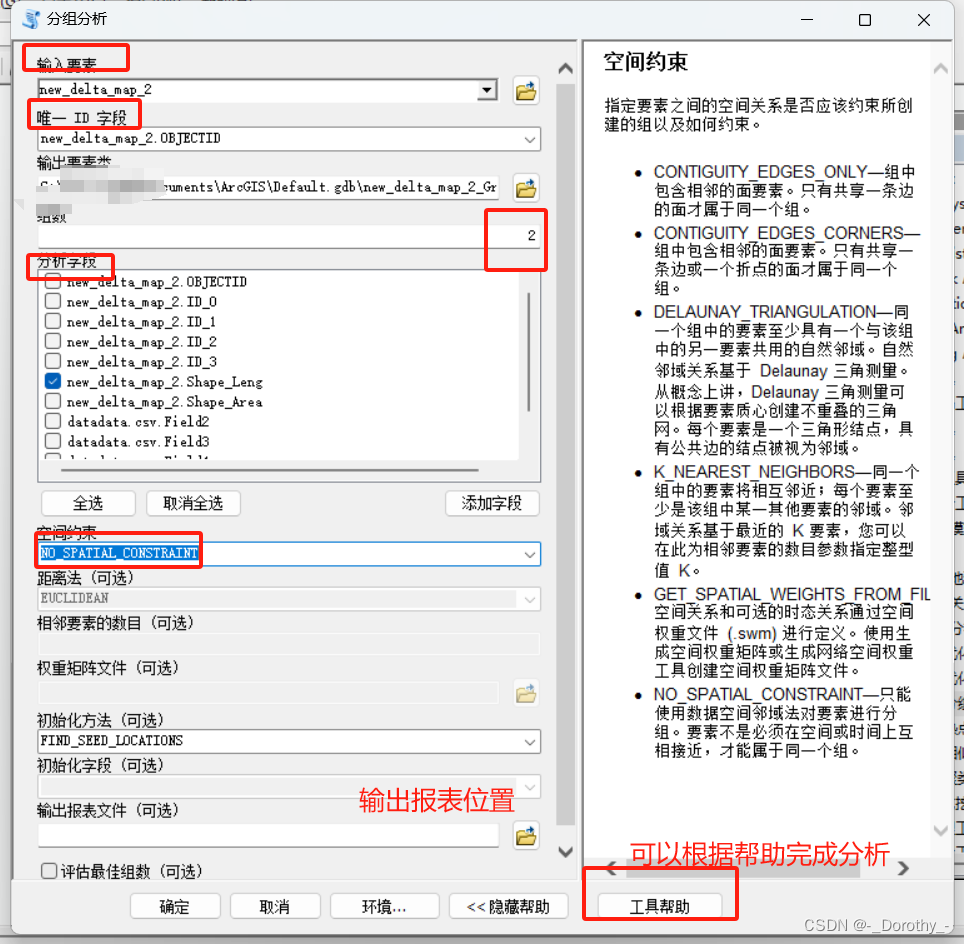
2020年人均gdp地区聚类
6、2005~2020年各地区人均gdp可视化及聚类汇总
(1)2005~2020可视化
2005

2010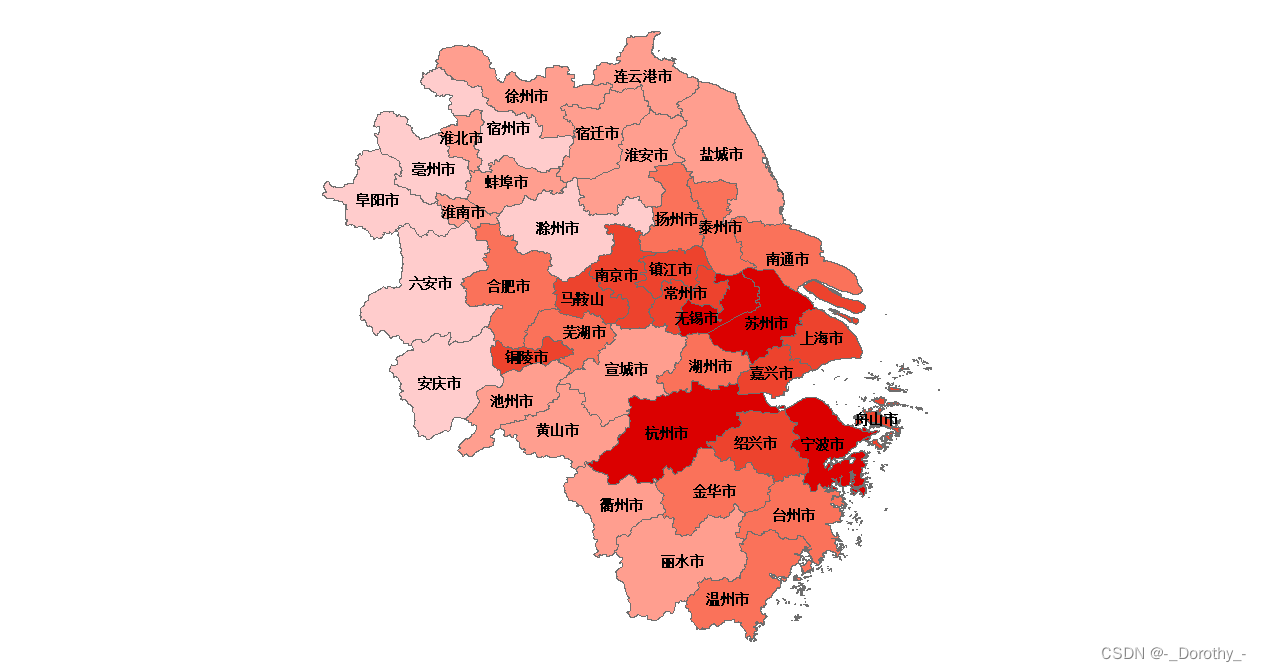
2015
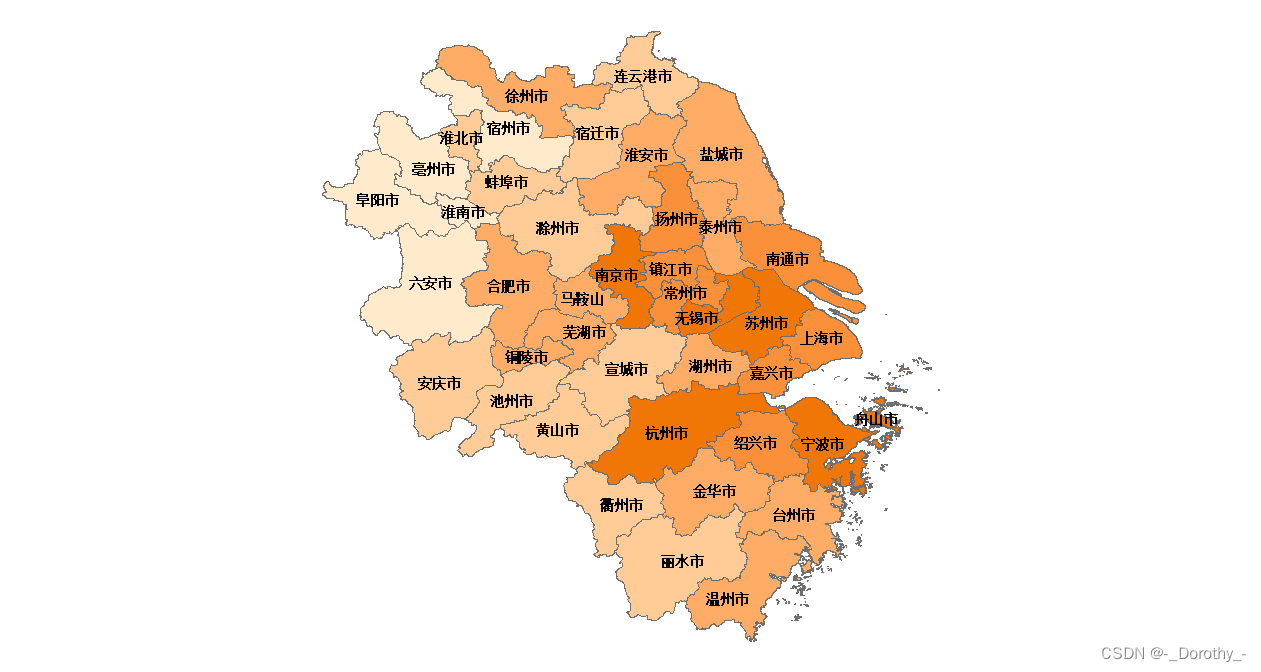
2020
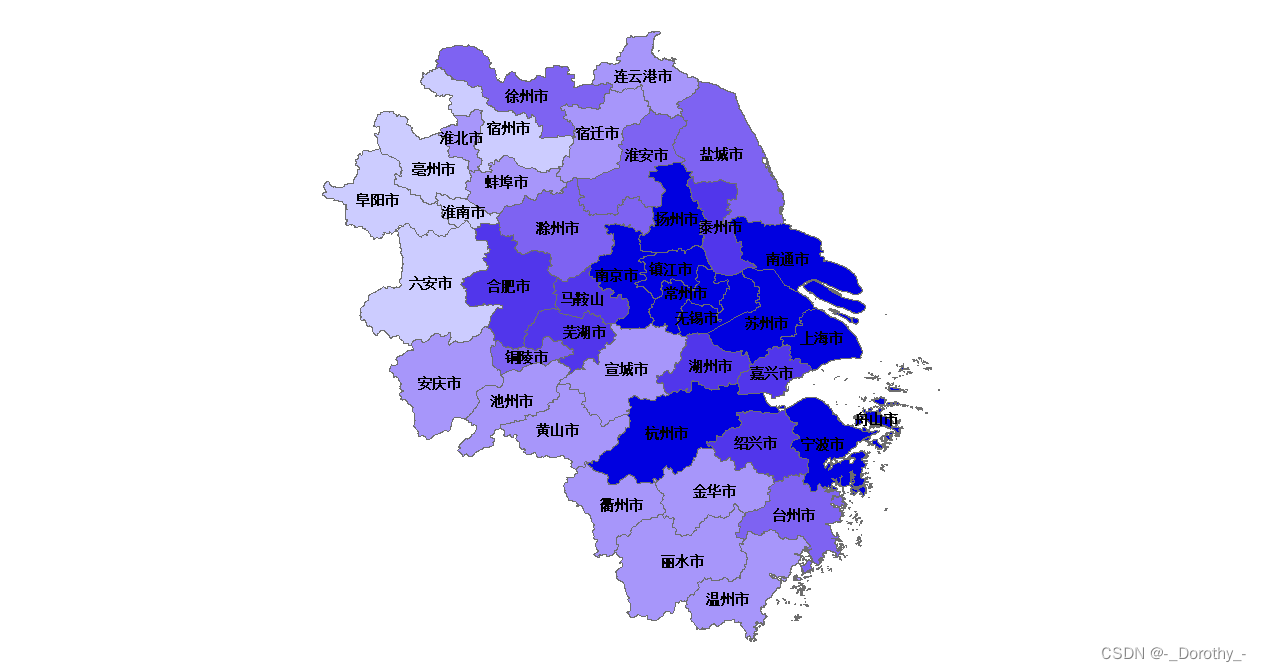
(2)根据K-means轮廓系数确定聚类簇数
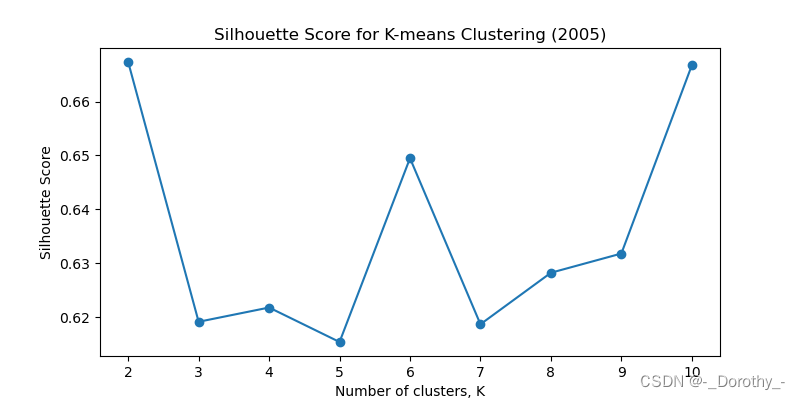
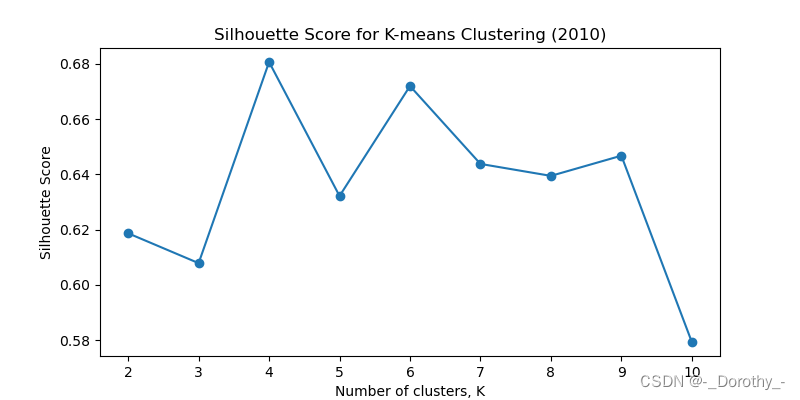
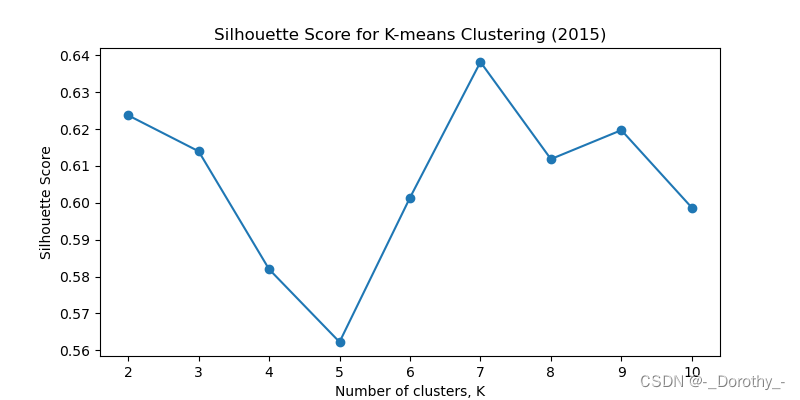
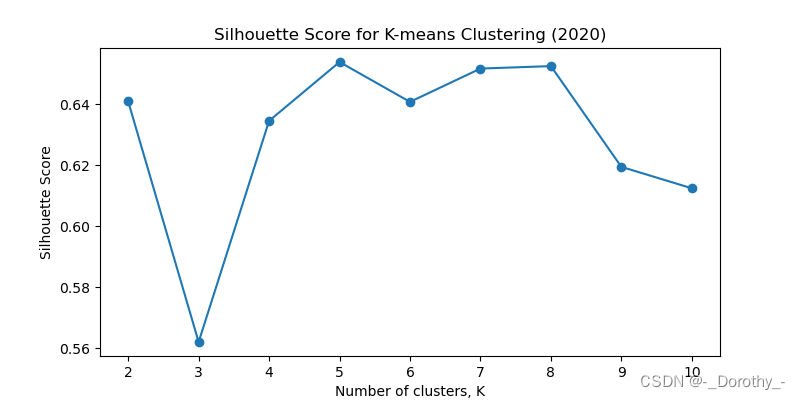
2015 2010 2015 2020 分别对应的最佳聚类簇数为 2 4 7 5
可以根据这个结果进行分组分析
代码:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt# 读取CSV文件
file_path = 'datadata.csv'
data = pd.read_csv(file_path, encoding="GB2312")# 查看数据
print(data.head())# 初始化一个字典来存储各年的轮廓系数
silhouette_scores_dict = {}# 对每一年的GDP数据进行聚类
years = ['2020', '2015', '2010', '2005']for year in years:gdp_data = data[[year]]# 确定最佳K值silhouette_scores = []K = range(2, 11) # 假设我们考虑2到10个聚类簇for k in K:kmeans = KMeans(n_clusters=k, random_state=42)labels = kmeans.fit_predict(gdp_data)score = silhouette_score(gdp_data, labels)silhouette_scores.append(score)# 保存轮廓系数silhouette_scores_dict[year] = silhouette_scores# 绘制轮廓系数图plt.figure(figsize=(8, 4))plt.plot(K, silhouette_scores, marker='o')plt.xlabel('Number of clusters, K')plt.ylabel('Silhouette Score')plt.title(f'Silhouette Score for K-means Clustering ({year})')plt.savefig(f'silhouette_score_{year}.png') # 保存图片plt.show()# 找出最佳K值best_k = K[silhouette_scores.index(max(silhouette_scores))]print(f'{year} 年最佳聚类簇数: {best_k}')# 使用最佳K值进行K-means聚类kmeans = KMeans(n_clusters=best_k, random_state=42)labels = kmeans.fit_predict(gdp_data)# 将聚类结果添加到原始数据中data[f'Cluster_{year}'] = labels# 打印聚类结果print(f'{year} 年聚类结果:')print(data[[year, f'Cluster_{year}']].head())# 查看聚类结果
print(data.head())# 保存聚类结果到CSV文件
data.to_csv('clustered_gdp_data.csv', index=False)(3)根据聚类结果得出聚类可视化及文档
(4)为了方便分析变化 4年都选择簇数为3
2005
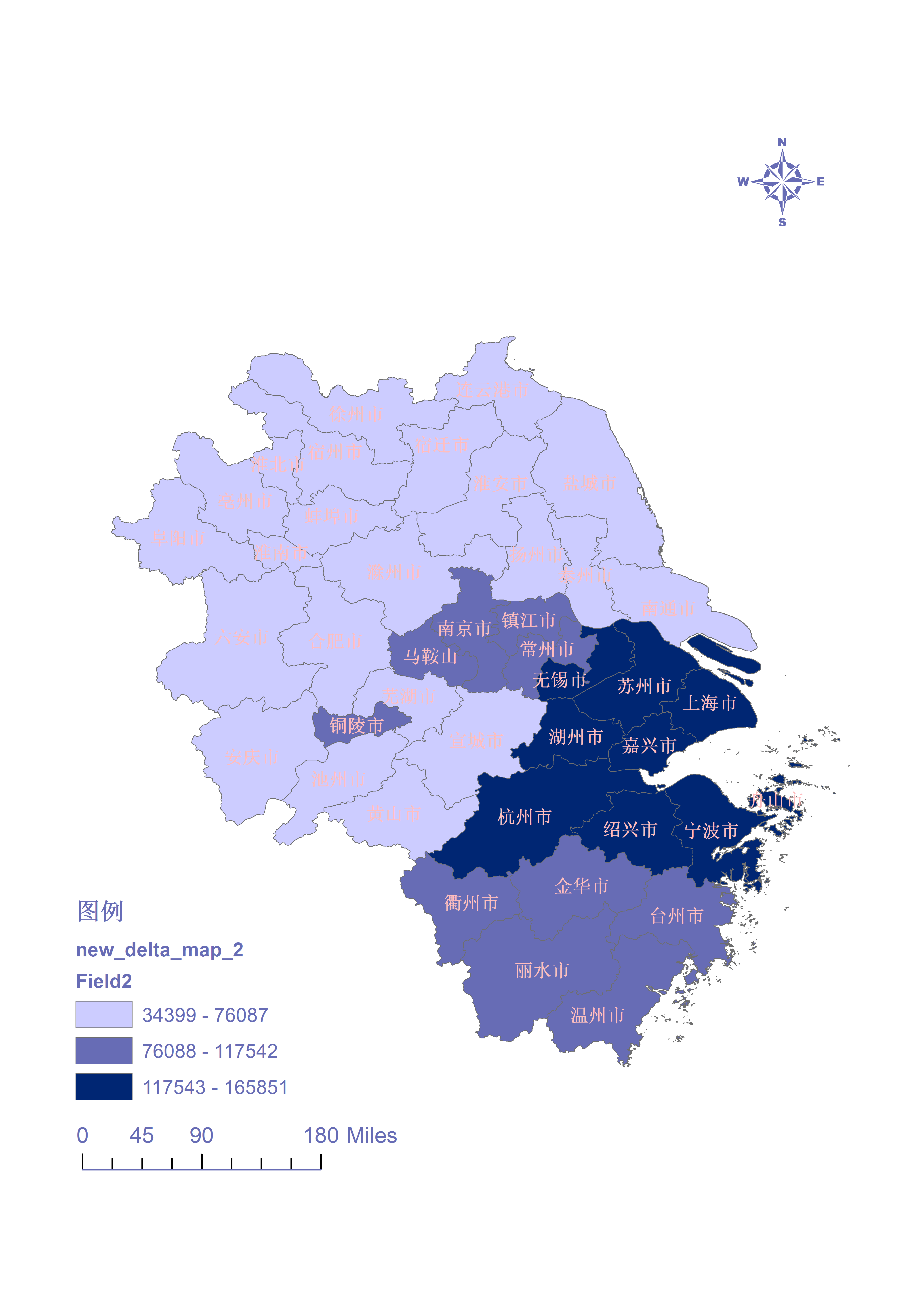
2010
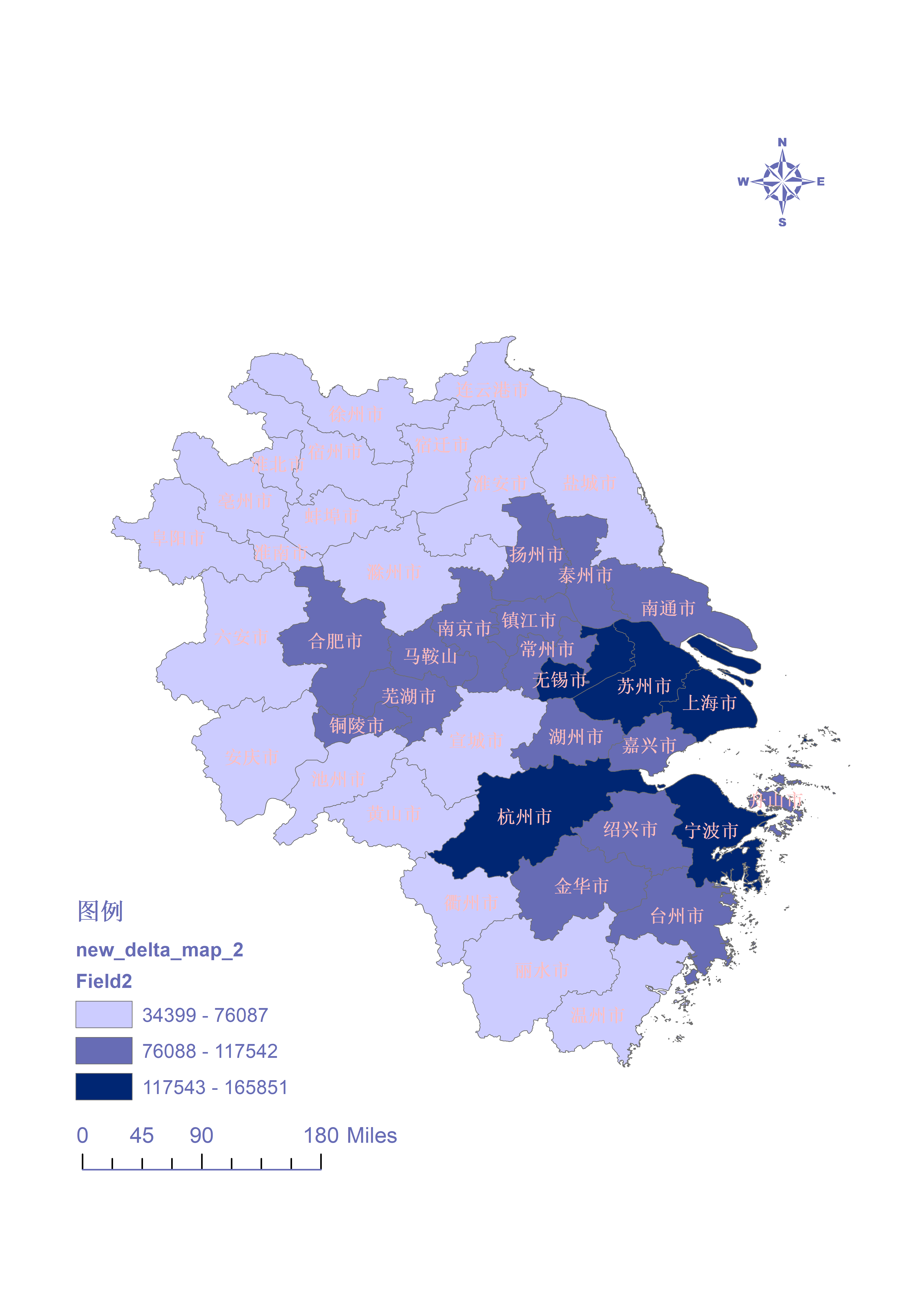
2015
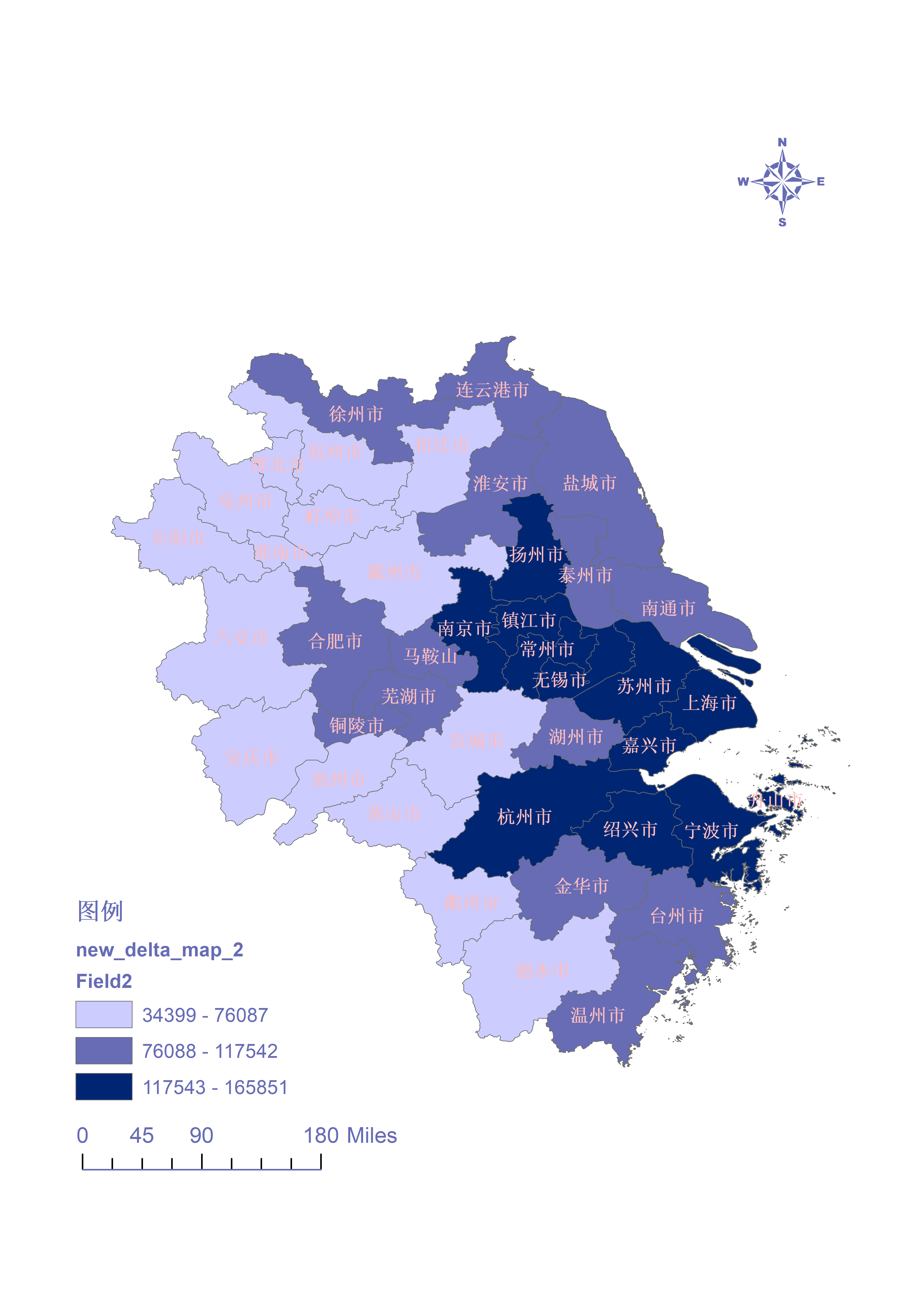
2020

(5)将图片背景设置为透明色

这篇关于利用ArcGIS对长江三角洲地区的gdp水平进行聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






