本文主要是介绍Mac 使用Docker安装Elasticsearch、Kibana 、ik分词器、head,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装ElasticSearch
- 通过docker安装es
docker pull elasticsearch:7.8.1
- 在本地创建elasticsearch.yml文件
mkdir /Users/ky/Documents/learn/es/elasticsearch.yml
- 编辑yml文件内容
http: host: 0.0.0.0
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: falsehttp.cors.enabled: true
http.cors.allow-origin: "*"
- 启动es容器
docker run --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -v /Users/ky/Documents/learn/es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -d elasticsearch:7.8.1
启动命令 相关参数解析
docker run: 运行 Docker 容器的命令。
--name es: 为容器指定一个名称(es)。-p 9200:9200 -p 9300:9300:
将容器的端口 9200(用于 HTTP)和端口 9300(用于节点间通信)映射到宿主机的相同端口,使得可以通过宿主机访问 Elasticsearch 服务。-e "discovery.type=single-node":
设置 Elasticsearch 的发现类型为单节点模式,这样 Elasticsearch 将以单节点的方式运行而无需进行集群发现。-e ES_JAVA_OPTS="-Xms512m -Xmx512m":
设置 Elasticsearch 的 Java 虚拟机参数,指定初始堆内存为 512MB,最大堆内存为 512MB。-v /Users/ky/Documents/learn/es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:
将宿主机上的 Elasticsearch 配置文件 /Users/ky/Documents/learn/es/elasticsearch.yml 挂载到容器内的配置文件路径,以便使用自定义的配置。-d elasticsearch:8.6.2: 使用 Elasticsearch 7.8.1 镜像创建容器,并在后台运行。通过运行这个命令,你将在 Docker 中创建一个名为 "es" 的 Elasticsearch 容器,并将端口 9200 和 9300 映射到宿主机上,同时配置了单节点模式和自定义的 Java 虚拟机参数。你还将宿主机上的自定义配置文件挂载到容器中,以便使用该配置文件启动 Elasticsearch。注意: 命令中的文件路径和镜像版本是根据你的实际情况提供的示例路径和版本号,你可以根据自己的需求进行相应的调整。
-
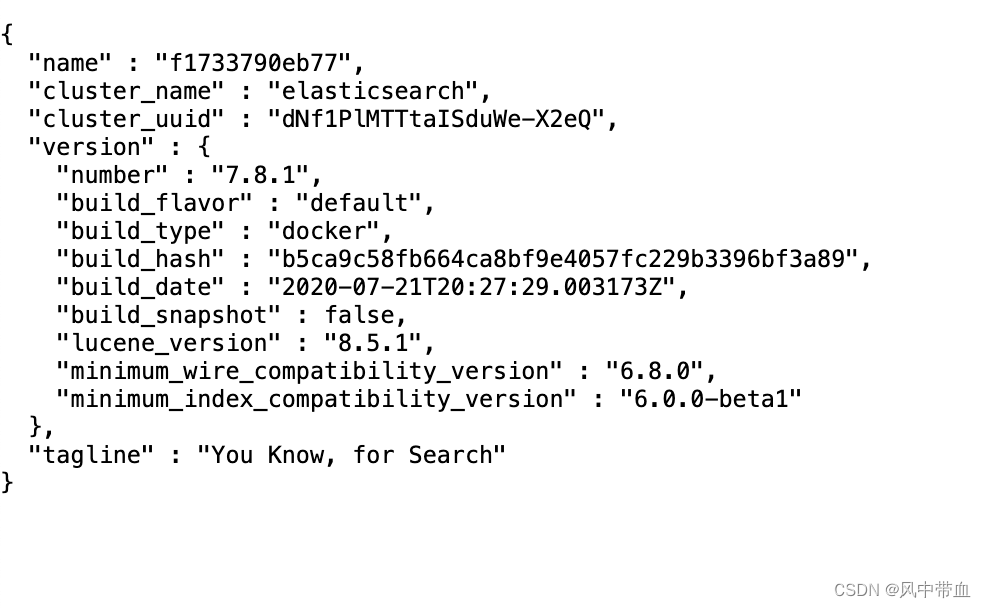
启动了之后访问: http://localhost:9200/
-
页面出现以下信息即启动成功
安装Kibana
- 使用docker安装kibana
docker pull kibana:7.8.1
- 在本地创建kibana.yml文件
mkdir /Users/ky/Documents/learn/es/kibana.yml
- 编辑yml文件
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: truei18n.locale: "zh-CN"- 启动kibana
docker run --name kibana -p 5601:5601 --link es:elasticsearch -v /Users/ky/Documents/learn/es/kibana.yml:/usr/share/kibana/config/kibana.yml -d kibana:7.8.1
启动命令 相关参数解析:
docker run: 运行 Docker 容器的命令。--name kibana: 为容器指定一个名称(kibana)。-p 5601:5601: 将容器的端口 5601 映射到宿主机的相同端口,使得可以通过宿主机访问 Kibana 服务。--link es:elasticsearch: 将 Elasticsearch 容器(名称为 "es")与 Kibana 容器连接起来,以便 Kibana 可以与 Elasticsearch 进行通信。-v /Users/ky/Documents/learn/es/kibana.yml:/usr/share/kibana/config/kibana.yml: 将宿主机上的 Kibana 配置文件 /Users/ky/Documents/learn/es/kibana.yml 挂载到容器内的配置文件路径,以便使用自定义的配置。-d kibana:7.8.1: 使用 Kibana 7.8.1 镜像创建容器,并在后台运行。通过运行这个命令,你将在 Docker 中创建一个名为 "kibana" 的 Kibana 容器,并将端口 5601 映射到宿主机上。容器将与 Elasticsearch 容器建立连接,以便 Kibana 可以与 Elasticsearch 进行通信。你还将宿主机上的自定义配置文件挂载到容器中,以便使用该配置文件启动 Kibana。注意:命令中的文件路径和镜像版本是根据你的实际情况提供的示例路径和版本号,你可以根据自己的需求进行相应的调整。
- 启动后访问链接: http://localhost:5601
安装ik分词器
- 进入es容器目录
docker exec -it -u 0 es /bin/bash
- 下载 IK 插件压缩包
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.1/elasticsearch-analysis-ik-7.8.1.zip
- 查看ik插件
elasticsearch-plugin list
- 修改配置文件 自定义字典配置(自己的词库)
- 在/config/analysis-ik/目录中仿照其他dic文件新增自己的字典
- 在IKAnalyzer.cfg.xml中引入自己的字典
cd /config/analysis-ik/
vi IKAnalyzer.cfg.xml
安装可视化界面:elasticsearch-head
- 谷歌插件安装
搜索Elasticsearch Head

这篇关于Mac 使用Docker安装Elasticsearch、Kibana 、ik分词器、head的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





