本文主要是介绍python基础——-多任务-正则-装饰器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、多任务
1-进程和线程
进程是操作系统分配资源的最小单元
线程执行程序的的最小单元
线程依赖进程,可以获取进程的资源
一个程序执行 先要创建进程分配资源,然后使用线程执行任务
默认情况下一个进程中有一个线程
2-多任务介绍
运行多个进程或线程执行代码逻辑
多个进程或线程同时执行叫做并行执行
多个进程或线程交替执行叫做并发执行
必行还是并发有cpu个数决定
5个进程 cpu核心是3个 计算时时并发执行 5个进程需要抢占cpu资源,谁抢到谁执行代码计算
5个进程 cpu核心10个 计算时时并行执行 不需要抢占资源,没个进程都已一个独立的cpu核心使用完成计算
多任务在执行计算时,可以执行的同一的计算任务,也可以执行不同的任务
3-多进程
多进程实现多任务就是创建多个进程执行任务函数
任务1 唱歌 任务2 跳舞 任务3 弹吉他
不使用多任务执行
程序执行顺序是从上往下依次执行,如果上一个函数没有执行完成,那么下一个函数,不会被执行
使用多进程实现多任务
import time
from multiprocessing import Process
def cook():print('做饭')time.sleep(4)print('饭已做好')
def clean():print('扫地')time.sleep(4)print('打扫完成')
def play():print('玩游戏')
if __name__ == '__main__':# 创建进程p1 = Process(target=cook)p2 = Process(target=clean)p3 = Process(target=play)
# 执行进程p1.start()p2.start()p3.start()
I-任务中的参数传递
import time
from multiprocessing import Process
def cook(name):print(f'做{name}')time.sleep(4)print('饭已做好')
def clean(a,b,c):print(f'打扫{a},{b},{c}')time.sleep(4)print('打扫完成')
def play(name):print(f'玩{name}游戏')
if __name__ == '__main__':# 创建进程p1 = Process(target=cook,args=['红烧肉'])p2 = Process(target=clean,kwargs={'a':'客厅','b':'厨房','c':'卧室'})p3 = Process(target=play,args=['dota'])
# 执行进程p1.start()p2.start()p3.start()
II-获取进程编号
-
getpid
-
getppid
import time
from multiprocessing import Process
import os
def cook(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')
# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'做{name}')time.sleep(4)print('饭已做好')
def clean(a,b,c):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'打扫{a},{b},{c}')time.sleep(4)print('打扫完成')
def play(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'玩{name}游戏')
if __name__ == '__main__':# 创建子进程p1 = Process(target=cook,args=['红烧肉'])p2 = Process(target=clean,kwargs={'a':'客厅','b':'厨房','c':'卧室'})p3 = Process(target=play,args=['dota'])# 执行进程p1.start()p2.start()p3.start()
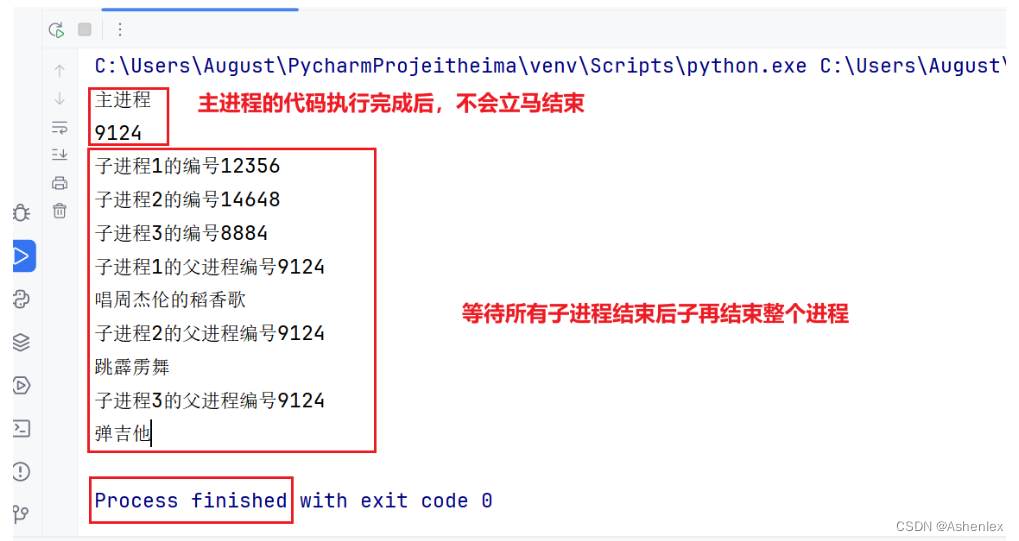
# 主进程自己的任务print('主进程')# 使用os模块获取当前进程编号num = os.getpid()print(f'当前主进程编号{num}')
主进程默认情况下是等待子进程结束后在结束整个进程的
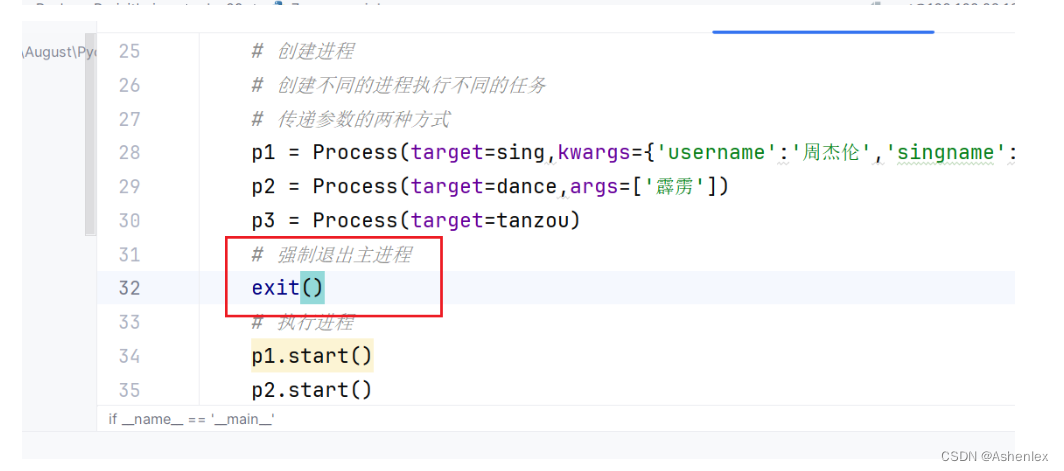
也可以通过exit()方法强制退出主进程,所有进程都结束
III-保证进程的执行顺序
会影响执行效率
如果进程之间没有对应的数据传递关系,可以不用保证顺序,多个进程可以同时执行
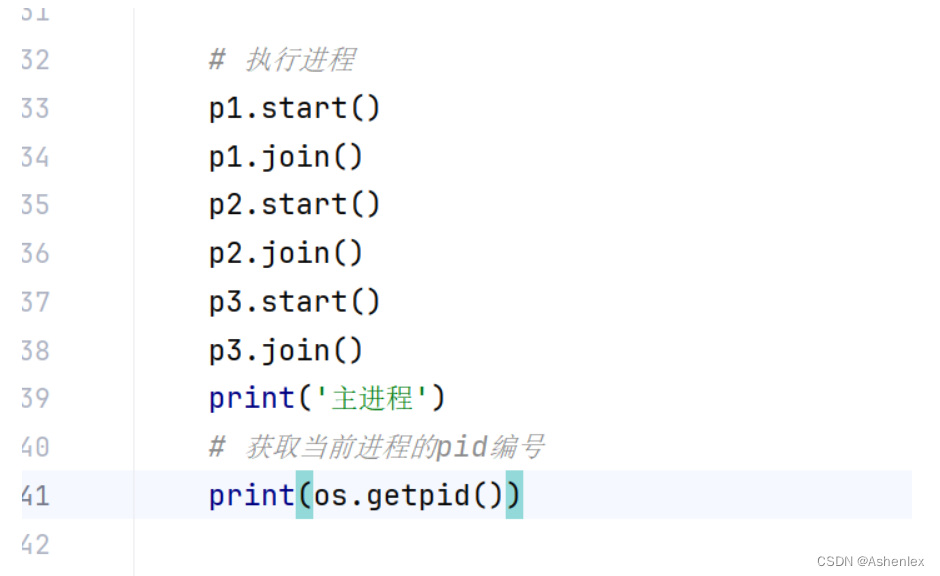
如果进程之间有数据传递需求,就要保证执行顺序,通过join操作,但是该操作会影响执行效率
import time
from multiprocessing import Process
import os
def cook(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')
# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'做{name}')time.sleep(4)print('饭已做好')
def clean(a,b,c):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'打扫{a},{b},{c}')time.sleep(4)print('打扫完成')
def play(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前子进程编号{num}')# 获取父进程编号p_num = os.getppid()print(f'当前子进程父进程编号{p_num}')
print(f'玩{name}游戏')
if __name__ == '__main__':# 创建子进程p1 = Process(target=cook,args=['红烧肉'])p2 = Process(target=clean,kwargs={'a':'客厅','b':'厨房','c':'卧室'})p3 = Process(target=play,args=['dota'])# 执行进程p1.start()# 使用jion方法保证执行顺序 变成单任务p1.join()p2.start()p2.join()p3.start()p3.join()
# 主进程自己的任务print('主进程')# 使用os模块获取当前进程编号num = os.getpid()print(f'当前主进程编号{num}')
IV-进程间的数据不共享
每个进程的资源时独立。数据就不共享
from multiprocessing import Process
a = 1
def func1():global aa = a + 1print(f'子进程1中的a:{a}')
def func2():global aa = a + 1print(f'子进程2中的a:{a}')
if __name__ == '__main__':
# 创建进程p1 = Process(target=func1)p2 = Process(target=func2)
p1.start()p2.start()
print(f'主进程中的a:{a}')
4-多线程
线程依赖进程,可以创建一个进程,在一个进程下创建多个线程执行任务
# 多线程实现多任务
import time
from threading import Thread
import os
def cook(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'做{name}')time.sleep(4)print('饭已做好')
def clean(a,b,c):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'打扫{a},{b},{c}')time.sleep(4)print('打扫完成')
def play(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'玩{name}游戏')
if __name__ == '__main__':
# 创建线程t1 = Thread(target=cook,args=['梅菜扣肉'])t2 = Thread(target=clean,kwargs={'a':'客厅','b':'厨房','c':'卧室'})t3 = Thread(target=play,args=['魔兽世界'])
t1.start()
t2.start()
t3.start()
num = os.getpid()print(f'当前进程编号{num}')
线程任务传参
# 多线程实现多任务
import time
from threading import Thread
import os
def cook(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'做{name}')time.sleep(4)print('饭已做好')
def clean(a,b,c):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'打扫{a},{b},{c}')time.sleep(4)print('打扫完成')
def play(name):# 使用os模块获取当前进程编号num = os.getpid()print(f'当前进程编号{num}')
print(f'玩{name}游戏')
if __name__ == '__main__':
# 创建线程t1 = Thread(target=cook,args=['梅菜扣肉'])t2 = Thread(target=clean,kwargs={'a':'客厅','b':'厨房','c':'卧室'})t3 = Thread(target=play,args=['魔兽世界'])
t1.start()
t2.start()
t3.start()
num = os.getpid()print(f'当前进程编号{num}')
线程执行任务顺序保证
线程的执行顺序也是无序的,如果需要保证线程执行顺讯也是通过join保证
from threading import Thread
import os
def sing(username,singname):print(f'线程1的编号{os.getpid()}')print(f'唱{username}的{singname}歌')
def dance(name):print(f'线程2的编号{os.getpid()}')print(f'跳{name}舞')
def tanzou():print(f'线程3的编号{os.getpid()}')print('弹吉他')
if __name__ == '__main__':# 创建线程传递参数t1 = Thread(target=sing,kwargs={'username':'凤凰传奇','singname':'月亮之上'})t2 = Thread(target=dance,args=['圆桌舞'])t3 = Thread(target=tanzou)
t1.start()t1.join()t2.start()t2.join()t3.start()t3.join()
线程键共享数据
多个线程是在一个进程下运行,他们可以使用同一个进程下的资源
from threading import Thread
a = 1def func1():global aa = a + 1print(f'线程中的a:{a}')def func2():global aa = a + 1print(f'线程中的a:{a}')if __name__ == '__main__':# 创建进程t1 = Thread(target=func1)t2 = Thread(target=func2)t1.start()t2.start()print(f'主进程中的a:{a}')
当共享数据是,多个线程操作同一个数据,那么有可能会因为资源抢占造成计算错误
可以通过join保证数据能完整计算
from threading import Thread
a = 0def func1():global afor i in range(1000000):a = a + 1print(f'func1线程中的a:{a}')def func2():global afor i in range(1000000):a = a + 1print(f'func2线程中的a:{a}')if __name__ == '__main__':# 创建进程t1 = Thread(target=func1)t2 = Thread(target=func2)t1.start()t1.join()t2.start()t2.join()print(f'主进程中的a:{a}')
5-多任务总结
进程和线程
进程是分配资源的最小单元 线程是执行任务的最小单元
实现多任务可以使用多进程或多线
为什么要使用多任务?
提升计算效率,当cpu资源充足是,可以实现多个任务同时执行。
后续spark底层实现采用的多线程方式,spark计算效率很高。spark已经封装实现,开发不需要写多线程。
mapreduce的计算是使用多进程方式实现多任务
实际开发为什么不用多进程实现多任务?更多是采用多线程?
创建进程的开销加大,创建时间长。每创建一个进程都需要额外有计算机分配资源,分配资源也会耗费时间
多进程间不共享数据
多线程会共享数据,如果发生资源抢占会造成数据计算错误
主进程会等到所有任务结束后再结束
二、闭包
在一个函数中定义一个新的函数,把内部函数 当成返回值进行返回,就是一个闭包
使用闭包是为了保存函数的中的局部变量数据
默认情况下 函数执行结束后,内部的局部变量对应的数据会被清除
想保留数据就需要借助闭包
# 局部变量的销毁问题def func():# 局部变量a = 10a = a+1print(a)func() # 函数调用结束后内部局部变量会自动销毁
func() # 第二次调用函数时,会重新定义局部变量,重新计算print('---------------------------')
# 使用闭包可以将局部变量保存下来,每次调用函数时,使用同一个局部变量操作
# 闭包的格式是函数的嵌套定义
def func1():# 定义局部变量a = 10def func2():# 内部声明局部变量nonlocal aa = a+1print(a)# 将内部定义的函数名返回return func2f2 = func1() # f2=func2
# 使用加法计算
f2()
f2()
定义闭包
1-要有函数嵌套定义
2-必须将内部函数的名称返回
使用闭包的场景
1-计数器
2-装饰器
三、装饰器
在不改变原有函数的基础上增加新的业务逻辑
1-闭包
2-函数可以当成参数传递
# 使用闭包定义装饰器
def func1(f):# 外部函数定义接受参数,参数的类型要求是其他函数# f需要接受其他函数,就是需要装饰修改逻辑的函数def func2():# 调用之前增加登录判断print('登录成功')# 调用需要修改执行的函数f()# 返回内部函数return func2# 支付功能已经编写完成,不能再随意修改,如果此时需要再支付中增加一个登录判断如何实现
def pay():print('支付')
# 调用装饰器
f2 = func1(pay) # f=pay f2 = func2
f2()def order():print('下单')
-
被装饰的函数数据返回
def login(f):"""登录装饰器:param f: 接收被装饰的函数:return:"""def inner(name, password):# 编写登录逻辑if name == '张三':if password == '123456':print('登录成功')# 登录成执行被装饰的函数# 可以给传递数据和接收返回值res= f(1000)print(res)else:print('密码错误')else:print('用户名错误')return innerdef pay(price):print('订单支付逻辑')print(f'支付金额{price}')return '支付成功'# 使用装饰器装饰支付函数
f = login(pay)
# f = inner
f('张三','123456')
-
采用语法糖格式使用装饰器
-
语法糖格式 @装饰器函数名
-
def login(f):"""登录装饰器:param f: 接收被装饰的函数:return:"""def inner(name, password,price):# 编写登录逻辑if name == '张三':if password == '123456':print('登录成功')# 登录成执行被装饰的函数res= f(price)print(res)else:print('密码错误')else:print('用户名错误')return inner# 使用语法糖
@login
def pay(price):print('订单支付逻辑')print(f'支付金额{price}')return '支付成功'# 调用被装饰的函数
# 此时pay函数变成了inneer函数
pay('张三','123456',1000)
四、正则
采用正则的方式匹配字符串的中的数据,可以进行数据的判断或则获取数据
在读取文件数据时,文件中都是字符串,可以使用正则匹配。
正则最多的应用是爬虫
爬虫会爬取网络中的数据,数据是字符串类型,需要提取字符串中的数据
使用正则处理字符串数据需要导入对应的模块
import re
# match的匹配是从首字符开始匹配 从左到右一次匹配字符串中的每个字符
r=re.match('匹配数据的规则','匹配的数据本身,类型是字符')
# 获取匹配结果
data = r.group()
print(data)
匹配单个字符
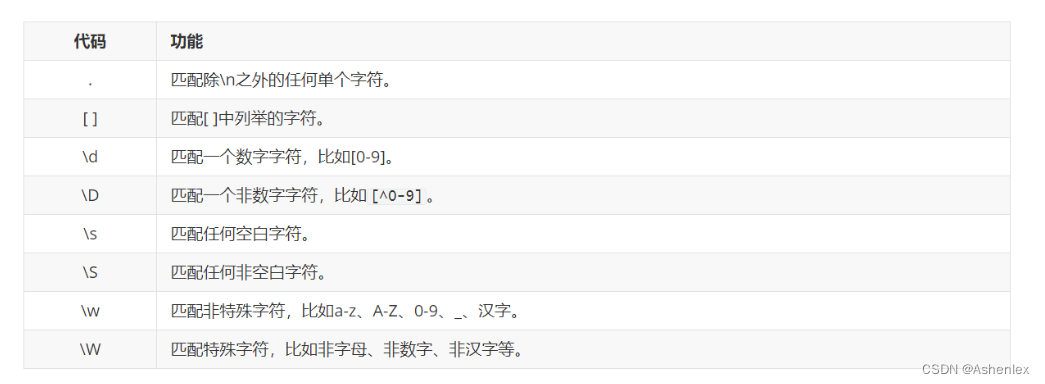
# 使用正则匹配单个字符
import re
# 需要匹配的数据,类型是字符串
data = '!123itcast'
# .的匹配 匹配非\n
r = re.match('.',data)
# 获取匹配的数据
res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
print(f'. 的正则匹配结果:{res}')# [] 匹配 可以在括号写多个匹配字符 a-z 匹配所有小写字母
r = re.match('[a-zA-Z0-9!]',data)
# 获取匹配的数据
res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
print(f'[] 的正则匹配结果:{res}')# \d 匹配数字
# r = re.match('\d',data)
# # 获取匹配的数据
# res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
# print(f'\d 的正则匹配结果:{res}')# \D
r = re.match('\D',data)
# 获取匹配的数据
res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
print(f'\D 的正则匹配结果:{res}')data_str2 = ' itcast'
r = re.match('\s',data_str2)
# 获取匹配的数据
res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
print(f'\s 的正则匹配结果:{res}')data_str3 ='你好'
r = re.match('\w',data_str3)
# 获取匹配的数据
res = r.group()# 如果匹配到数据则返回结果 如果匹配不到则会报错
print(f'\w 的正则匹配结果:{res}')
匹配多个字符
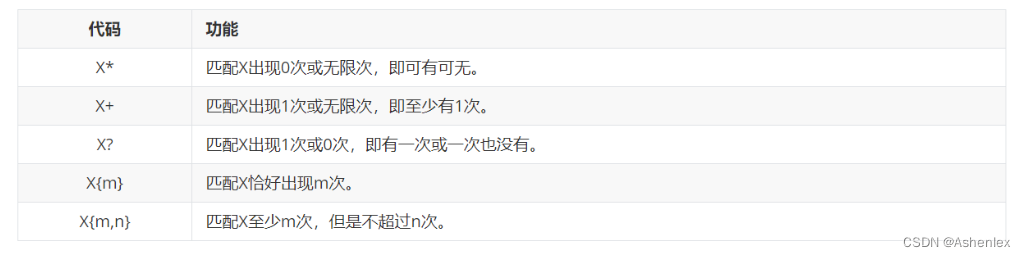
# 匹配多个字符
import re
# 书写方法 匹配规则+ 匹配规则* ...data_str = 'itc99ast99python'
# 使用* 匹配多个字符
# 只要符合匹配规则会一直连续匹配
# * 匹配不到 返回空字符
r = re.match('\d*',data_str)
res = r.group()
print(res)# 使用+匹配多个字符
# 只要符合匹配规则会一直连续匹配
# + 匹配不到 报错
r = re.match('\D+',data_str)
res = r.group()
print(res)# {}指定匹配的字符串个数
r = re.match('\D{3}',data_str)
res = r.group()
print(res)# {m,n}
r = re.match('\D{2,4}',data_str)
res = r.group()
print(res)
分组匹配

data_email1 = '1928738@qq.com'
data_email2 = 'jqiowe@163.com'
data_email3 = 'jqi_wqe@163.com'
# 匹配用户名和邮箱名
r = re.match('(\w*)@(\w*).com',data_email3)
# 取匹配的分组数据
username = r.group(1)
print(username)
emailname = r.group(2)
print(emailname)
这篇关于python基础——-多任务-正则-装饰器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





