本文主要是介绍MOOC 数据结构 | 2. 线性结构(4):应用实例:多项式加法运算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
4. 多项式加法运算
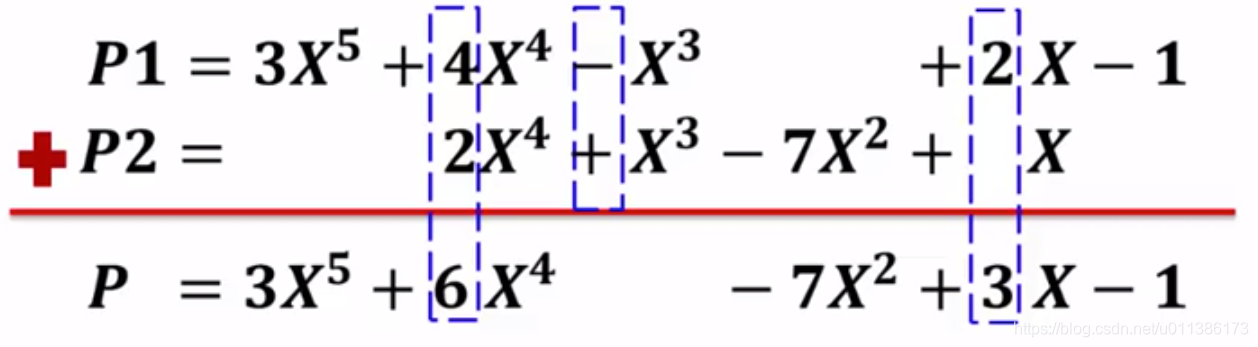
主要思路:相同指数的项系数相加,其余部分进行拷贝。
4.1 多项式相加在计算机中的实现

上述多项式用单向链表表示:
 (每个结点包含系数,指数和指向下一个结点的指针)
(每个结点包含系数,指数和指向下一个结点的指针)
4.2 数据结构定义
struct PolyNode
{int coef; //系数int expon;//指数struct PolyNode *link; //指向下一个结点的指针
};
typedef struct PolyNode *Polynomial;
Polynomial P1,P2;算法思路:两个指针P1和P2分别指向这两个多项式第一个结点,不断循环:
- P1->expon == P2->expon: 系数相加,若结果不为0,则作为结果多项式对应项的系数。同时,P1和P2都分别指向下一项;
- P1->expon > P2->expon:将P1的当前项存入结果多项式,并使P1指向下一项;
- P1->expon < P2->expon:将P2的当前项存入结果多项式,并使P2指向下一项;
当某一多项式处理完时,将另一个多项式的所有结点依次复制到结果多项式中去。
上述两个多项式相加的过程:
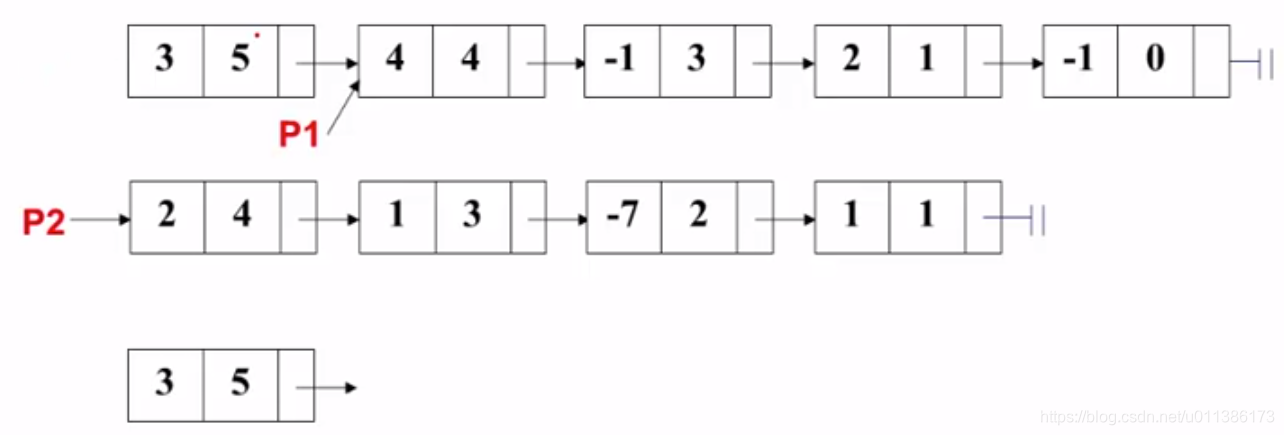
- 初始状态:P1和P2都指向第一个结点

2. 比较第一个结点,P1的指数(5)大于P2的指数(4),P1的当前项拷贝到结果多项式中,P1往后挪:
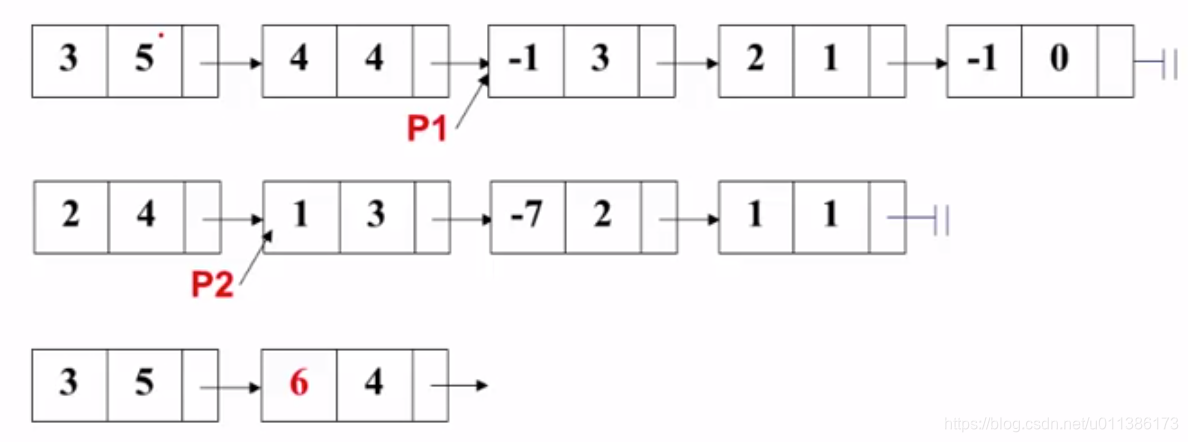
3. 比较P1的第二个结点和P2的第一个结点,指数相同,系数相加,然后将结果拷贝到结果多项式中,P1和P2都往后挪:
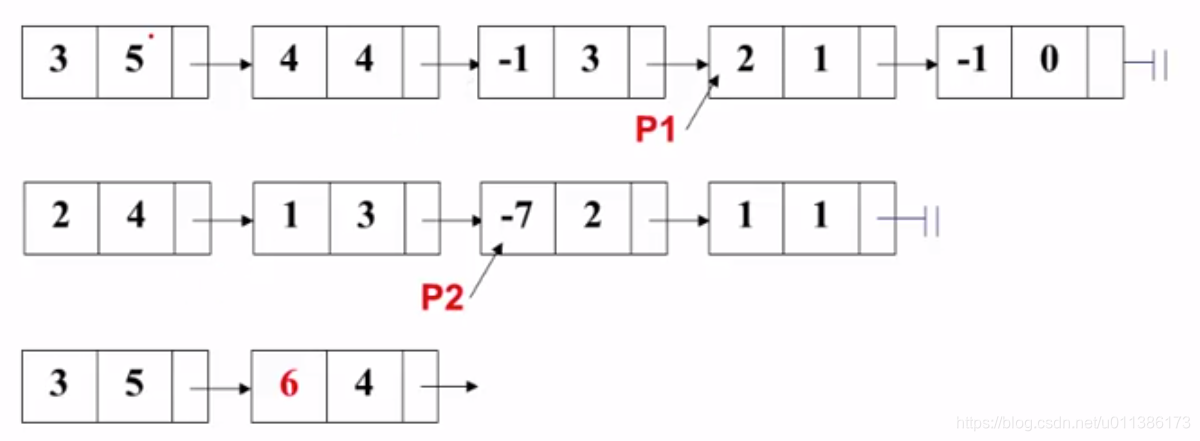
4. 指数相同,系数相加结果为0,不用拷贝,P1和P2同时往后挪:
5. P2指向的结点的指数较大,所以拷贝该项到结果多项式中,P2往后挪:
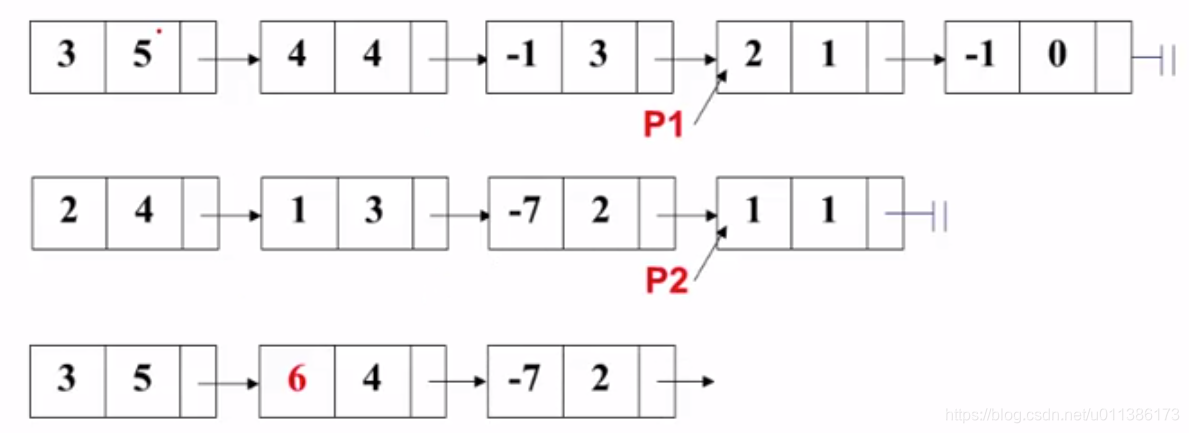
6. 指数相同,系数相加,结果拷贝到结果多项式中,P1和P2都往后挪:
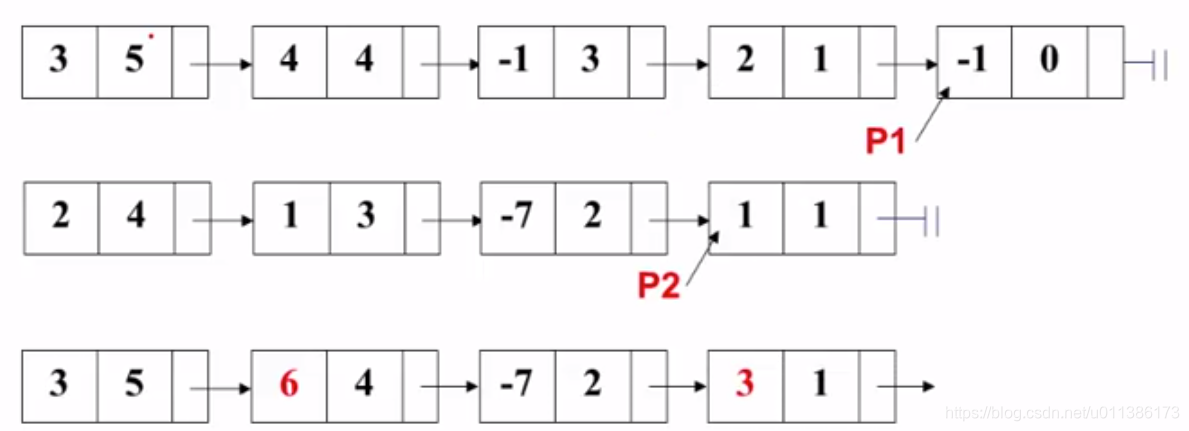
7. 挪了之后P2就为空了,所以就把P1后面的所有结点接到结果多项式中:
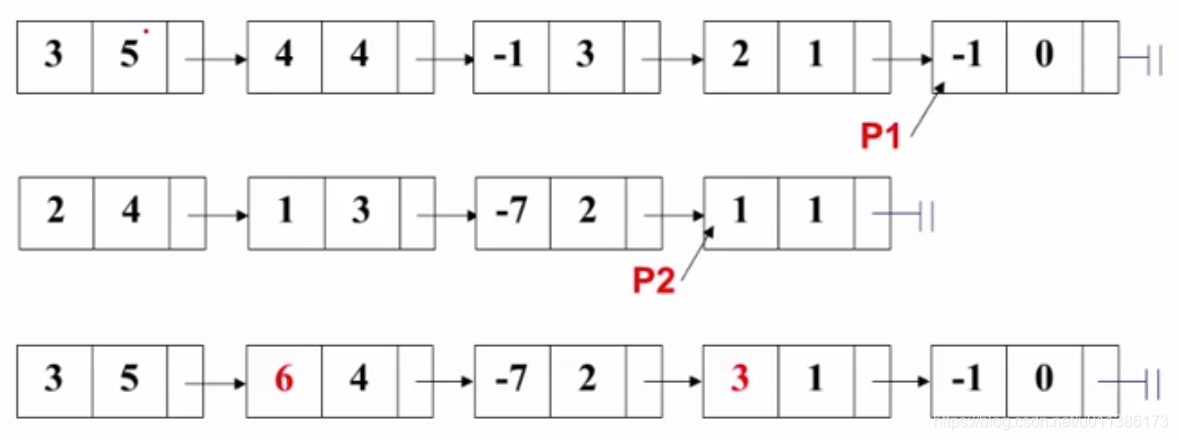
4.3 代码实现
Polynomial PolyAdd(Polynomial P1, Polynomial P2)
{Polynomial front, rear, temp;int sum;rear = (Polynomial)malloc(sizeof(struct PolyNode));front = rear; //由front记录结果多项式链表头结点while(P1 && P2) //当两个多项式都有非零项待处理时{switch(Compare(P1->expon, P2->expon)){case 1: //P1项的指数比较大Attach(P1->coef, P1->expon, &rear);P1 = P1->link;break;case -1:Attach(P2->coef, P2->expon, &rear);P2 = P2->link;break;case 0:sum = P1->coef + P2->coef;if(sum) //系数相加结果不为0Attach(sum, P1->expon, &rear);P1 = P1->link;P2 = P2->link;break;}}//将未处理完的另一个多项式的所有结点依次复制到结果多项式中去for( ; P1; P1 = P1->link)Attach(P1->coef, P1->expon, &rear);for( ; P2; P2 = P2->link)Attach(P2->coef, P2->expon, &rear);rear->link = NULL;temp = front;front = front->link; //令front指向结果多项式第一个非零项free(temp); //释放临时空表头结点return front;
}//pRear其实是指针的指针,之所以这么做是因为C语言函数参数值传递
void Attach(int c, int e, Polynomial *pRear)
{Polynomial P;P = (Polynomial)malloc(sizeof(struct PolyNode));P->coef = c; //对新结点赋值P->expon = e;P->link = NULL;(*pRear)->link = P;*pRear = P; //修改*pRear值
}示意图:
1、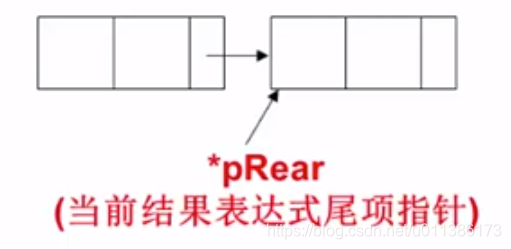
2、来了个新结点P,要将其链接到*pRear后:

3、
4、
这篇关于MOOC 数据结构 | 2. 线性结构(4):应用实例:多项式加法运算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





