本文主要是介绍fabirc1.0商业正式版本源码解析2——peer命令结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
peer目录结构
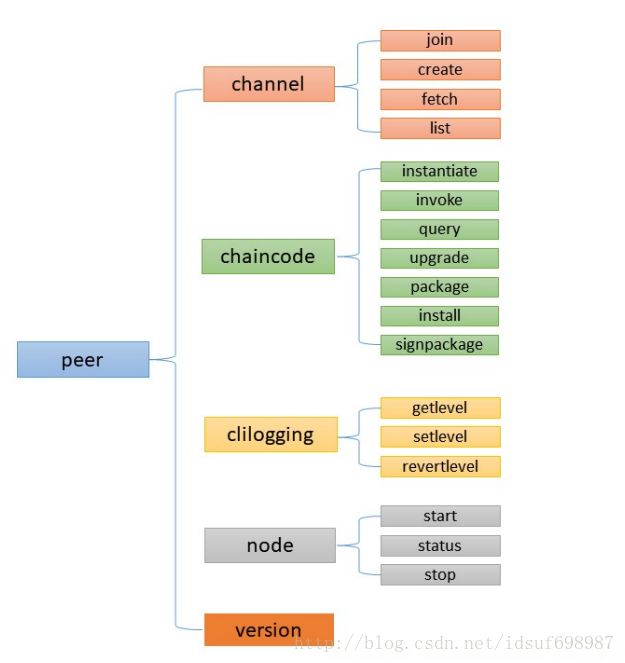
peer目录结构自身十分清晰,一个main.Go文件,其余文件夹除common,gossip外均为子命令集合,有chaincode,channel,clilogging,node,version五个,各司其职,供main.go整合使用。子命令文件夹中,与文件夹名称相同的.go文件为主要源码文件,其余的均为按功能划分的动作命令源码。以node目录为例,node自身作为根命令的一个子命令,在node.go中实现,而node这个命令自身又有start,status,stop这三个动作去执行不同的任务,分别在对应start.go,status.go,stop.go中实现。注意,start,status,stop其实也是子命令,是node这个子命令的子命令,因为他们是在命令层级中最终去干活的底层的人,我觉得用动作去形容他们更贴切一些。
- chaincode
- channel
- clilogging
- common
- gossip
- node
- node.go
- start.go
- status.go
- stop.go
- version
- main.go
第三方包
在Getting Started中,无论是在启动peer容器时默认执行的命令,还是手工执行交易时在终端窗口所输入的命令,都类有类似的格式,如peer channel…,peer node…,peer chaincode…,这种 命令+子命令+选项 的风格,让人在感觉上毫无违和感。peer命令主要依赖第三方包github.com/spf13/cobra,由其组成基本的peer命令架构。所以在此简单介绍一下cobra。
cobra既是一个用于生成命令行程序的库,也是用来生成程序和命令文件的程序(即在命令行用cobra命令进行一系列操作,格式化生成一些使用cobra框架的源代码文件,用户可在此基础上进行编程)。目前,peer源码只将cobra当作一个库进行使用。cobra基本用法如下:
- 创建一个(根)命令对象,其原型为Command,每个命令都是一个Command对象实例。创建命令对象其实就是填充Command中的成员的过程罢了。需要注意的是,Command中的成员还有很多,其中有一批字段名为*Run,*RunE形式的成员,其作用与Run类似,区别在于运行的时间有先有后,是否被子命令继承,是否返回错误。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 如果有需要,对命令的添加flag,这一点可以简单的理解为命令选项。
- 1
- 2
- 1
- 2
- 如果有需要,对根命令添加子命令,子命令与根命令本质是一样的,只是人为的进行级别上的区分。
- 1
- 1
- 运行命令。
- 1
- 1
由于文章重点在peer,所以在此只做简单介绍,更详细的使用方法,可在go doc或github.com/spf13/cobra上学习。其实阅读fabric源码过程中有一个感觉,就是项目的大神们选用的第三方库,一般都是既满足需求,又比较容易学习和上手。
peer命令结构解析
我们现在正式从peer/main.go文件开始解析源码,本文旨在解析peer的命令结构,因此只会涉及相关的源码,其他部分将会在其他主题文章中对应分析。如果你对cobra的用法稍微熟悉后,很容易就可以看懂main函数的构建。peer目录下的子命令的源码结构非常类似,也基本逃不出上文介绍的关于cobra的基本操作。
-
首先定义了一个mainCmd命令,var mainCmd = &cobra.Command{…},该命令填充了Use,PersistentPreRunE和Run成员。Use如我们预见的那样被赋值为peer,PersistentPreRunE先于Run执行,都被赋值了一个匿名函数。因为mainCmd只单纯作为根命令,不实现由子命令实现的具体的交易事务,因此实现的只是PersistentPreRunE指定的检查、初始化日志系统并缓存配置的功能,和Run指定的版本打印、命令帮助功能
-
生成mainCmd对象的命令行标识对象mainFlags,mainFlags := mainCmd.PersistentFlags(),也就是peer命令的选项,并对该标识对像进行了维护,增加了version,logging_level两个选项。这也对应了其在自身对象中设置PersistentPreRunE和Run的功能。
-
添加子命令,mainCmd.AddCommand(…)。添加的命令有version.Cmd(),node.Cmd(),chaincode.Cmd(nil),clilogging.Cmd(nil),channel.Cmd(nil)五个。Cmd()是每个子命令文件中暴露出的函数,各自整合了各自的动作命令。
-
启动根命令,mainCmd.Execute()。启动了根命令,也就启动了其下的所有命令。
子命令结构解析,以node为例
其实读懂了peer命令,其余的子命令类推即可。在此还是啰嗦两句吧。上文已经说了子命令的源码结构是极其相似的,这里只以node为例。
-
在node.go中,首先定义了一个node命令对象,var nodeCmd = &cobra.Command{…}
-
在Cmd函数中,添加了startCmd(),statusCmd(),stopCmd()三个函数返回的start,status,stop子命令(动作命令),分别实现在start.go,status.go,stop.go。这三个命令的源码结构也是基本一致,在此仅以start和start.go为例。
-
在start.go中,首先定义了一个start命令对象,var nodeStartCmd = &cobra.Command{…},其中对RunE成员赋值了一个匿名函数,函数体中执行了serve函数,这也是该命令最终会调用的函数。serve函数是一个非常重要,非常复杂的函数。记不记得在上篇介绍Fabric项目线头的文章提到过的,在每个peer容器启动后默认执行的就是peer node start –peer-defaultchain=false命令,在此处就对接上了,该命令最终调用执行的就是serve函数,同时也就是说,serve函数会做了很多很多的准备工作。
peer命令结构
这篇关于fabirc1.0商业正式版本源码解析2——peer命令结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








