本文主要是介绍现在有一个生产计划,甲乙丙3个品类共16个产品,生产时间6天,每天甲品类可以生产1张单,乙3张,丙1张,请用MySQL写出H列的效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在有一个生产计划,甲乙丙3个品类共16个产品,生产时间6天,每天甲品类可以生产1张单,乙3张,丙1张,请用MySQL写出H列的效果吗?
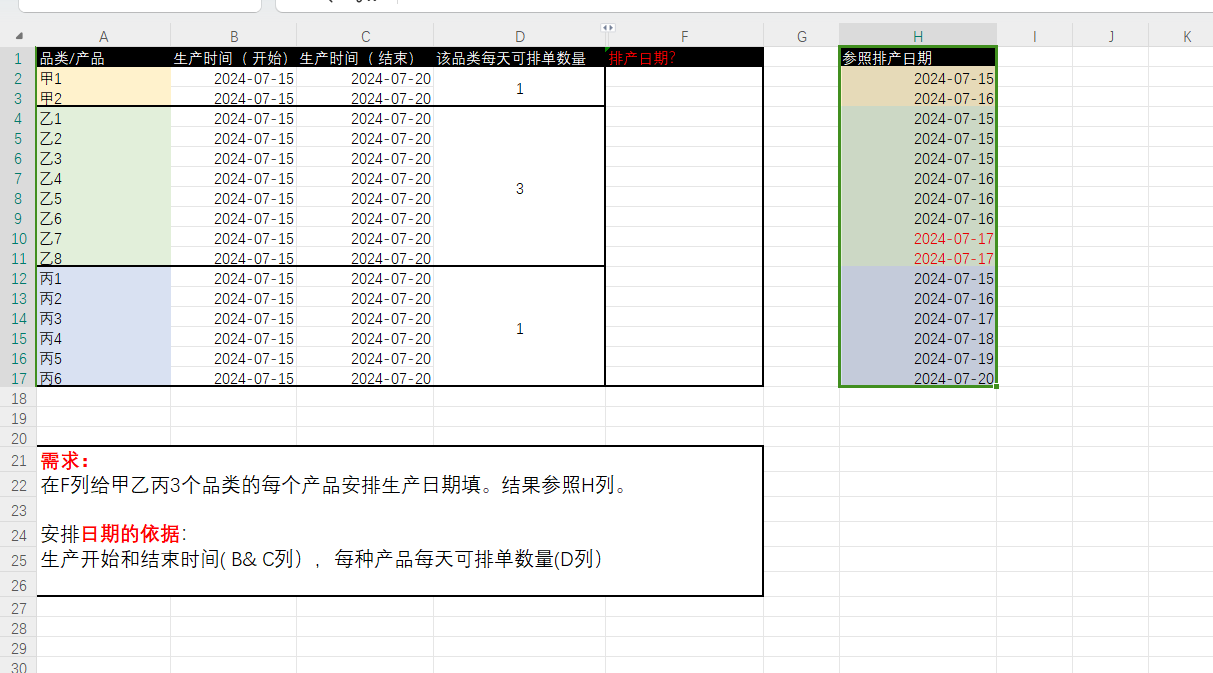
最终展示结果要求为:
| 品类产品 | 生产时间开始 | 生产时间结束 | 该品类每天可排单数量 | 参照排产日期 |
|---|---|---|---|---|
| 甲1 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-15 |
| 甲2 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-16 |
| 乙1 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙2 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙3 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙4 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙5 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙6 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙7 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-17 |
| 乙8 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-17 |
| 丙1 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-15 |
| 丙2 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-16 |
| 丙3 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-17 |
| 丙4 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-18 |
| 丙5 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-19 |
| 丙6 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-20 |
解决办法:
1、进行数据拆解:
| 品类产品 | 生产时间开始 | 生产时间结束 | 该品类每天可排单数量 |
|---|---|---|---|
| 甲1 | 2024-07-15 | 2024-07-20 | 1 |
| 甲2 | 2024-07-15 | 2024-07-20 | 1 |
| 乙1 | 2024-07-15 | 2024-07-20 | 3 |
| 乙2 | 2024-07-15 | 2024-07-20 | 3 |
| 乙3 | 2024-07-15 | 2024-07-20 | 3 |
| 乙4 | 2024-07-15 | 2024-07-20 | 3 |
| 乙5 | 2024-07-15 | 2024-07-20 | 3 |
| 乙6 | 2024-07-15 | 2024-07-20 | 3 |
| 乙7 | 2024-07-15 | 2024-07-20 | 3 |
| 乙8 | 2024-07-15 | 2024-07-20 | 3 |
| 丙1 | 2024-07-15 | 2024-07-20 | 1 |
| 丙2 | 2024-07-15 | 2024-07-20 | 1 |
| 丙3 | 2024-07-15 | 2024-07-20 | 1 |
| 丙4 | 2024-07-15 | 2024-07-20 | 1 |
| 丙5 | 2024-07-15 | 2024-07-20 | 1 |
| 丙6 | 2024-07-15 | 2024-07-20 | 1 |
-- 创建表
CREATE TABLE produces (`品类/产品` VARCHAR(10),`生产时间(开始)` DATE,`生产时间(结束)` DATE,`该品类每天可排单数量` INT
);-- 插入数据
INSERT INTO produces (`品类/产品`, `生产时间(开始)`, `生产时间(结束)`, `该品类每天可排单数量`) VALUES
('甲1', '2024-07-15', '2024-07-20', 1),
('甲2', '2024-07-15', '2024-07-20', 1),
('乙1', '2024-07-15', '2024-07-20', 3),
('乙2', '2024-07-15', '2024-07-20', 3),
('乙3', '2024-07-15', '2024-07-20', 3),
('乙4', '2024-07-15', '2024-07-20', 3),
('乙5', '2024-07-15', '2024-07-20', 3),
('乙6', '2024-07-15', '2024-07-20', 3),
('乙7', '2024-07-15', '2024-07-20', 3),
('乙8', '2024-07-15', '2024-07-20', 3),
('丙1', '2024-07-15', '2024-07-20', 1),
('丙2', '2024-07-15', '2024-07-20', 1),
('丙3', '2024-07-15', '2024-07-20', 1),
('丙4', '2024-07-15', '2024-07-20', 1),
('丙5', '2024-07-15', '2024-07-20', 1),
('丙6', '2024-07-15', '2024-07-20', 1);-- 确认数据插入
SELECT * FROM produces;最终SQL:
-- 使用WITH子句创建CTE
WITH scheduled_producet AS (SELECT 品类产品, 生产时间开始, 生产时间结束, 该品类每天可排单数量,DATE_ADD(生产时间开始, INTERVAL FLOOR((@row_num := IF(@current_category = SUBSTRING(品类产品, 1, 1), @row_num + 1, 0)) / 该品类每天可排单数量) DAY) AS 参照排产日期,@current_category := SUBSTRING(品类产品, 1, 1) AS dummy,@row_order := @row_order + 1 AS row_orderFROM produces, (SELECT @row_num := -1, @current_category := '', @row_order := 0) AS varsORDER BY row_order
)-- 查询CTE
SELECT 品类产品, 生产时间开始, 生产时间结束, 该品类每天可排单数量, 参照排产日期
FROM scheduled_producet
ORDER BY row_order;
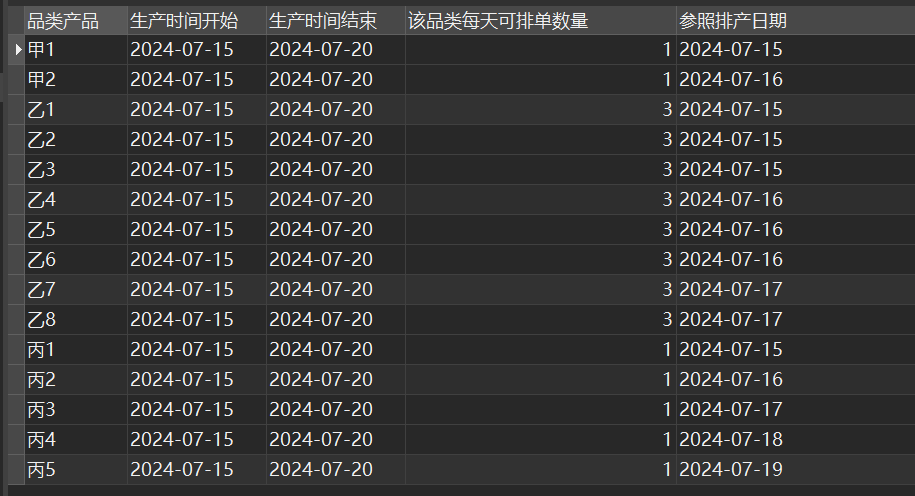
完美解决!跟想要的效果一模一样!!!
| 品类产品 | 生产时间开始 | 生产时间结束 | 该品类每天可排单数量 | 参照排产日期 |
|---|---|---|---|---|
| 甲1 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-15 |
| 甲2 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-16 |
| 乙1 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙2 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙3 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-15 |
| 乙4 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙5 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙6 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-16 |
| 乙7 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-17 |
| 乙8 | 2024-07-15 | 2024-07-20 | 3 | 2024-07-17 |
| 丙1 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-15 |
| 丙2 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-16 |
| 丙3 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-17 |
| 丙4 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-18 |
| 丙5 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-19 |
| 丙6 | 2024-07-15 | 2024-07-20 | 1 | 2024-07-20 |
(看不懂的上面SQL的,可以看下面的注释)
注释:
-- 使用WITH子句创建CTE
WITH scheduled_producet AS (-- 这是一个CTE(公用表表达式)的定义开始,它将被命名为`scheduled_producet`。SELECT 品类产品, 生产时间开始, 生产时间结束, 该品类每天可排单数量,-- 选择所需的列。DATE_ADD(生产时间开始, INTERVAL FLOOR((@row_num := IF(@current_category = SUBSTRING(品类产品, 1, 1), @row_num + 1, 0)) / 该品类每天可排单数量) DAY) AS 参照排产日期,-- 这行代码使用DATE_ADD函数和INTERVAL来计算参照排产日期。-- FLOOR函数向下取整,用于确定在给定的每天可排单数量下,需要多少天来安排生产。-- @row_num是一个用户定义的变量,用来追踪当前产品类别的行号。-- IF函数检查当前的产品类别是否与上一个相同,如果是,则@row_num增加,否则重置为0。-- 参照排产日期是基于生产时间开始和行号计算的。@current_category := SUBSTRING(品类产品, 1, 1) AS dummy,-- 这行代码设置一个用户定义的变量@current_category为当前产品的类别首字母。-- 'dummy'是一个别名,通常用于不需要的SELECT列,但在这里它用于设置变量。@row_order := @row_order + 1 AS row_order-- 这行代码定义了一个用户定义的变量@row_order,用来为每一行分配一个顺序编号。FROM produces, -- 从`produces`表中选择数据。(SELECT @row_num := -1, @current_category := '', @row_order := 0) AS vars-- 这是一个子查询,用于初始化用户定义的变量。ORDER BY row_order-- 根据行号对结果进行排序。
)-- 查询CTE
SELECT 品类产品, 生产时间开始, 生产时间结束, 该品类每天可排单数量, 参照排产日期
FROM scheduled_producet
-- 从CTE `scheduled_producet`中选择数据。ORDER BY row_order;
-- 根据行号对查询结果进行排序。
这篇关于现在有一个生产计划,甲乙丙3个品类共16个产品,生产时间6天,每天甲品类可以生产1张单,乙3张,丙1张,请用MySQL写出H列的效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







