本文主要是介绍springboot集成uid-gengrator生成分布式id,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
uid-generator是由百度技术部开发,GitHub地址
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器
Snowflake算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
| sign(1bit) | 固定1bit符号标识,即生成的UID为正数。 |
|---|---|
| delta seconds (28 bits) | 当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 |
| worker id (22 bits) | 机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 |
| sequence (13 bits) | 每秒下的并发序列,13 bits可支持每秒8192个并发。 |
二、使用Spring boot项目集成uid-generator
2.1 将项目下载之后生成文件

下载完成后使用IDEA打开

复制生成的文件夹到maven仓库

我的maven仓库安装到了d盘
之后就可以使用标签引入了
2.2项目中引入uid-generator依赖,并排除其中的mybatis依赖
如果项目是SpringBoot+Mybatisplus,UidGenerator是Spring+Mybatis,直接引入uid-generator之后,本地项目启动就会出现创建SqlSessionFactory报错,所以,直接将uid-generator中的mybatis相关依赖排除。避免出现不必要的启动问题
<dependency><groupId>com.baidu.fsg</groupId><artifactId>uid-generator</artifactId><version>1.0.0-SNAPSHOT</version><exclusions><exclusion><groupId>org.mybatis</groupId><artifactId>*</artifactId></exclusion></exclusions>
</dependency>2.3 创建数据库表
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
2.4 生成实体类与mapper
2.4.1实体类
import java.util.Date;public class WorkerNode {private Long id;private String hostName;private String port;private Integer type;private Date LaunchDate;private Date modified;private Date created;public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getHostName() {return hostName;}public void setHostName(String hostName) {this.hostName = hostName;}public String getPort() {return port;}public void setPort(String port) {this.port = port;}public Integer getType() {return type;}public void setType(Integer type) {this.type = type;}public Date getLaunchDate() {return LaunchDate;}public void setLaunchDate(Date launchDate) {LaunchDate = launchDate;}public Date getModified() {return modified;}public void setModified(Date modified) {this.modified = modified;}public Date getCreated() {return created;}public void setCreated(Date created) {this.created = created;}@Overridepublic String toString() {return "WorkerNode{" +"id=" + id +", hostName='" + hostName + '\'' +", port='" + port + '\'' +", type=" + type +", LaunchDate=" + LaunchDate +", modified=" + modified +", created=" + created +'}';}
}2.4.2 mapper与mapper.xml
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;@Mapper
public interface WorkerNodeMapper {int addWorkerNode(WorkerNode workerNodeEntity);WorkerNode getWorkerNodeByHostPort(@Param("host") String host, @Param("port") String port);}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lq.mapper.WorkerNodeMapper"><resultMap id="BaseResultMap"type="com.lq.entity.pojo.WorkerNode"><id column="ID" jdbcType="BIGINT" property="id" /><result column="HOST_NAME" jdbcType="VARCHAR" property="hostName" /><result column="PORT" jdbcType="VARCHAR" property="port" /><result column="TYPE" jdbcType="INTEGER" property="type" /><result column="LAUNCH_DATE" jdbcType="DATE" property="launchDate" /><result column="MODIFIED" jdbcType="TIMESTAMP" property="modified" /><result column="CREATED" jdbcType="TIMESTAMP" property="created" /></resultMap><insert id="addWorkerNode" useGeneratedKeys="true" keyProperty="id"parameterType="com.lq.entity.pojo.WorkerNode">INSERT INTO WORKER_NODE(HOST_NAME,PORT,TYPE,LAUNCH_DATE,MODIFIED,CREATED)VALUES (#{hostName},#{port},#{type},#{launchDate},NOW(),NOW())</insert><select id="getWorkerNodeByHostPort" resultMap="BaseResultMap">SELECTID,HOST_NAME,PORT,TYPE,LAUNCH_DATE,MODIFIED,CREATEDFROMWORKER_NODEWHEREHOST_NAME = #{host} AND PORT = #{port}</select>
</mapper>注:
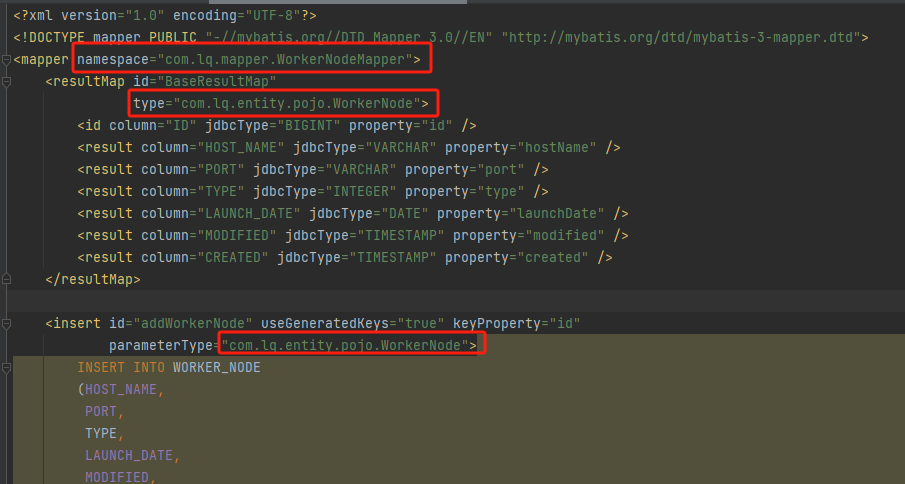
修改对应位置为自己实体类与mapper所在位置
2.5 service与impl
- service
/*** @注释*/
public interface IWorkerNodeService {public long genUid();
}
- serviceimpl
import com.baidu.fsg.uid.UidGenerator;
import com.lq.service.IWorkerNodeService;
import org.springframework.stereotype.Service;import javax.annotation.Resource;/***/
@Service
public class WorkerNodeServiceImpl implements IWorkerNodeService {@Resourceprivate UidGenerator uidGenerator;@Overridepublic long genUid() {return uidGenerator.getUID();}
}
2.6 添加配置类

2.6.1 DisposableWorkerIdAssigner
import com.baidu.fsg.uid.utils.DockerUtils;
import com.baidu.fsg.uid.utils.NetUtils;
import com.baidu.fsg.uid.worker.WorkerIdAssigner;
import com.baidu.fsg.uid.worker.WorkerNodeType;
import org.apache.commons.lang.math.RandomUtils;
import org.springframework.transaction.annotation.Transactional;import javax.annotation.Resource;
import java.util.Date;/***/
public class DisposableWorkerIdAssigner implements WorkerIdAssigner {@Resourceprivate WorkerNodeMapper workerNodeMapper;@Override@Transactionalpublic long assignWorkerId() {WorkerNode workerNode = buildWorkerNode();workerNodeMapper.addWorkerNode(workerNode);return workerNode.getId();}private WorkerNode buildWorkerNode() {WorkerNode workNode = new WorkerNode();if (DockerUtils.isDocker()) {workNode.setType(WorkerNodeType.CONTAINER.value());workNode.setHostName(DockerUtils.getDockerHost());workNode.setPort(DockerUtils.getDockerPort());workNode.setLaunchDate(new Date());} else {workNode.setType(WorkerNodeType.ACTUAL.value());workNode.setHostName(NetUtils.getLocalAddress());workNode.setPort(System.currentTimeMillis() + "-" + RandomUtils.nextInt(100000));workNode.setLaunchDate(new Date());}return workNode;}
}
2.6.2 WorkerNodeConfig
import com.baidu.fsg.uid.UidGenerator;
import com.baidu.fsg.uid.impl.CachedUidGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/** */
@Configuration
public class WorkerNodeConfig {@Bean("disposableWorkerIdAssigner")public DisposableWorkerIdAssigner disposableWorkerIdAssigner(){return new DisposableWorkerIdAssigner();}@Bean("cachedUidGenerator")public UidGenerator uidGenerator(DisposableWorkerIdAssigner disposableWorkerIdAssigner){CachedUidGenerator cachedUidGenerator = new CachedUidGenerator();cachedUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);return cachedUidGenerator;}
}
2.7 测试
import com.lq.service.IWorkerNodeService;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;/***/
@SpringBootTest
public class UidGenerateTest {@Resourceprivate IWorkerNodeService workerNodeService;@Testpublic void getUid() {List<Long> list = new ArrayList<>();for (int i = 0; i < 50; i++) {long uid = workerNodeService.genUid();list.add(uid);}AtomicInteger num = new AtomicInteger();list.forEach(l -> {System.out.println("第" + num.getAndIncrement() + "个id为 = " + l);});}
}

这篇关于springboot集成uid-gengrator生成分布式id的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








