本文主要是介绍基于聚类与统计检验深度挖掘电商用户行为,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.项目背景
在当今竞争激烈的电商市场中,了解用户的行为和需求对于制定成功的市场策略至关重要,本项目通过建立RFM模型、K-Means聚类模型,将1000个用户进行划分,针对不同类的用户,提出不同的营销策略,最后通过统计检验来探究影响用户消费行为的因素和影响用户上网行为的因素,通过这些分析,商家能够更好地理解消费者,从而制定更有效的市场策略,满足用户期望,提升用户体验,最终推动业务发展。
2.数据说明
| 字段 | 说明 |
|---|---|
| User_ID | 每个用户的唯一标识符,便于追踪和分析。 |
| Age | 用户的年龄,提供对人口统计偏好的洞察。 |
| Gender | 用户的性别,使能性别特定的推荐和定位。 |
| Location | 用户所在地区:郊区、农村、城市,影响偏好和购物习惯。 |
| Income | 用户的收入水平,表明购买力和支付能力。 |
| Interests | 用户的兴趣,如运动、时尚、技术等,指导内容和产品推荐。 |
| Last_Login_Days_Ago | 用户上次登录以来的天数,反映参与频率。 |
| Purchase_Frequency | 用户进行购买的频率,表明购物习惯和忠诚度。 |
| Average_Order_Value | 用户下单的平均价值,对定价和促销策略至关重要。 |
| Total_Spending | 用户消费的总金额,表明终身价值和购买行为。 |
| Product_Category_Preference | 用户偏好的特定产品类别。 |
| Time_Spent_on_Site_Minutes | 用户在电子商务平台上花费的时间,表明参与程度。 |
| Pages_Viewed | 用户在访问期间浏览的页面数量,反映浏览活动和兴趣。 |
| Newsletter_Subscription | 用户是否订阅了营销活动通知。 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from scipy import stats
from scipy.stats import spearmanr,pointbiserialr, f_oneway,chi2_contingency
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv(r'D:\Desktop\商业数据分析案例\电商用户行为数据集\user_personalized_features.csv')
4.数据预览
查看数据维度
(1000, 15)
查看数据信息

查看各列缺失值
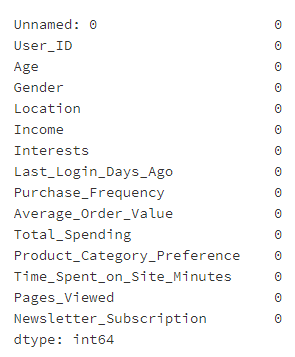
查看重复值
0
查看分类特征的唯一值

绘制箱线图来观察是否存在异常值
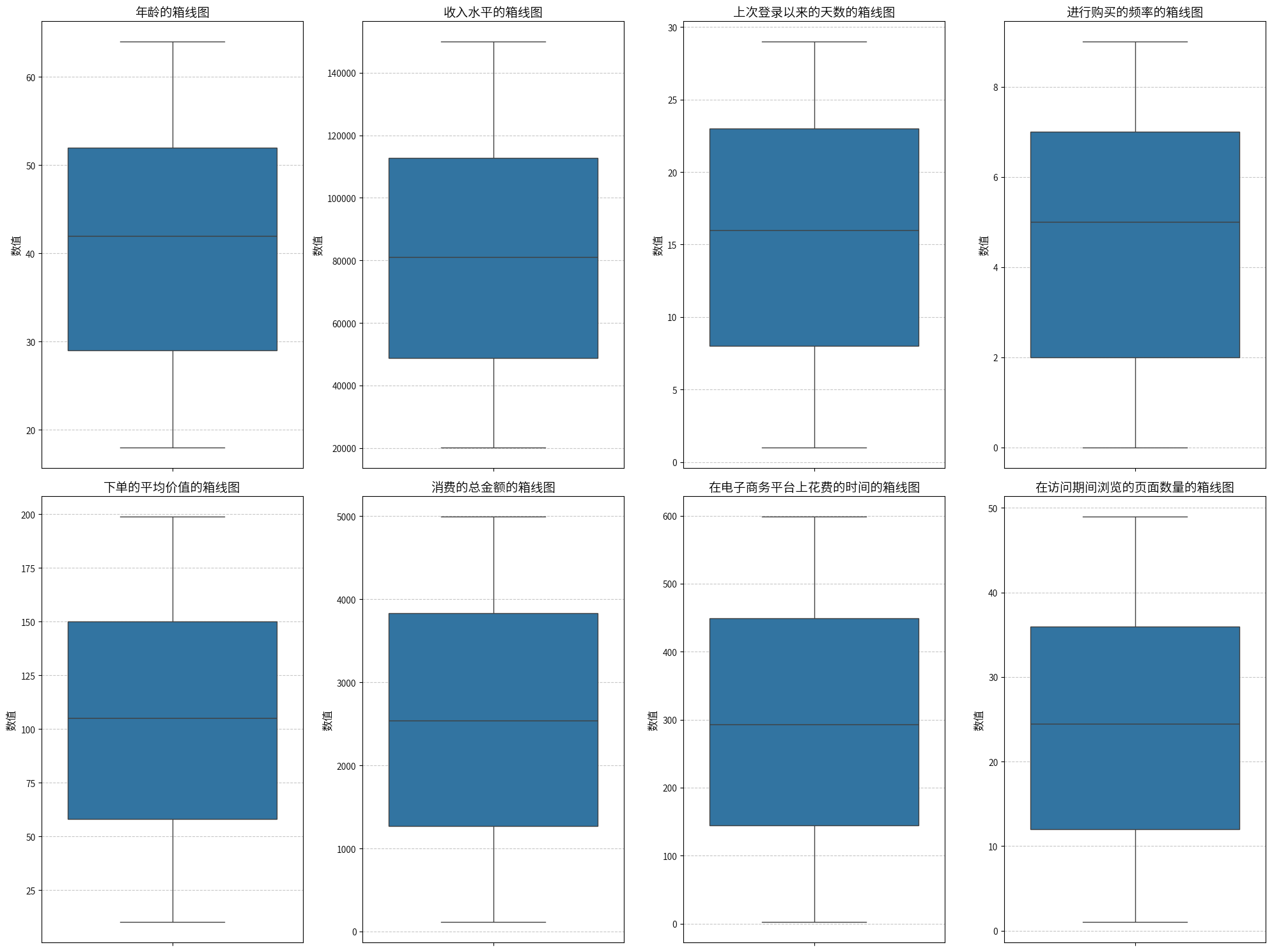
总体来看,数据集的质量较高,没有缺失值、重复值和异常值,分类特征的唯一值分布合理,直接用这个数据进行分析。
5.描述性分析
用户基本信息:

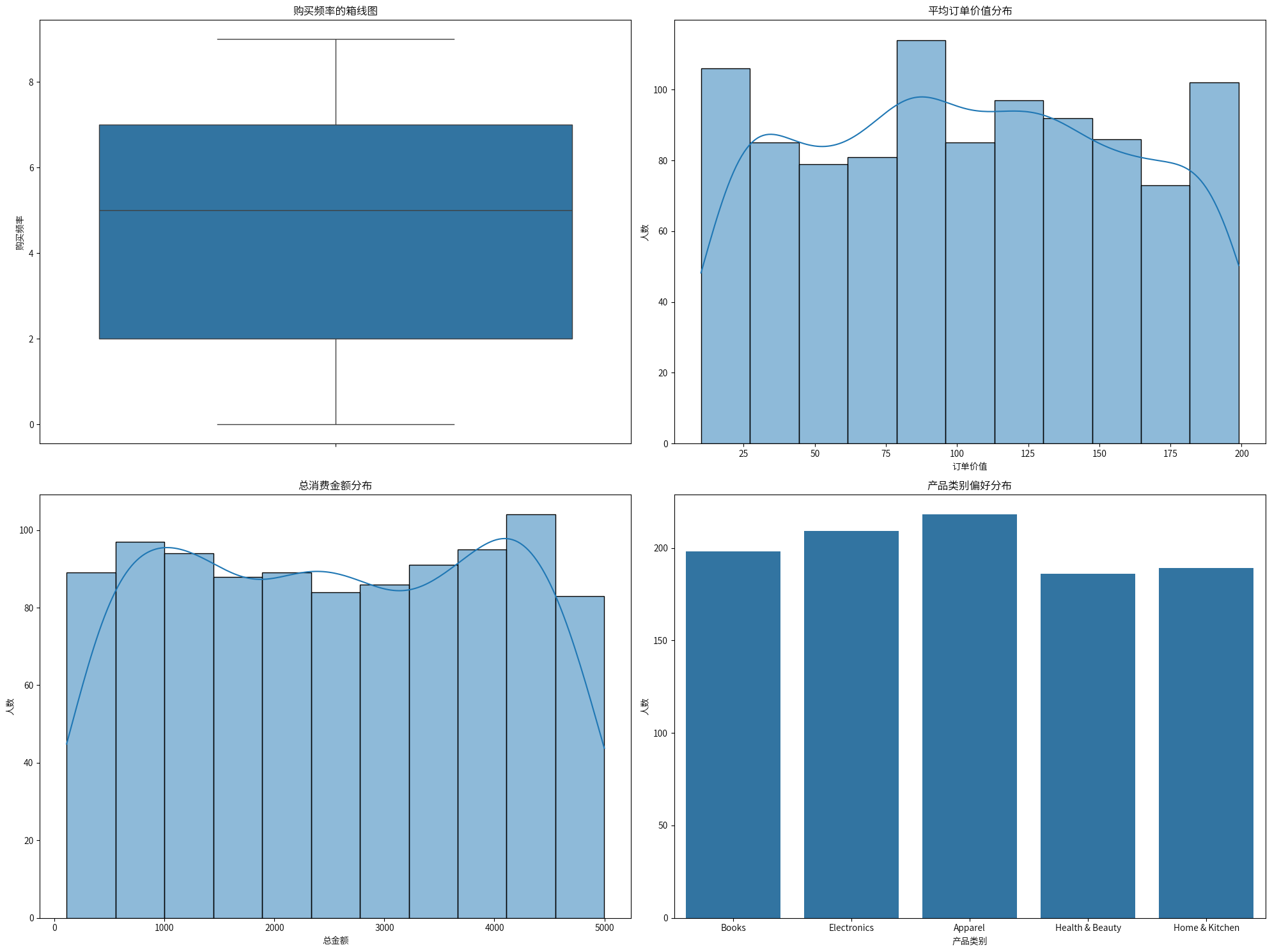
购物行为:
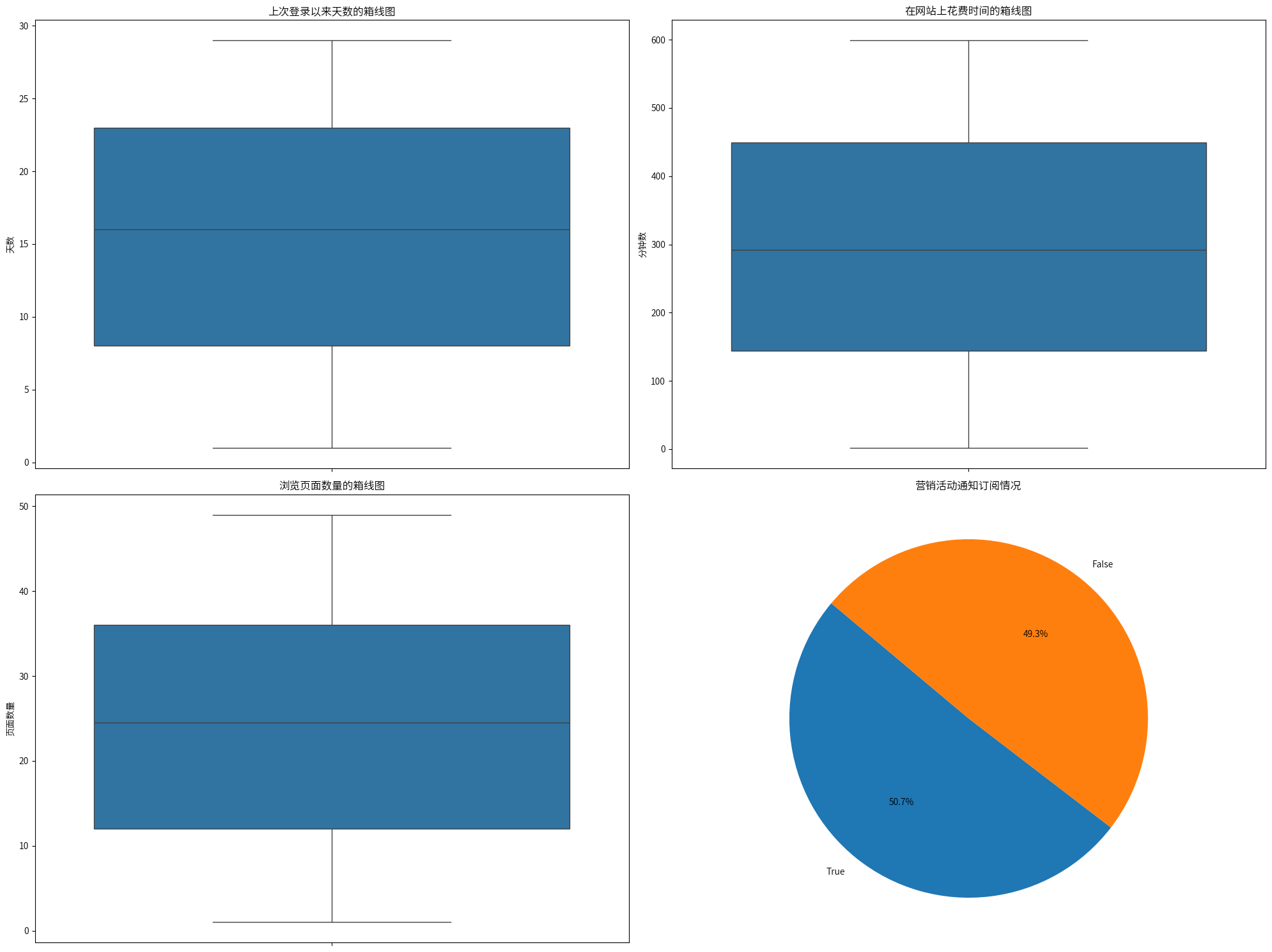
网站使用情况:
这篇关于基于聚类与统计检验深度挖掘电商用户行为的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



