本文主要是介绍【动手学深度学习】多层感知机之暂退法研究详情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!



目录
🌊1. 研究目的
🌊2. 研究准备
🌊3. 研究内容
🌍3.1 多层感知机暂退法
🌍3.2 基础练习
🌊4. 研究体会
🌊1. 研究目的
- 防止过拟合:权重衰减和暂退法都是用来控制模型的复杂度,防止模型在训练集上过拟合;
- 提高模型泛化能力:通过在训练过程中应用权重衰减或暂退法,可以限制模型对训练数据的过度依赖,从而提高模型在未见过的测试数据上的泛化能力;
- 研究正则化效果:权重衰减和暂退法都可以看作是对模型的正则化约束,通过实验可以研究不同的正则化方法对于模型训练和性能的影响;
- 了解特征选择:通过应用权重衰减或暂退法,可以观察到一些权重变得非常小或接近于零。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:

🌍3.1 多层感知机暂退法
代码实现如下:
导入必要库及实现部分
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='mean')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
从零开始实现
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256定义模型
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='mean')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)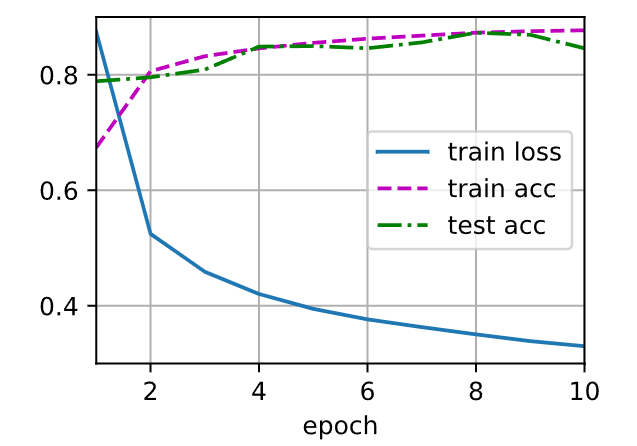
简洁实现
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)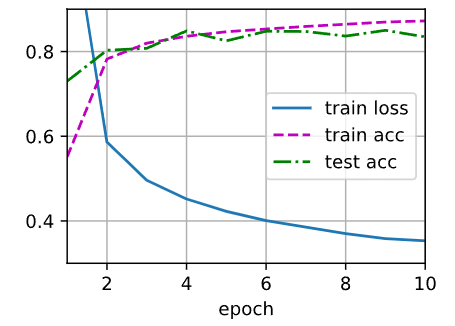
🌍3.2 基础练习
传送门:【动手学深度学习】多层感知机之暂退法问题研究详情
🌊4. 研究体会
通过这次研究,我深入学习了多层感知机,解决了分类和回归等问题。在本次实验中,使用Python编写了多层感知机模型,并分别应用了权重衰减和暂退法来观察它们对模型性能的影响。
首先,实现了一个简单的多层感知机模型,包括输入层、隐藏层和输出层。为了进行实验,选择了一个经典的分类问题数据集,并将其划分为训练集和测试集。接着定义了损失函数和优化器,并使用反向传播算法来更新模型的权重和偏置。
然后在暂退法实验中,设置了一个初始学习率和一个衰减系数,观察模型在不同学习率下的收敛速度和性能表现。实验结果表明,适当的暂退法可以加快模型的收敛速度,并提高模型的准确率。
通过本次实验,我深刻理解了权重衰减和暂退法对于多层感知机模型的重要性和影响。权重衰减技术可以通过惩罚大的权重值来控制模型的复杂度,防止过拟合;而暂退法技术可以通过逐渐减小学习率来提高模型的稳定性和收敛速度。
此外,观察到在实验中合适的超参数选择非常重要。对于暂退法技术,合适的初始学习率和衰减系数可以确保模型能在实验中有效地收敛并取得较好的性能。因此,超参数的选择是进行权重衰减和暂退法实验时需要仔细考虑和调优的关键因素之一。
通过观察模型的权重变化,我发现权重衰减和暂退法对特征选择起到了一定的作用。在应用权重衰减或暂退法后,一些权重值会趋近于零或变得非常小,这意味着这些特征对于模型的决策贡献较小。因此,可以根据权重的大小进行特征选择,从而提高模型的解释性和效果。

这篇关于【动手学深度学习】多层感知机之暂退法研究详情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





