本文主要是介绍BeanDefinitionReader接口,Spring加载Bean的过程(非常流畅和容易理解)(Spring源码分析1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
前言部分,介绍Spring框架的工作和大致原理,有基础的小伙伴可以跳过。
我们现在最常使用的开发框架SSM,分别是Spring、Spring MVC和Mybatis,其功能已经超出原生Spring非常多,所以想学习Spring原理,首先要走到底层。
第一,Spring框架,最关键的功能是bean的管理。
bean,可以理解成一个实例化的实体对象,使用过Spring的都知道,我们配置XML文件或者注解开发时,需要配置一个bean属性【在注解中,则是使用@Component注解】
这个配置的目的,就是告诉Spring某些信息。
最重要也是最基础的两个,一个是bean指向的类,另一个是bean的名称。
当然,还有单例或原型、初始化方法、销毁方法等等。
不过所有的这些信息,都指向BeanDefinition。
BeanDefinition,就是Spring对bean的定义,我们要使用bean,绕不开这个接口。
第二,Spring的核心设计,在于如何用配置文件,管理Bean
学习过设计模式的同学,应该对“工厂模式”有所了解,在此不介绍基础原理。
我们只需记住,Spring中,工厂是用BeanFactory接口体现的。
不过我们常用的工厂方法,很明显有一个缺点:对于接口Data,它每增加一个实现类,就要配置相关信息。
这也是Spring的问题所在,所以我们一旦增加一个类,就要用@Component注解该类。
我们考虑一个问题:明明只有配置文件,为何Spring框架却能将XML文件中的Bean定义,实例化出来呢?
记住下面的流程。
第一步,必须把Bean信息读取出来,也就是说,要有读取XML文件的能力。
第二步,Spring框架必须能实例化这个Bean,并且要有至少一个容器【数据结构】,来存储这些实例对象。
第三步,Spring至少对外有一个接口,使外界可以得到这个Bean。
二、从代码入手,学习底层的Spring使用方法【下面会统一说明这些名词】
我们考虑下面这行代码,现在已经很少有人这么写了,不过为了学习Spring的原理,我们必须先把Spring的Context部分放在一旁,专注于beans这个核心部分。
public static void main(String[] args) throws Exception{// 建造Spring工厂DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();// 初始化读取器。XmlBeanDefinitionReader beanDefinitionReader =new XmlBeanDefinitionReader(beanFactory);// 调用 加载 方法。【注:虽然是叫“加载”方法,但事实上完成了加载、注册和实例化功能】beanDefinitionReader.loadBeanDefinitions("Spring.xml");MyService myService = (MyService) beanFactory.getBean("myService");myService.serve(); // 只有一个打印方法}这段代码做了什么事呢?
按流程来说,请保持疑问。
第一,new一个BeanFactory工厂
疑问1:为什么使用Default Listable Bean Factory,而不是使用BeanFactory作为声明?
疑问2:为什么这个对象的new,不需要参数?那把它new出来有什么用处?
第二,new一个BeanDefinitionReader读取器
疑问1:Xml BeanDefinitionReader和我说的BeanDefinitionReader有什么关系?
疑问2:将这个BeanFactory传递进去,会发生什么?为什么需要这个Factory?
第三,调用读取器reader的load方法
疑问1:这个方法做了什么?为什么一下子就能使用Bean了?
三、记住几个重点名词
首先,我要说一下几个重点名词,以及它的含义。
记住:loadBeanDefinitions方法、Resource接口、resourceLoader属性。
按照类来解释。
BeanDefinition
Bean的定义,这个我想大家都了解,不过请记住一点:BeanDefinition是Spring的唯一数据类,这个类定义了所有数据,其它类定义的数据,都是为了辅助这个类的使用。
BeanFactory
工厂类,但不负责加载、初始化Bean,这个接口的唯一作用,其实是管理Bean【比如在外界需要时,传递一个bean对象】
这个接口的下层实现接口非常多,比如ListableBeanFactory,在此不介绍。
最重要的一个实现类,即DefaultListableBeanFactory,这个类同时实现了另一条支线上的BeanDefinitionRegistry接口。
这个实现类,有一个HashMap的数据结构beanDefinitionMap,存储了所有的bean,无论是bean的注册还是初始化,都要使用到它。
这就相当于生出了一个同时拥有二者能力的儿子。
BeanDefinitionRegistry
一个拥有注册Bean能力的接口,并非本文重点。
不过在Bean加载结束后,注册就要依靠它。
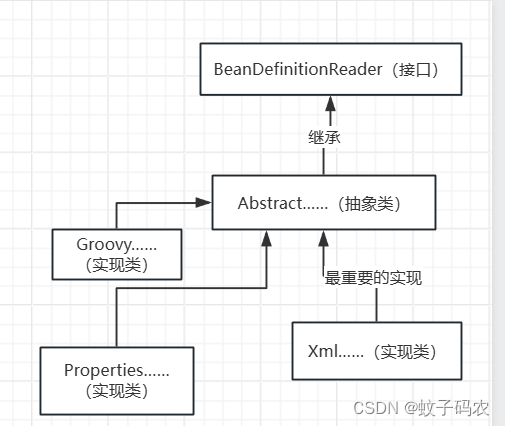
BeanDefinitionReader
这是本文的重点之一,这个接口的类继承结构如下图所示。
我们忽略Groovy、Properties,因为它们不是很重要。
Reader接口只定义了一些方法,在此不赘叙。
在Abstract中,实现了通用的方法,其中最重要的就是loadBeanDefinitions方法,这个方法的重载很多,实际的加载过程,甚至放在子类中实现。
不过不影响它的重要性,因为它将资源文件,全部转化为Resource资源,以便可以统一地访问数据。
至此,介绍完毕。
四、加载Bean,Spring的初始工作
有了前文的基础,这一步就轻松很多,让我们来看看源码。
我必须解释一下,BeanDefinitionReader读取器,它的new需要一个factory的原因,是它在加载方法中,调用了Bean注册、初始化的方法。
如果单纯的“加载”资源,使其成为可读的Document格式,不需要一个factory。【当然,实际上这个factory在reader眼里,是一个rigistry注册器】
第一步,走进Abstract抽象类loadBeanDefinitions方法里【参数:String location】
为了使代码结构更清晰,我把异常处理、日志记录都删除了,以下是我的分析。【忽略如何拿到加载器、以及如何加载资源】
我再次强调一下,Resource类,是Spring对底层资源的统一访问接口,所以拿到Resource对象是第一步。
首先,拿到资源加载器。
然后,根据加载器的类型【一次读取n个资源,或者1个资源】,拿到资源。
最后,把资源放入集合,等待处理。
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources){ResourceLoader resourceLoader = this.getResourceLoader(); int count;// 加载一个或多个资源if (resourceLoader instanceof ResourcePatternResolver) {// 多资源加载器,一次加载多个资源Resource[] resources = ((ResourcePatternResolver)resourceLoader).getResources(location);count = this.loadBeanDefinitions(resources);if (actualResources != null) {// 将资源类Resource,放进集合Collections.addAll(actualResources, resources);}return count; }} else {// 单资源加载器,一次加载一个资源Resource resource = resourceLoader.getResource(location);count = this.loadBeanDefinitions((Resource)resource);if (actualResources != null) {actualResources.add(resource);}return count;}}}第二步,走进Xml子类实现的loadBeanDefinitions方法中【参数:Resource resource】
这一步骤里,我依旧删除了异常处理、日志和一些语句,保留了比较重要的方法。
EncodedResource相当于Resource的编码结果,与Resource差别不大,在此忽略。
主要做了两件事
第一,将资源转化为InputSource。
第二,调用doLoadBeanDefinitions方法。【真正的加载bean方法】
public int loadBeanDefinitions(EncodedResource encodedResource){Assert.notNull(encodedResource, "EncodedResource must not be null");Set<EncodedResource> currentResources = (Set)this.resourcesCurrentlyBeingLoaded.get();int var6;InputStream inputStream = encodedResource.getResource().getInputStream();Throwable var4 = null;// 将资源转化为InputSourceInputSource inputSource = new InputSource(inputStream);if (encodedResource.getEncoding() != null) {inputSource.setEncoding(encodedResource.getEncoding());}// 最重要的一步var6 = this.doLoadBeanDefinitions(inputSource, encodedResource.getResource());return var6;
}第三步,走进doLoadBeanDefinitions方法
这一步的主要逻辑,就是得到Document文件,然后调用registerBeanDefinitions方法。
Document doc = this.doLoadDocument(inputSource, resource);
int count = this.registerBeanDefinitions(doc, resource);return count;至此,Bean的加载已经完毕,Document类,已经可以支持Spring注册bean和实例化bean,从底层XML资源,转化为可读的资源,已经完成。
至于Resource、Document是什么,ResourceLoader的原理又是什么,这部分我在下次再写。
五、结语
以上就是我分享的对Spring框架的理解。
我是蚊子码农,如有补充或者疑问,欢迎在评论区留言。个人的知识体系可能没有那么完善,希望各位多多指正,谢谢大家。
这篇关于BeanDefinitionReader接口,Spring加载Bean的过程(非常流畅和容易理解)(Spring源码分析1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





