本文主要是介绍Python数据分析案例46——电力系统异常值监测(自编码器,孤立森林,SVMD),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
案例背景
多变量的时间序列的异常值监测一直是方兴未艾的话题,我总能看到不少的同学要做什么时间序列预测,然后做异常值监测,但是很多同学都搞不清楚他们的区别。
这里要简单解释一下,时间序列预测是有监督的模型,而异常值监测在没有明确给出是不是异常值这个标签y的时候,通常都是无监督模型。通过数据的自身的规律来判断哪些是不是异常点。
本次用一组电力用电量的数据,某个用户的用电量的数据进行异常值监测的代码演示,数据量有点大,一个用户就有10w条,跑得太慢所以没有用很多模型,只用了(自编码器,孤立森林,SVMD)三个模型。
具体的数据文件csv,打开长这个样子:
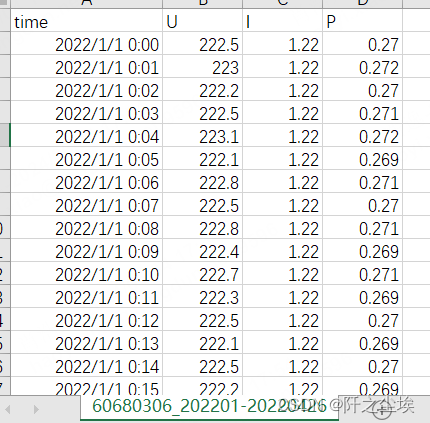
第一列是时间,u是电压,i是电流,p是功率。言简意赅,简单明了。
我们要做的就是用模型算法去寻找哪些时刻是异常点。
需要该案例的全部代码和数据集可以参考:异常值监测
代码实现
读取数据
先导入包,由于要用深度学习,包有点多
import os
import pandas as pd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsplt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号#from pandas.plotting import scatter_matrix
import pickle
import h5py
from scipy import statsfrom sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras import regularizers
from tensorflow.keras.utils import plot_model
%matplotlib inline
#sns.set(style='whitegrid', palette='muted', font_scale=1.5)from sklearn.model_selection import train_test_split
from sklearn.svm import OneClassSVM
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import IsolationForest
from sklearn.metrics import accuracy_score
from sklearn.mixture import GaussianMixture从下面读取的文件名称就知道,这是编号60680306的用户在2022年1月到4月26日的用电量情况的数据。
data1=pd.read_csv('60680306_202201-20220426.csv',parse_dates=['time']).set_index('time')
data1.head()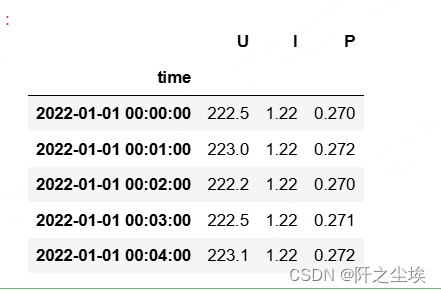
把P功率单独拿出来画一下
data1['P'].plot(figsize=(20,3))
数据挺密集的,也具有明显的周期性。
异常值监测
下面开始用不同的模型进行异常值监测
先进行数据的标准化
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(data1)
X_s = scaler.transform(data1)
X_trainNorm=X_s自编码器
自编码器就是神经网络进行重构后还原,我这里就用mlp层。
就是无监督模型,X是自己,y也是自己,重构后计算误差,误差大了就是异常值。
input_dim = X_trainNorm.shape[1]
layer1_dim = 64
encoder_dim = 32input_layer = Input(shape=(input_dim, ))
encoder1 = Dense(layer1_dim, activation="relu")(input_layer)
encoder2 = Dense(encoder_dim, activation="relu")(encoder1)
decoder1 = Dense(layer1_dim, activation='relu')(encoder2)
decoder2 = Dense(input_dim, activation='linear')(decoder1)
print('input_layer: ',input_layer)
print('encoder1',encoder1)
print('encoder2',encoder2)
print('decoder1',decoder1)
print('decoder2',decoder2)
打印查看模型信息
autoencoder = Model(inputs=input_layer, outputs=decoder2)
autoencoder.summary()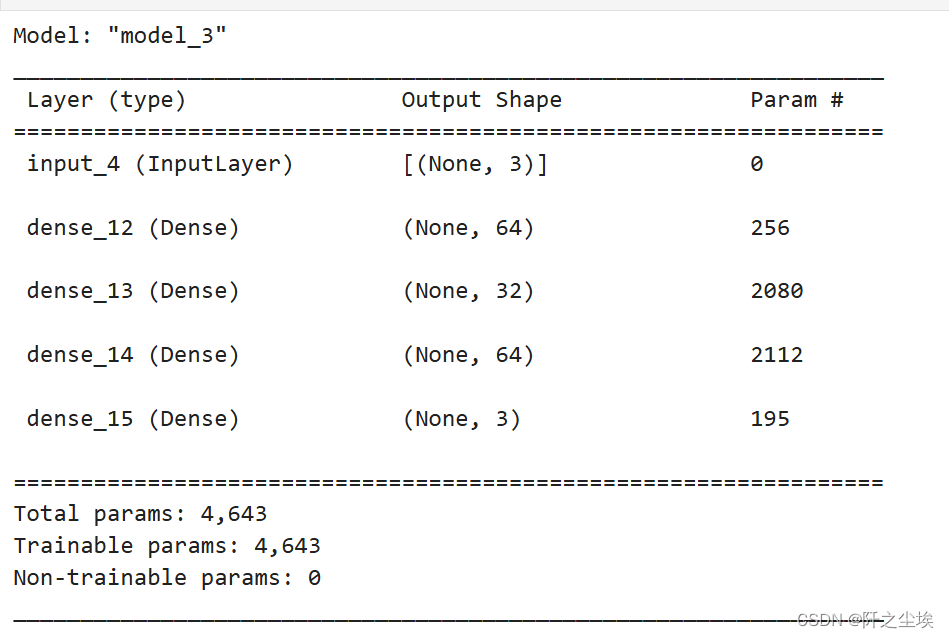
训练
nb_epoch = 10
batch_size = 128
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
#checkpointer = ModelCheckpoint(filepath="model.h5",verbose=0,save_best_only=True)
#earlystopping = EarlyStopping(monitor='val_loss', patience=5, verbose=0) # 'patience' number of not improving epochshistory = autoencoder.fit(X_trainNorm, X_trainNorm,epochs=nb_epoch, batch_size=batch_size,shuffle=True,verbose=1).history
查看损失变化
plt.plot(history['loss'])
#plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right');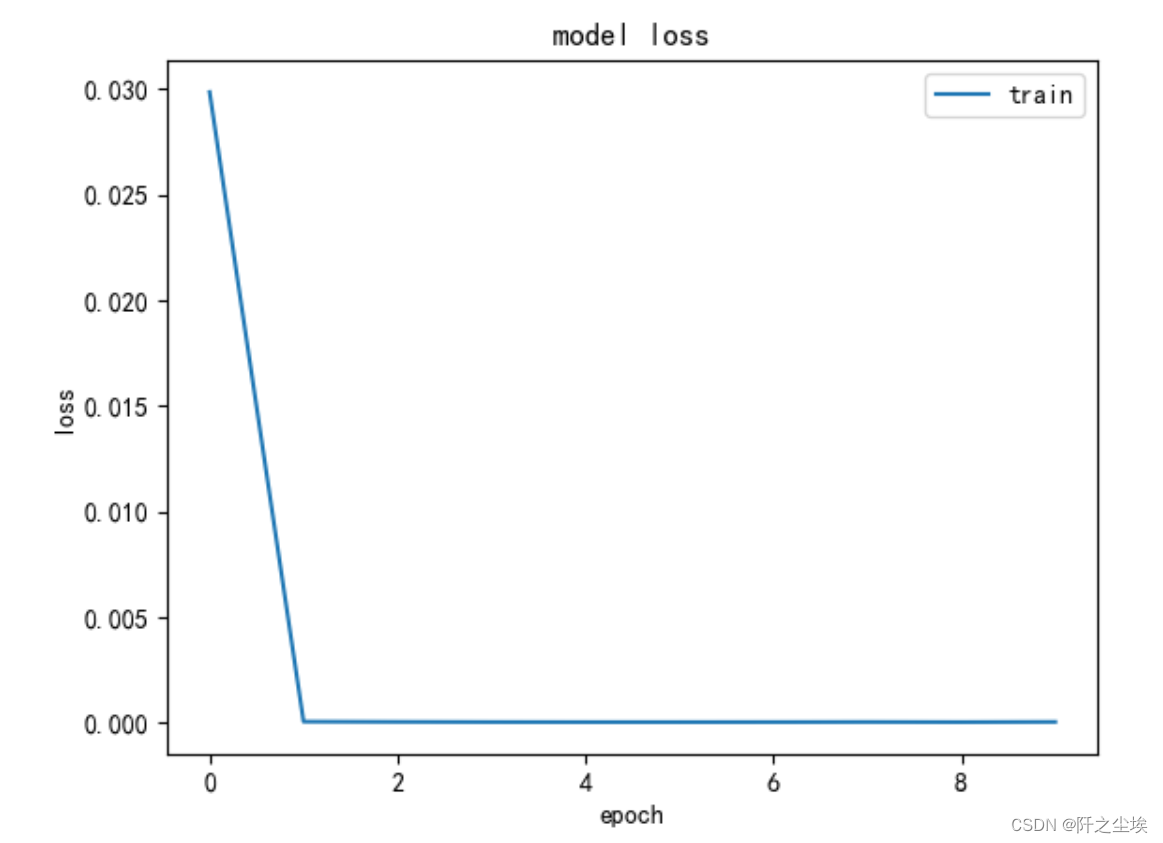
基本2轮就收敛了。
用解码器进行预测
testPredictions = autoencoder.predict(X_trainNorm)
X_trainNorm.shape,testPredictions.shape
可以看到数据还原回来了
我们取出P这一列,然后计算误差
testMSE = mean_squared_error(X_trainNorm.transpose(), testPredictions.transpose(), multioutput='raw_values')
error_df = pd.DataFrame({'reconstruction_error': testMSE,'true_value': data1['P']})
print(error_df.shape)
error_df.head()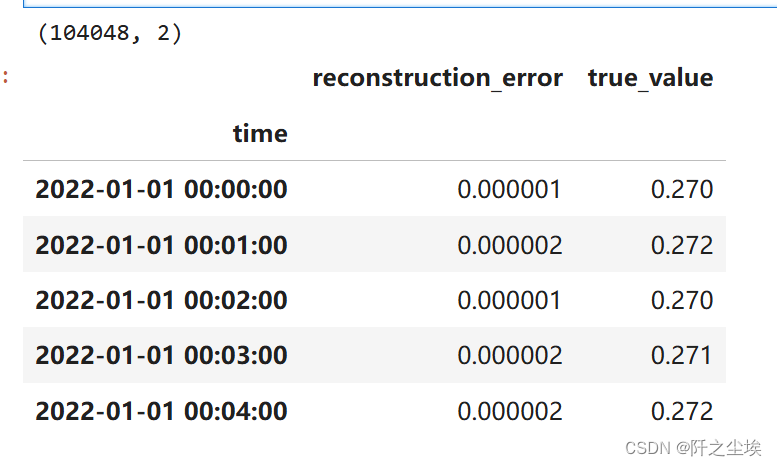
画个直方图看看:
error_df['reconstruction_error'].plot.hist()
可以看到误差基本都是0附近,但是存一些极大值,
我们用97.5%作为分位点,以此作为是不是异常值的阈值判断
threshold = error_df.reconstruction_error.quantile(q=0.975)
threshold
大于这个阈值就是异常值,小于就是正常值。查看计算出来的异常值和正常值的数量
mlp_label=np.where( error_df.reconstruction_error.to_numpy()>threshold,1,0)
error_df['pred_class']=mlp_label
error_df['pred_class'].value_counts()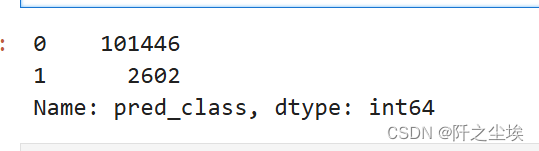
异常值2.6k,正常值1w,差不多是这个比例。
画个图直观看看
groups = error_df.groupby('pred_class')
fig, ax = plt.subplots(figsize=(10,3),dpi=128)
for name, group in groups:if name == 1:MarkerSize = 3 ; Color = 'orangered' ; Label = 'Fraud' ; Marker = 'd'else:MarkerSize = 3 ; Color = 'b' ; Label = 'Normal' ; Marker = 'o'ax.plot(group.index, group.reconstruction_error, linestyle='',color=Color,label=Label,ms=MarkerSize,marker=Marker)ax.hlines(threshold, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold')
ax.legend(loc='upper left', bbox_to_anchor=(0.95, 1))
plt.title("Probabilities of fraud for different classes")
plt.ylabel("Reconstruction error") ; plt.xlabel("Data point index")
plt.show()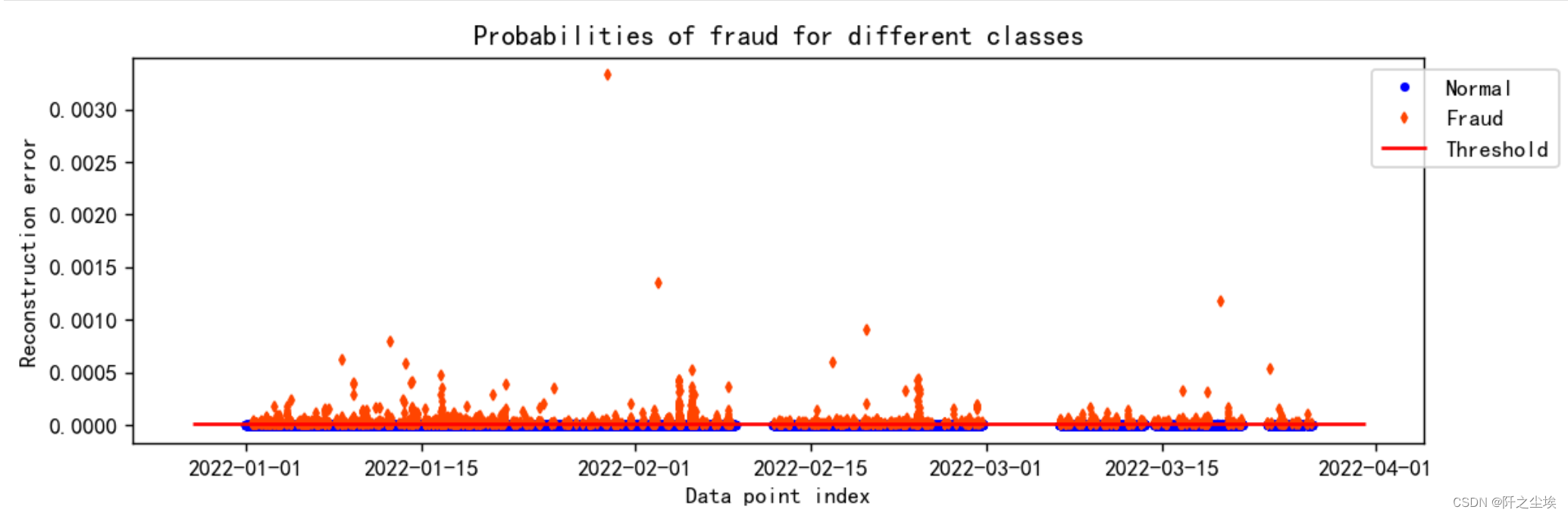
上面红色的,误差大的,就是异常值。
然后把这些异常点画在功率曲线上面
def plot_Abnormal(error_df,mode='Autoencoder'):plt.figure(figsize=(14, 4),dpi=128)plt.plot(error_df.index, error_df["true_value"], label='Power')# Plotting the pred_class scatter plot for points where pred_class is 1pred_class_1 = error_df[error_df["pred_class"] == 1]plt.scatter(pred_class_1.index, pred_class_1["true_value"], color='orange', label='Abnormal value')# Adding labels and legendplt.xlabel('Time')plt.ylabel('Power')plt.title(mode)plt.legend()plt.grid(True)plt.show()
plot_Abnormal(error_df,mode='Autoencoder')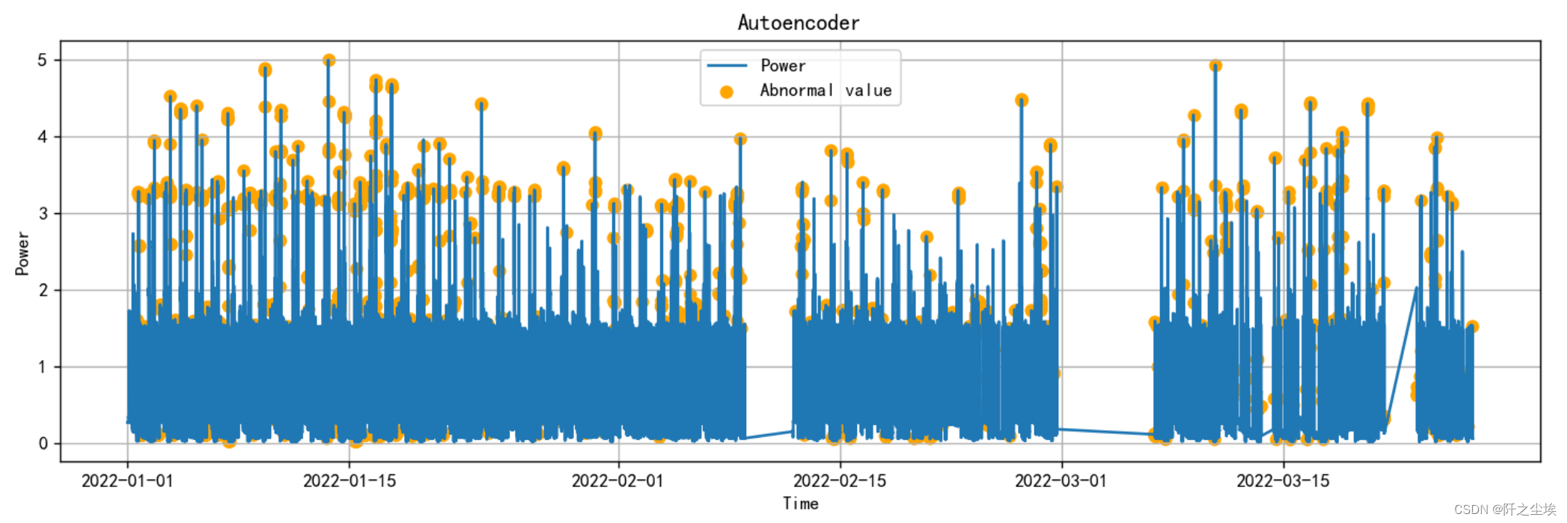
可以看到很多极大的点,或者是下面一些极小的点,都被判断为异常值。
计算一下误差指标MSE,MAE,方便等下模型对比。
def calculate_mse_mae(df):true_mean = df[df["pred_class"] == 0]["true_value"].mean()pred_class_1 = df[df["pred_class"] == 1]["true_value"]if pred_class_1.empty:mse = np.nanmae = np.nanelse:mse = np.mean((pred_class_1 - true_mean) ** 2)mae = np.mean(np.abs(pred_class_1 - true_mean))return mse, mae# Calculate MSE and MAE for the given DataFrame
df_eval_all=pd.DataFrame(columns=['MSE','MAE'])
df_eval_all.loc['Autoencoder',:]=calculate_mse_mae(error_df)支持数据描述
支持数据描述,Support Vector Data Description,SVMD,就是支持向量机的无监督版:
直接用sklearn就行
svmd = OneClassSVM(nu=0.025, kernel="rbf", gamma=0.1)
# Fit the SVM model only on normal data (X_normal)
svmd.fit(X_trainNorm) # Ensure to use scaled normal data
y_pred = svmd.predict(X_trainNorm)
print(y_pred.shape)
pd.Series(y_pred).value_counts()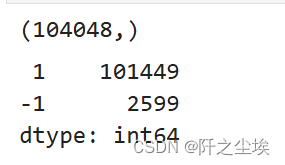
差不多也是这个比例
画图查看
error_df = pd.DataFrame({'true_value': data1['P']})
error_df['pred_class']=pd.Series(y_pred).map({1:0,-1:1}).to_numpy()
plot_Abnormal(error_df,mode='SVMD')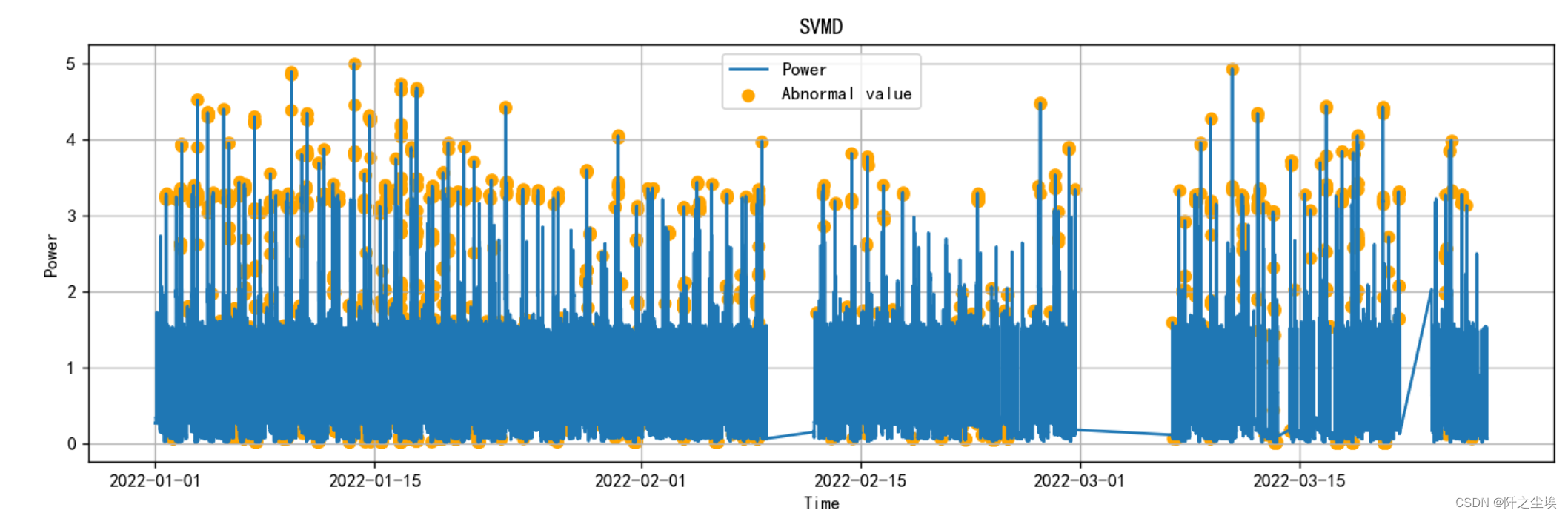
可以看到 和自编码器一样,很多极大的点,或者是下面一些极小的点,都被判断为异常值。
计算误差指标
df_eval_all.loc['SVMD',:]=calculate_mse_mae(error_df)孤立深林
孤立深林 Isolation Forest,也是机器学习模型的无监督版
进行异常值监测
iso_forest = IsolationForest(contamination=0.025)
iso_forest.fit(X_trainNorm) #X_normal_scaled
y_pred_iso = iso_forest.predict(X_trainNorm)
pd.Series(y_pred_iso).value_counts()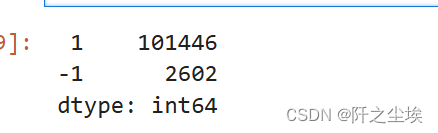
异常值和正常值差不多也是这个比例
画图
error_df = pd.DataFrame({'true_value': data1['P']})
error_df['pred_class']=pd.Series(y_pred_iso).map({1:0,-1:1}).to_numpy()
plot_Abnormal(error_df,mode='IF')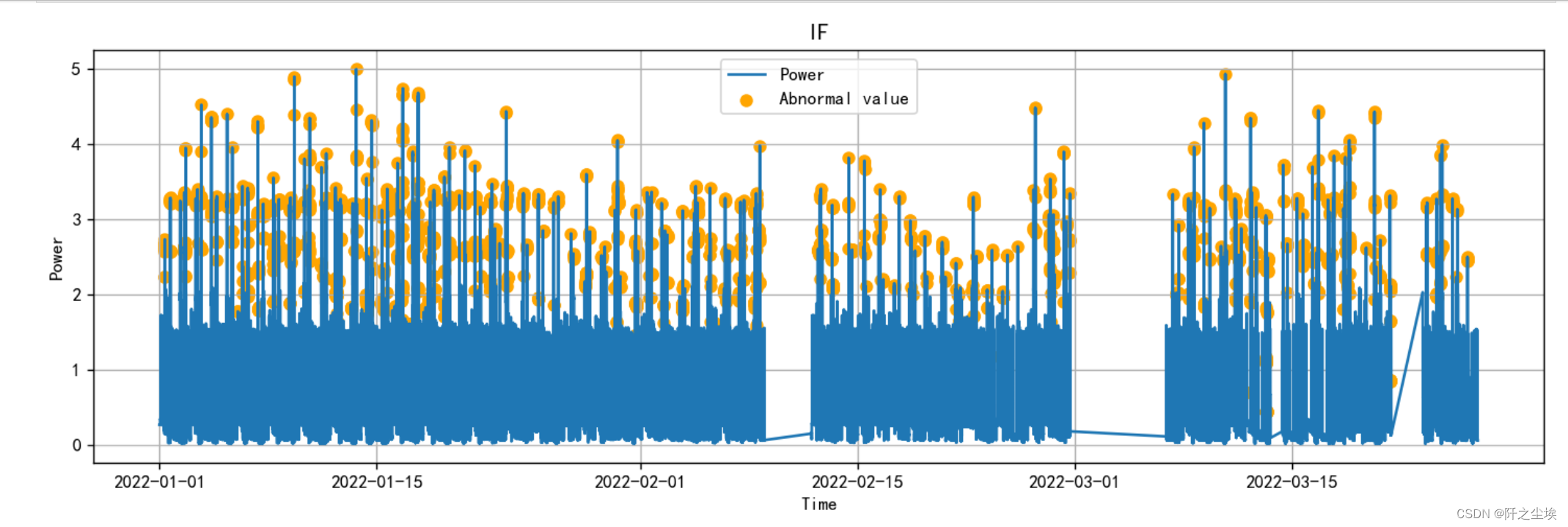
可以看到 和前面方法一样,很多极大的点,都被判断为异常值。
但是孤立森林明显下面极小的点没有太多异常值。
计算误差指标
df_eval_all.loc['IF',:]=calculate_mse_mae(error_df)评价指标对比
df_eval_all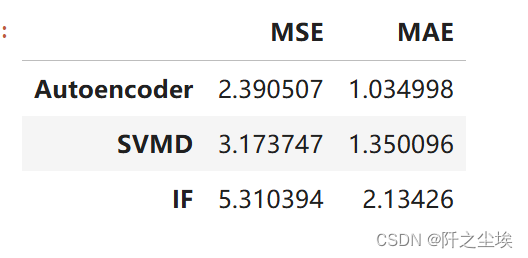
可视化
bar_width = 0.4
colors=['tomato','springgreen','skyblue','gold']
fig, ax = plt.subplots(1,2,figsize=(6,3))
for i,col in enumerate(df_eval_all.columns):n=int(str('12')+str(i+1))plt.subplot(n)df_col=df_eval_all[col]m =np.arange(len(df_col))#hatch=['-','/','+','x'],plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)#plt.xlabel('Methods',fontsize=12)names=df_col.indexplt.xticks(range(0, 3),names,fontsize=11)plt.ylabel(col,fontsize=11)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()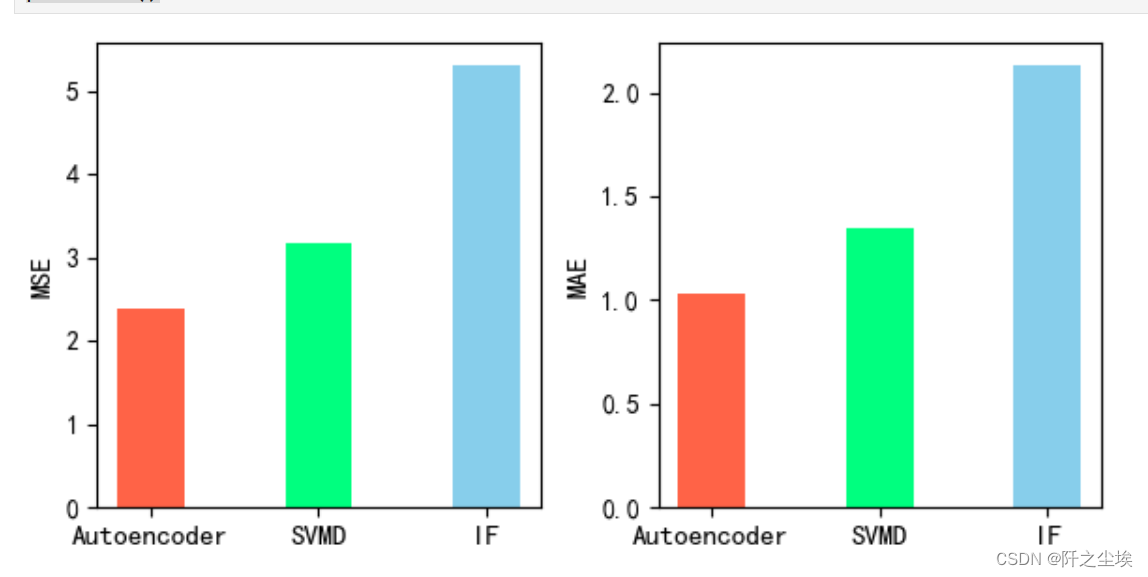
可以看到,自编码器效果好于SVMD好于孤立森林。
因为数据量大,深度学习的方法还是好一些。
本次就演示了3中异常值监测的方法,时间序列都可以套用,更多的异常值监测的模型可以参考我之前的文章。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)
这篇关于Python数据分析案例46——电力系统异常值监测(自编码器,孤立森林,SVMD)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







