本文主要是介绍storm-0.8.2集群模式安装部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
标签(空格分隔): storm
hadoop,spark,kafka交流群:224209501
集群:
一台主机用来运行nimbus,另外两台运行superior。
安装及测试:
1,安装ZeroMQ
2,安装jzmq
3,安装Python
4,安装storm
5,配置storm
6,启动storm
7,测试storm
1,安装依赖
sudo yum install uuid*
sudo yum install libtool
sudo yum install libuuid
sudo yum install libuuid-devel
sudo yum install libtool*2,安装zeromq
tar -zxvf zeromq-2.1.7.tar.gz -C /opt/storm/./configuremakesudo make install3,安装jzmq
unzip jzmq-master.zip -d /opt/storm/
./autogen.sh
./configure
make
make install4,配置storm
1,说明一下:storm.local.dir表示storm要用到的本地目录。nimbus.host表示哪一台机器是master,即nimbus。storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置端口号一致,否则会出现通信错误。当然你也可以配置superevisor.slot.ports,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个spout或者bolt默认只启动一个worker,但是可以通过conf修改成多个)
2,java.library.path这是storm所依赖的本地依赖(ZeroMQ和JZMQ)的加载地址,默认的是:/usr/local/lib:/opt/local/lib:/usr/lib,大多数情况下是对的,所以你应该不用更改这个配置。
注意事项:
1,配置时一定注意在每一项的开始时是要加空格(最好加两个空格),冒号之后也要加空格,否则storm不认识这个配置文件。
2,在目录/usr/tmp下面增加storm文件夹。
在storm.yaml文件中配置如下内容:
storm.zookeeper.servers:- "miaodonghua.host"
# - "server2"
# nimbus.host: "miaodonghua.host"5,启动nimbus
bin/storm nimbus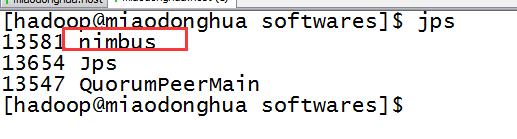
6,启动storm的web UI
经测试,StormUI必须和Storm Nimbus部署在同一台机器上,否则UI将无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
nohup bin/storm ui & 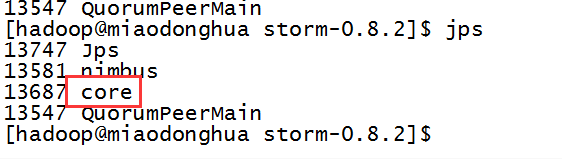
浏览器中输入下面链接及端口号
http://miaodonghua.host:8080///浏览器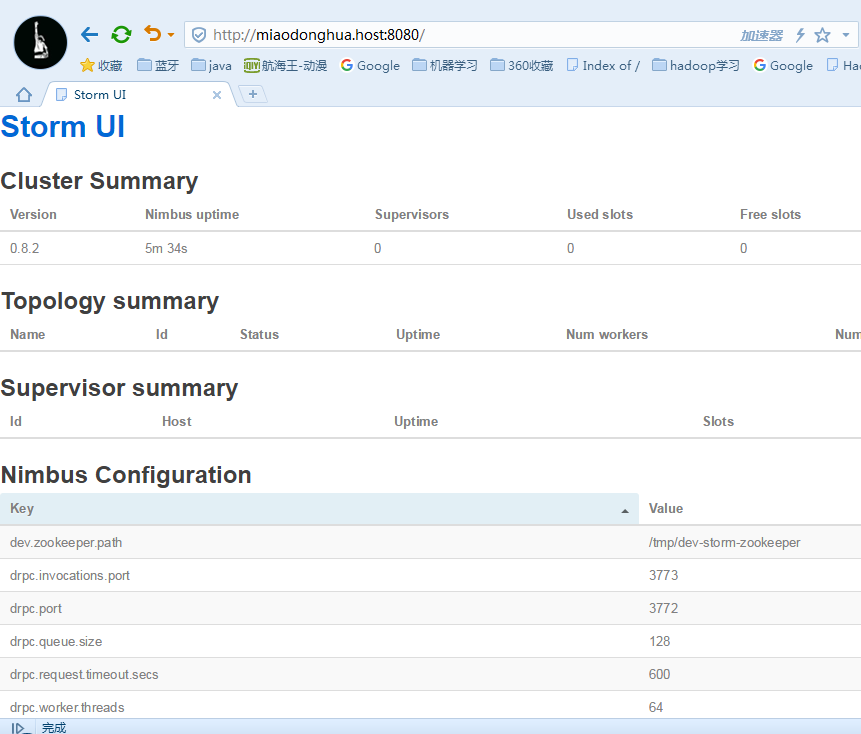
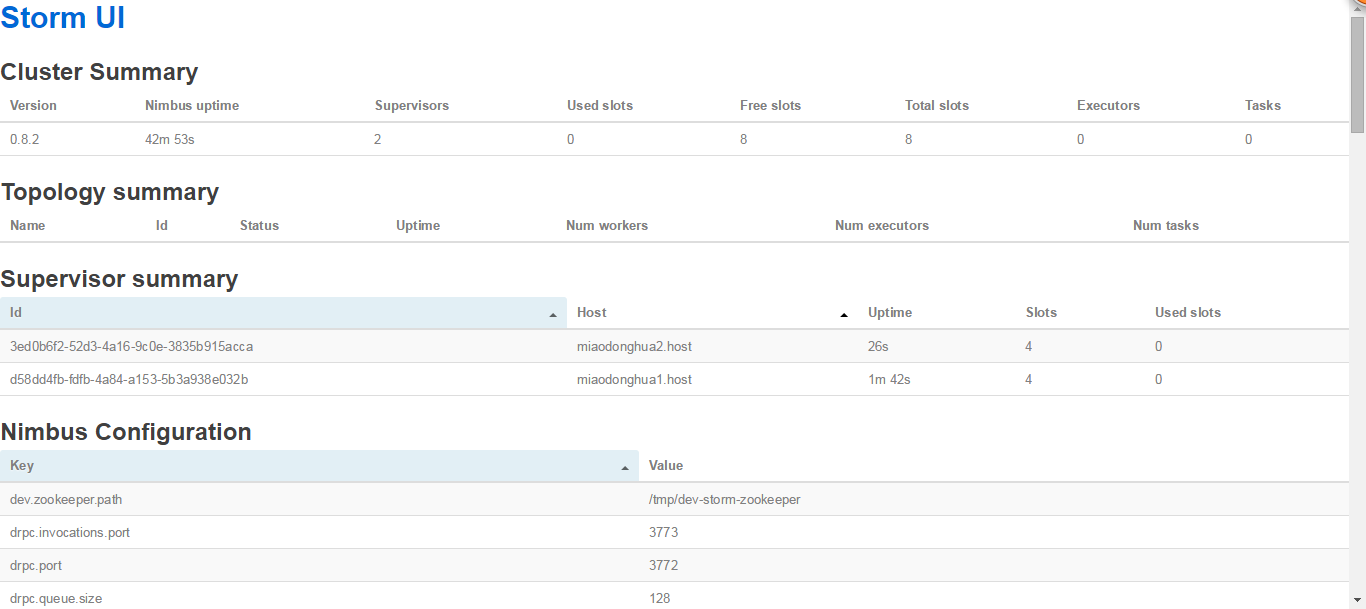
7,启动从节点
在两台supervisor机器中启动
nohup bin/storm supervisor &
8,运行
bin/storm jar /opt/storm/storm-0.8.2/lifeCycle.jar cn.storm.topology.TopoMain
bin/storm list
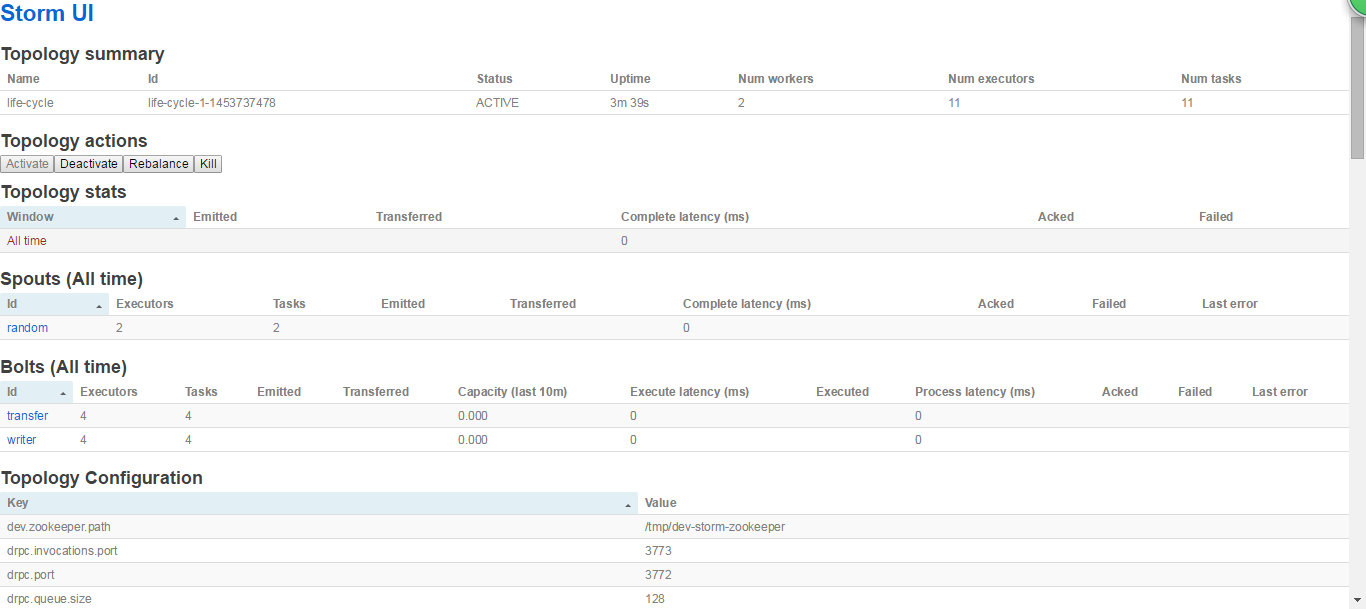
http://miaodonghua.host:8080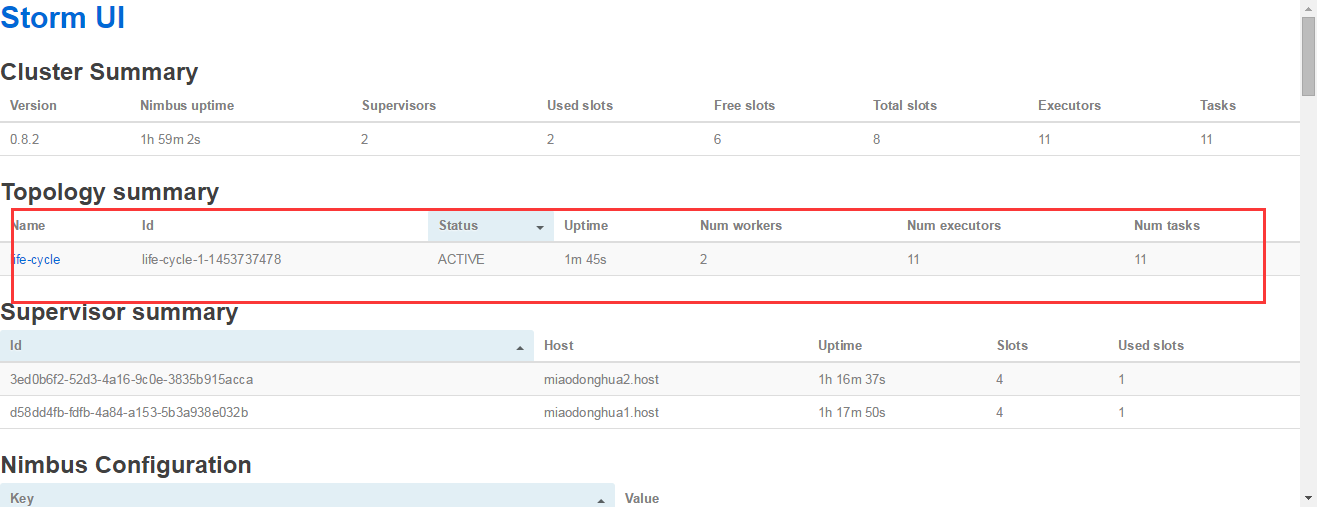
9,storm-start-master
下载storm-start:
storm-starter-0.7.0.zip
进入主目录修改m2-pom.xml(将twitter4j-core和twitter4j-stream替换为下面的部分)
<dependency><groupId>org.twitter4j</groupId><artifactId>twitter4j-core</artifactId>
<version>[2.2,)</version>
</dependency>
<dependency><groupId>org.twitter4j</groupId><artifactId>twitter4j-stream</artifactId><version>[2.2,)</version>
</dependency>编译
mvn -f m2-pom.xml package
复制 storm-starter目录下的m2_pom.xml 为pom.xml,放在与m2_pom.xml同一目录下
打jar包
mvn jar:jar
如果需要对工程代码进行修改,可以导入eclipse
mvn eclipse:eclipse
10,源码内容如下
1,编写RandomWordSpout
package cn.storm.spout;import java.util.Map;
import java.util.Random;import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
/*** 随机从String数组当中读取一个单词发送给下一个bolt* @author Administrator**/
public class RandomWordSpout extends BaseRichSpout {private static final long serialVersionUID = -4287209449750623371L;private static final Log log = LogFactory.getLog(RandomWordSpout.class);private SpoutOutputCollector collector;private String[] words = new String[]{"storm", "hadoop", "hive", "flume"};private Random random = new Random();public RandomWordSpout() {log.warn("&&&&&&&&&&&&&&&&& RandomWordSpout constructor method invoked");}@Overridepublic void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {log.warn("################# RandomWordSpout open() method invoked");this.collector = collector;}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {log.warn("################# RandomWordSpout declareOutputFields() method invoked");declarer.declare(new Fields("str"));}@Overridepublic void nextTuple() {log.warn("################# RandomWordSpout nextTuple() method invoked");Utils.sleep(500);String str = words[random.nextInt(words.length)];collector.emit(new Values(str));}@Overridepublic void activate() {log.warn("################# RandomWordSpout activate() method invoked");}@Overridepublic void deactivate() {log.warn("################# RandomWordSpout deactivate() method invoked");}
}
2,编写TransferBolt
package cn.storm.bolt;import java.util.Map;import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;/*** 将数据做简单的 传递的Bolt* @author Administrator**/
public class TransferBolt extends BaseBasicBolt {private static final long serialVersionUID = 4223708336037089125L;private static final Log log = LogFactory.getLog(TransferBolt.class);public TransferBolt() {log.warn("&&&&&&&&&&&&&&&&& TransferBolt constructor method invoked");}@Overridepublic void prepare(Map stormConf, TopologyContext context) {log.warn("################# TransferBolt prepare() method invoked");}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {log.warn("################# TransferBolt declareOutputFields() method invoked");declarer.declare(new Fields("word"));}@Overridepublic void execute(Tuple input, BasicOutputCollector collector) {log.warn("################# TransferBolt execute() method invoked");String word = input.getStringByField("str");collector.emit(new Values(word));}}
3,编写WriterBolt
package cn.storm.bolt;import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/*** 将接收到的单词写入到一个文件当中* @author Administrator**/
public class WriterBolt extends BaseBasicBolt {private static final long serialVersionUID = -6586283337287975719L;private static final Log log = LogFactory.getLog(WriterBolt.class);private FileWriter writer = null;public WriterBolt() {log.warn("&&&&&&&&&&&&&&&&& WriterBolt constructor method invoked");}@Overridepublic void prepare(Map stormConf, TopologyContext context) {log.warn("################# WriterBolt prepare() method invoked");try {writer = new FileWriter("/home/" + this);} catch (IOException e) {log.error(e);throw new RuntimeException(e);}}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {log.warn("################# WriterBolt declareOutputFields() method invoked");}@Overridepublic void execute(Tuple input, BasicOutputCollector collector) {log.warn("################# WriterBolt execute() method invoked");String s = input.getString(0);try {writer.write(s);writer.write("\n");writer.flush();} catch (IOException e) {log.error(e);throw new RuntimeException(e);}}}
4,编写TopoMain
package cn.storm.topology;import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import cn.itcast.storm.bolt.TransferBolt;
import cn.itcast.storm.bolt.WriterBolt;
import cn.itcast.storm.spout.RandomWordSpout;public class TopoMain {private static final Log log = LogFactory.getLog(TopoMain.class);/*** @param args*/public static void main(String[] args) throws Exception {TopologyBuilder builder = new TopologyBuilder();builder.setSpout("random", new RandomWordSpout(), 2);builder.setBolt("transfer", new TransferBolt(), 4).shuffleGrouping("random");builder.setBolt("writer", new WriterBolt(), 4).fieldsGrouping("transfer", new Fields("word"));Config conf = new Config();conf.setNumWorkers(2);conf.setDebug(true);log.warn("$$$$$$$$$$$ submitting topology...");StormSubmitter.submitTopology("life-cycle", conf, builder.createTopology());log.warn("$$$$$$$4$$$ topology submitted !");}}这篇关于storm-0.8.2集群模式安装部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







