本文主要是介绍SQL刷题笔记day8——SQL进阶——表与索引操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 创建一张新表
2 修改表
3 删除表
4 创建索引
5 删除索引
1 创建一张新表
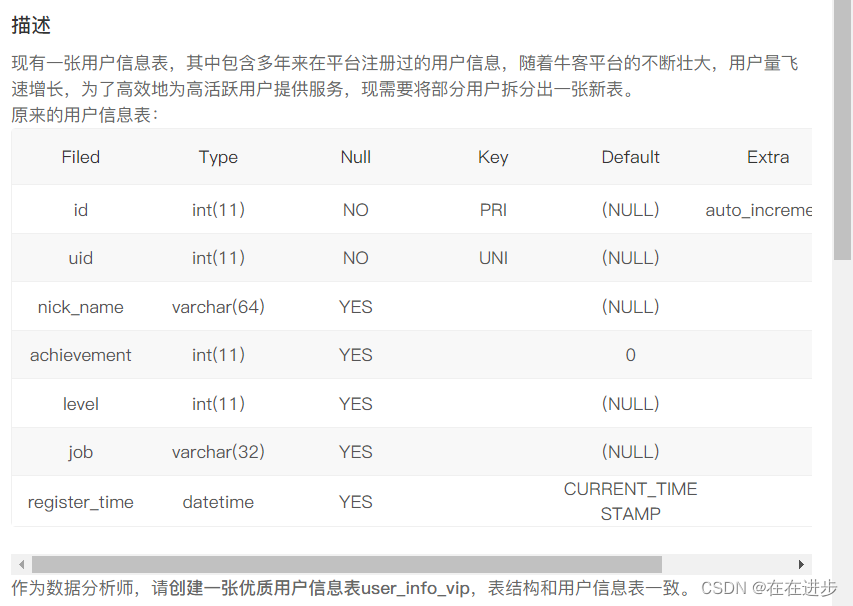
我的答案
create table if not exists user_info_vip
(id int(11) primary key auto_increment Comment'自增ID', # 有了主键就不用写not nul了
uid int(11) unique not null Comment'用户ID',
nick_name varchar(64) Comment'昵称',
achievement int(11) default 0 Comment'成就值',
level int(11) Comment'用户等级',
job varchar(32) Comment'职业方向',
register_time datetime default CURRENT_TIMESTAMP Comment'注册时间')
default charset = utf8正确答案:
CREATE TABLE user_info_vip(id int(11) primary key auto_increment comment "自增ID",uid int(11) unique not null comment "用户ID",nick_name varchar(64) comment "昵称",achievement int(11) default 0 comment "成就值",level int(11) comment "用户等级",job varchar(32) comment "职业方向",register_time datetime default current_timestamp comment "注册时间"
)DEFAULT CHARSET=UTF8;复盘:有了主键就不用写not nul了
--创建新表,如果存在则覆盖
drop table [if exists] 表名;
--创建新表,如果存在则返回
create table
[if not exists] 表名 -- 不存在才创建,存在就跳过
(<列名1> <数据类型> -- 列名和类型必选[ primary key -- 可选的约束,主键| foreign key -- 外键,引用其他表的键值| auto_increment -- 自增ID| comment <注释> -- 列注释(评论)| default <值> -- 默认值| unique -- 唯一性约束,不允许两条记录该列值相同| not null -- 该列非空,输入空会报错| current_timestamp -- 当前时间戳], ...
) [character set <字符集名>] -- 字符集编码
[collate <校对规则名>] -- 列排序和比较时的规则(是否区分大小写等)2 修改表
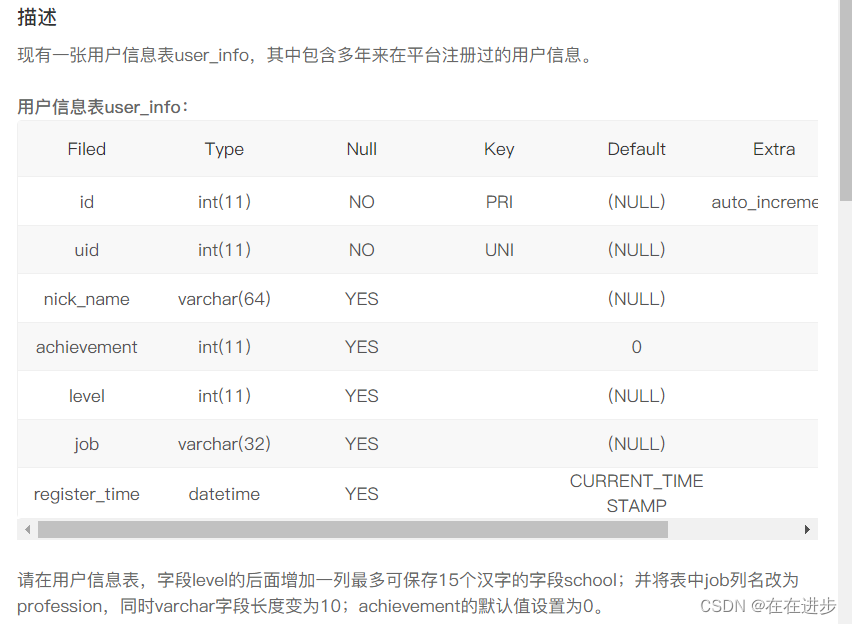
修改方法:
alter table 表名 修改选项;
选项集合:
{ add column <新增列名> <类型> after <某一列> -- 在某一列之后增加列
| change column <旧列名> <新列名> <新列类型> -- 修改列名或类型
| alter column <列名> { set default <默认值> | drop default } -- 修改/删除 列的默认值
| modify column <列名> <类型> -- 修改列类型
| drop column <列名> -- 删除列
| rename to <新表名> -- 修改表名
| character set <字符集名> -- 修改字符集
| collate <校对规则名> } -- 修改校对规则(比较和排序时用到,是否区分大小写等)
我的代码:表名后面不需要大花括号{ }
alter table user_info
add column school varchar(15) after level,
change column job profession varchar(10),
modify column achievement int(11) default 0;修改三次的方法代码:
ALTER TABLE user_info ADD column school varchar(15) AFTER LEVEL;
ALTER table user_info CHANGE column job profession varchar(10);
ALTER TABLE user_info MODIFY column achievement int(11) default 0;3 删除表

drop table [if exists] 表名 [,表名1,...];
我的代码:天真了,删除表能使用的很有限?
drop table if exists exam_record
where YEAR between 'exam_record_2011' and 'exam_record_2014'正确代码:暴力删除
drop table if exists exam_record_2011, exam_record_2012,exam_record_2013,exam_record_2014或者一个一个的删除:
drop table if exists exam_record_2011;
drop table if exists exam_record_2012;
drop table if exists exam_record_2013;
drop table if exists exam_record_2014;4 创建索引
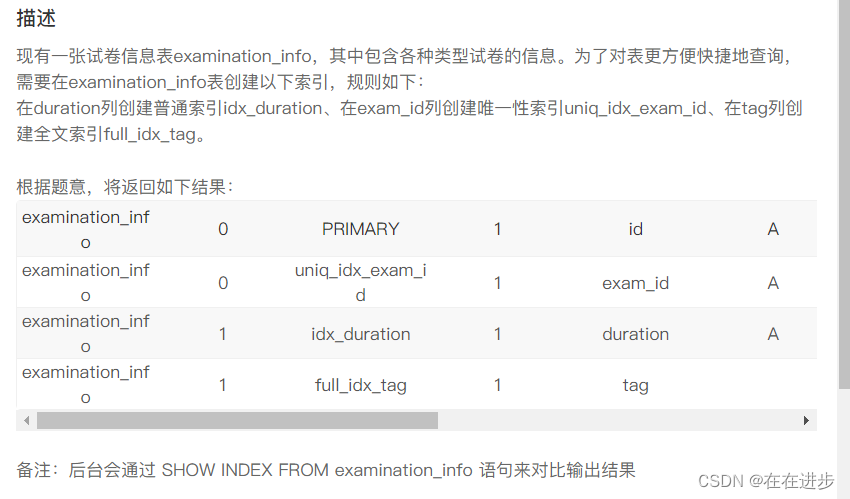
方法一、使用create index
- [使用]:
create [unique|fulltext] index 索引名 on 表名 (列名); - [注意]:unique 唯一性索引、fulltext 全文索引
方法二、修改表的方式创建索引
- [使用]:
alter table examination_info add [索引类型] index 索引名(列名); - [注意]:索引类型:普通索引、唯一性索引、全文索引
方法三、建表的时候创建索引
- [使用]:
create table tableName( id int not null, 列名 列的类型, [索引类型] index [索引名] (列名,...););
我的错误代码:方法一 使用create index,但是缺失表名
create index idx_duration on duration;
create unique index uniq_idx_exam_id on exam_id;
create fulltext index full_idx_tag on tag;正确修改后:补全表名
# 创建普通索引
create index idx_duration on examination_info(duration);
# 创建唯一性索引
create unique index uniq_idx_exam_id on examination_info(exam_id);
# 创建全文索引
create fulltext index full_idx_tag on examination_info(tag);方法二:修改表的方式创建索引
-- 唯一索引
ALTER TABLE examination_info
ADD UNIQUE INDEX uniq_idx_exam_id(exam_id);
-- 全文索引
ALTER TABLE examination_info
ADD FULLTEXT INDEX full_idx_tag(tag);
-- 普通索引
ALTER TABLE examination_info
ADD INDEX idx_duration(duration);学习链接:https://blog.csdn.net/chengyj0505/article/details/128376127?spm=1001.2014.3001.5502
5 删除索引

我的错误粗暴代码:drop [unique|fulltext]index index_name on table_name ;
drop unique index uniq_idx_exam_id on examination_info;
drop fulltext index full_idx_tag on examination_info;删除不需要给出类型[unique|fulltext]?
修改后
法一:drop index index_name on table_name ;
drop index uniq_idx_exam_id on examination_info;
drop index full_idx_tag on examination_info;法二:alter table table_name drop index index_name ;
注意:table不能少
alter table examination_info drop index uniq_idx_exam_id;
alter table examination_info drop index full_idx_tag; #table不能少这篇关于SQL刷题笔记day8——SQL进阶——表与索引操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








