本文主要是介绍关于12306技术相关说明以及暂定计划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
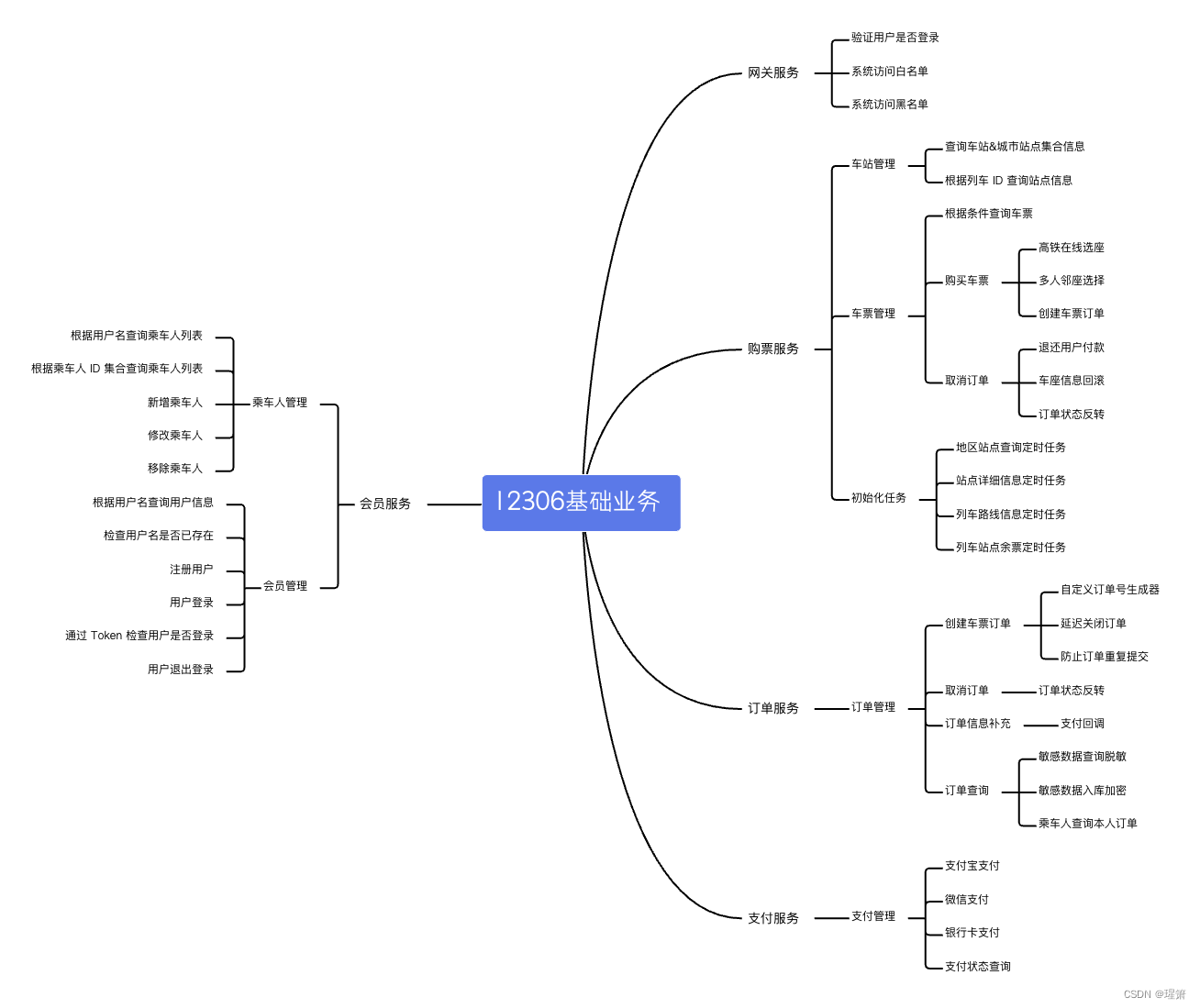
12306 项目中包含了缓存、消息队列、分库分表、设计模式等代码,通过这些代码可以全面了解分布式系统的核心知识点。
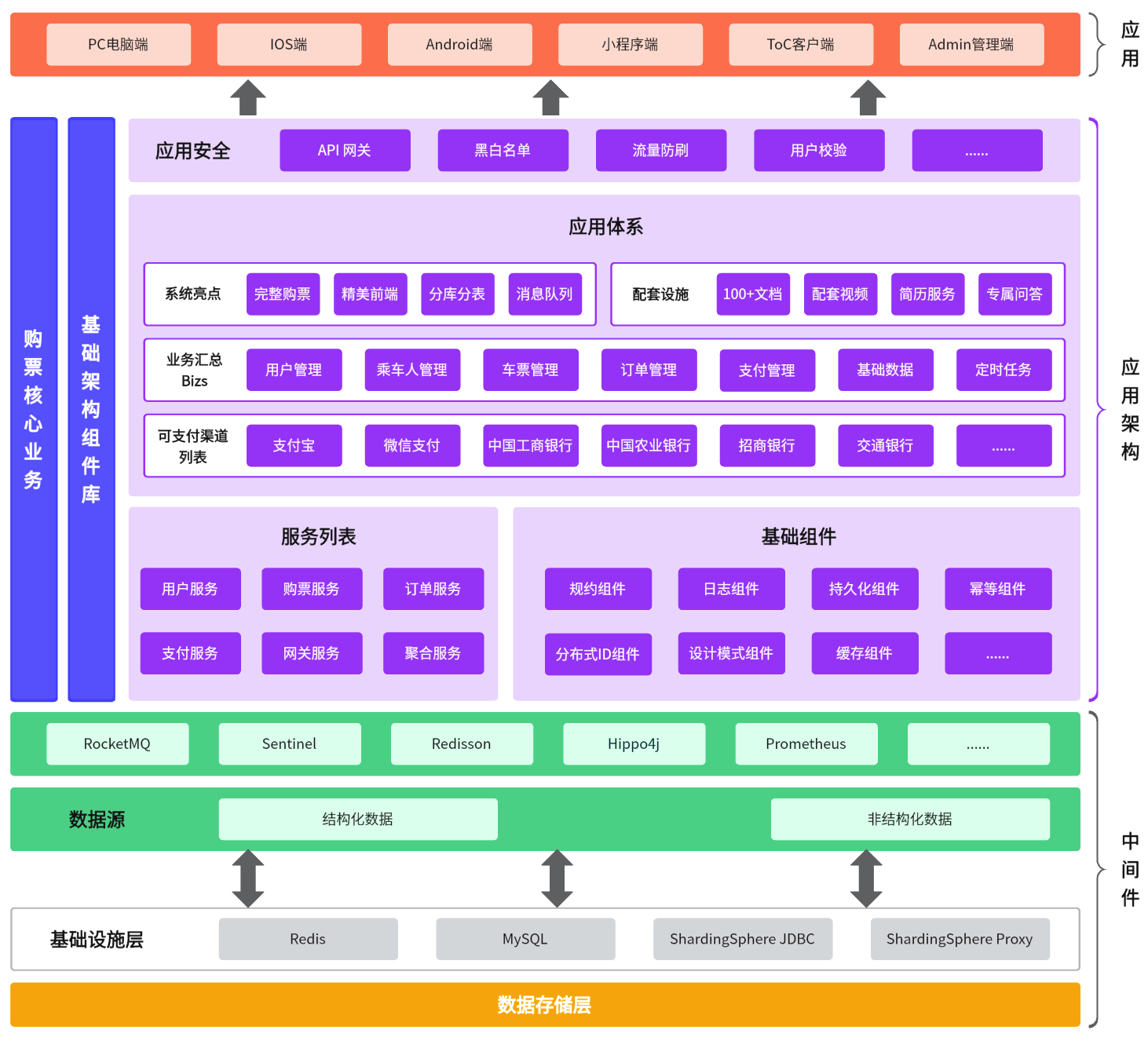
在系统设计中,采用最新 JDK17 + SpringBoot3&SpringCloud 微服务架构,构建高并发、大数据量下仍然能提供高效可靠的 12306 购票服务。
下方的架构图全面描述了项目的服务集合、组件库列表和基础设置层等要素,有助于用户快速了解 12306 平台的顶层设计和业务细节,从零到一进行构建。
以用户服务系统为例,低并发和低数据量的系统相对简单,但高并发和海量数据的系统则需要考虑很多额外因素。
- 当用户在 12306 网站注册新账号或添加乘车人时,系统需验证用户提交信息的真实性和准确性。如何有效预防用户提交虚假信息,保障系统购票的安全?
- 12306 的大规模用户和乘车人数据如何选择分库分表?选择哪个字段作为分片键?如何在老业务上平滑上线分库分表?出现问题如何快速回滚?
- 系统支持会员使用用户名、手机号以及邮箱等多种方式进行登录。由于登录时无法确定用户的分片键,造成的“读请求扩散”问题如何解决?
- 在高并发的会员注册场景下,绝对会出现缓存穿透问题。网上鼓吹的对不存在 Key 进行缓存值设为 Null,以及布隆过滤器等都存在漏洞,如何解决?
- 存在较多的敏感信息,比如会员或者乘车人的姓名、手机号、邮箱、证件号码以及住址,如何防止数据库被攻击时造成的敏感信息泄露?
再以购票服务为例,当用户购买两个乘车人的高铁一等座票且没有选座时,座位的分配逻辑如下:
- 首先检查当前列车的一等座余票是否足够。如果余票不足,直接向客户端返回购票请求失败的响应;
- 获取所有车厢中有两个座位余票的车厢,并对这些车厢进行遍历,按照下述流程执行;
- 首先检查所有车厢中是否存在一等座车票的相邻座位。如果所有车厢中都没有相邻座位,进入下一步逻辑;
- 接着检查是否有车厢中包含两个不相邻的一等座座位?因为同车厢两座位相邻座位没有的话,就退而找同车厢不相邻座位;
- 如果以上逻辑都无法满足,那么最后选择分配不同车厢的不相邻座位。这种情况下,由于已经确认一等座的余票充足,因此一定能够成功完成购票;
- 通过以上步骤,购票系统能够在高铁一等座票余票充足的情况下,合理地分配座位,确保乘车人出行时有良好的座位体验。同时,如果余票不足,系统会优先满足乘车人顺利购票的需求。
12306 前端系统实现了与官网极为接近的业务逻辑和 UI 展示。
在学习过程中,通过类似官网的前端系统直接调试后端服务,可以避免纯通过接口测试的繁琐。这种真实场景的模拟,使得学习过程更加流畅高效。
目前前端系统还在开发中,部分业务及细节处还在调整,完成后统一给出控制台操作手册,请耐心等待。
1.车票查询功能

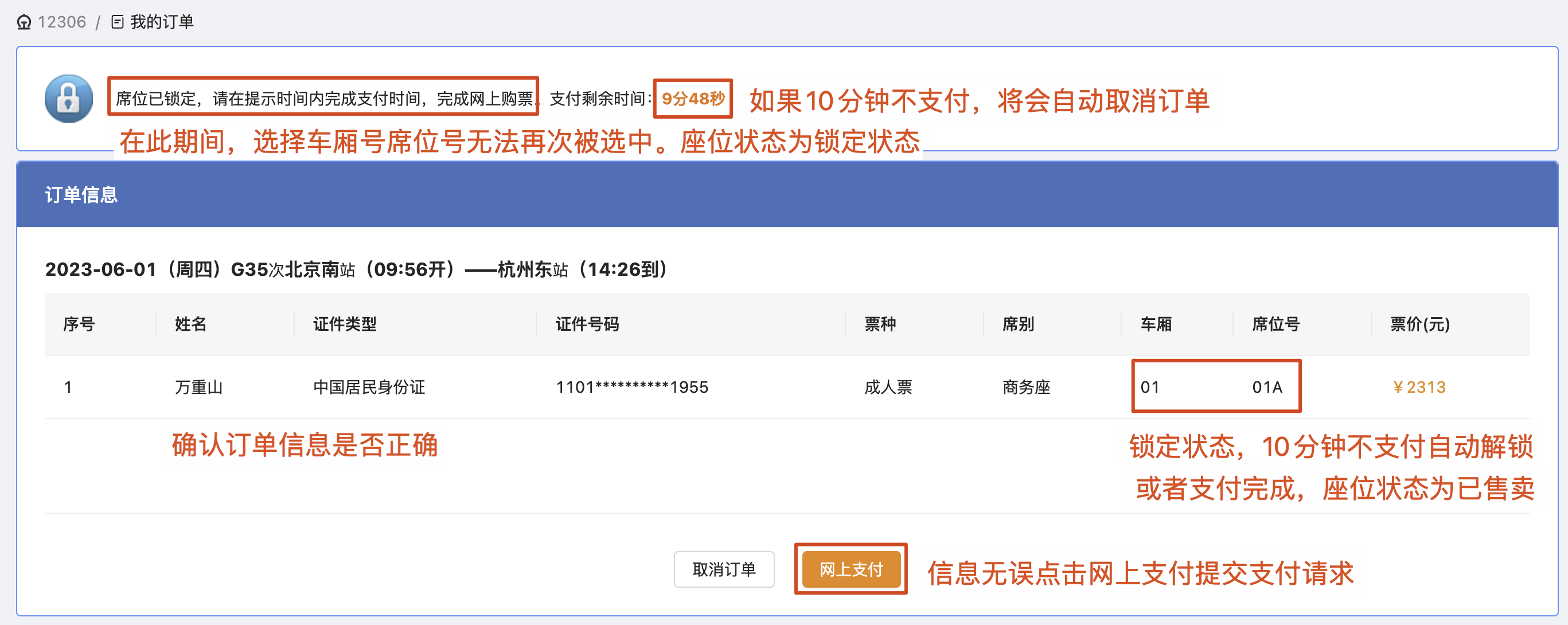
2. 提交订单页,选择乘车人下单
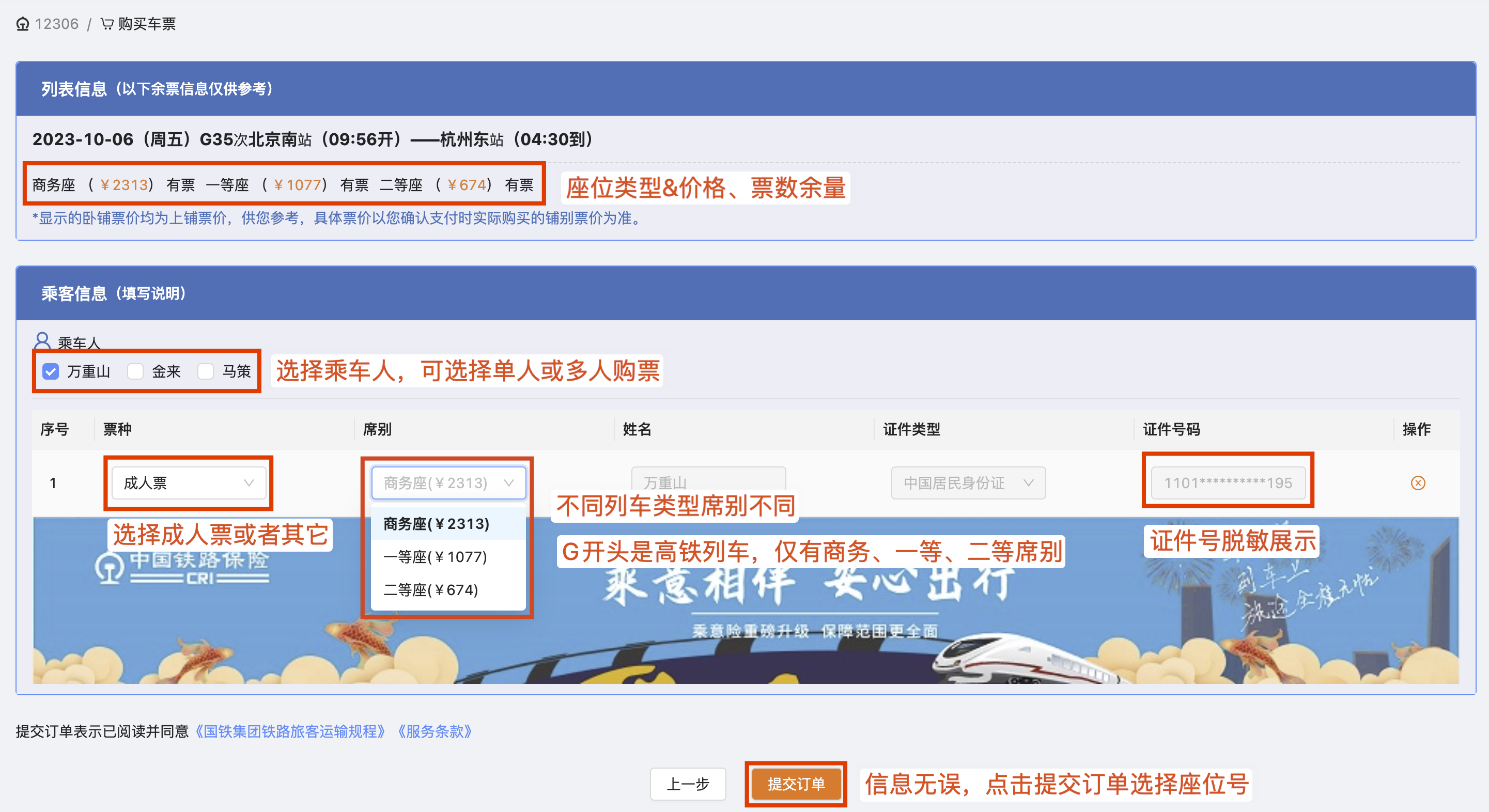
3. 高铁在线选座页面
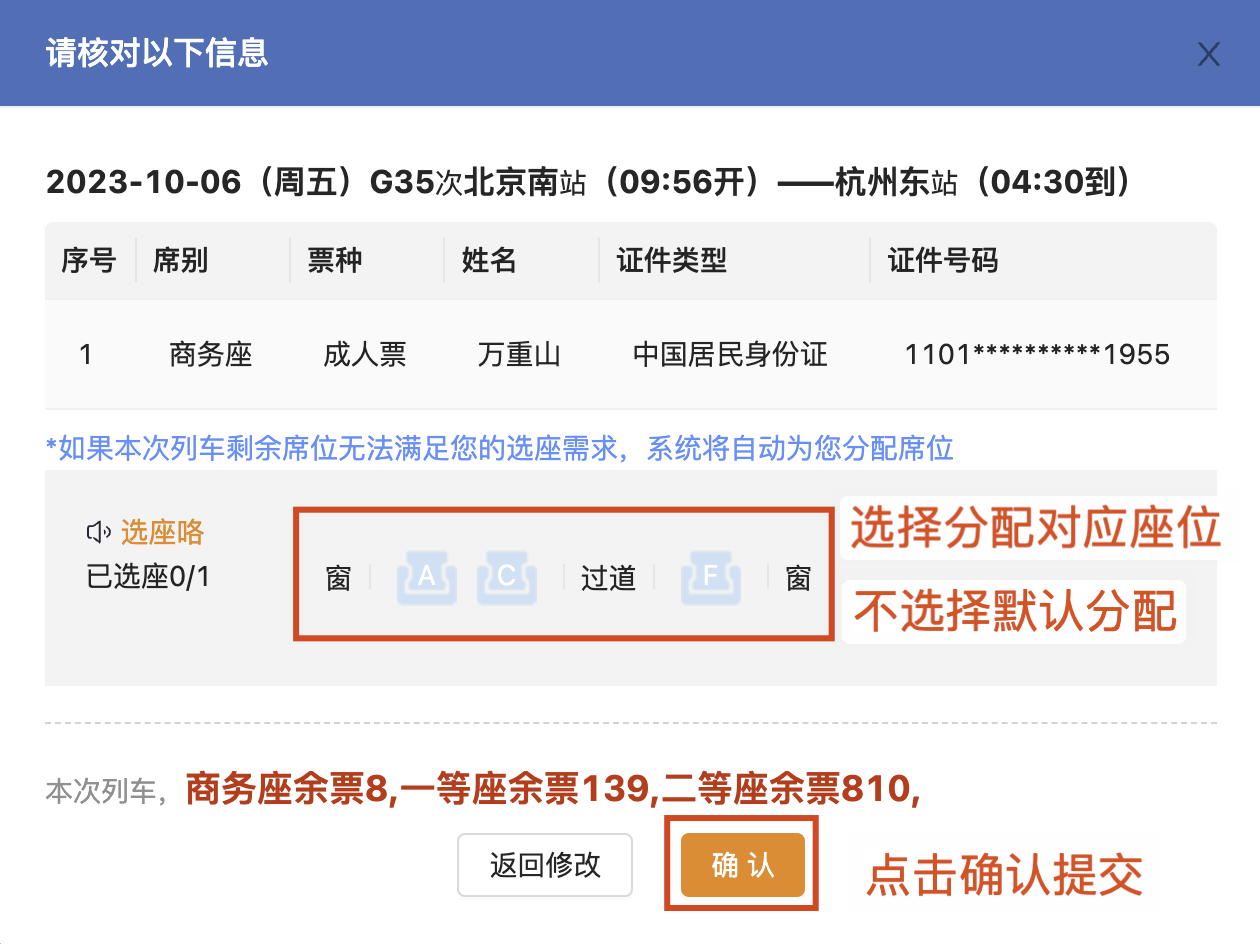
4. 订单确认页
12306 购票误区
说些大家对于 12306 购票时没有考虑到的一些业务点,或者存在误区的地方。
背景:假设,有一站列车,途径北京南、济南西、南京南、杭州东、宁波。
查询站点对应的列车车次信息。
- 你以为:通过搜索引擎技术 ElasticSearch 技术解决,因为涉及大量的查询条件。比如:车次、车组、出发车站、到达车站、出发时间等。
- 实际上 :当海量并发查询时,ElasticSearch 的并发能力以及资源占用情况来说,并不适用。而且,大家如果仔细思考,发现这些查询条件都是可以通过类似于 Redis 的缓存技术存储,并在内存中进行组装。
买一张北京南到南京南的车票。
- 你以为:只扣减北京南到南京南单趟的票。
- 实际上:会扣减北京南-济南西,北京南-南京南,济南西-南京南的三趟车票。如果其中有任意条件不满足都不会购买成功。
买一张济南西到南京南的车票。
- 你以为:按照上述逻辑,如果通过软件恶意刷票,只买济南西-南京南的票,北京南-杭州东是否就买不到了?
- 实际上:每个站数之间的数量都有规则。虽然放票时间都是一致的,但是优先大站之间的票量,避免因为大量用户购买了中间站的车票导致始发站和终点站的购票困难。该问题通过动态放票解决,比如刚开始放票时对小站之间仅开放少量票,大站之间放出来多数票。如果后续接近发车时间,再开放小站间的车票。
当然,业务以及技术上的难点和亮点并不止于这些,更多的信息可以通过代码以及 12306 的使用上进行发掘。

这篇关于关于12306技术相关说明以及暂定计划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







