本文主要是介绍Buffer Pool运行机制理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Buffer Pool机制理解
一、为什么使用Buffer Pool?
众所周知,磁盘数据是以数据页的形式来去读取的,一个数据页默认大小 16K,也就是说你本意只想读取一行数据,但是它会给你加载一页的数据到buffer pool里面。这样的话就能减少与磁盘的交互次数,从而提升效率。
二、什么是Buffer Pool?
- 是一块内存区域,当数据库操作数据的时候,把磁盘上的数据加载到buffer pool,对buffer pool数据进行增删改查,不直接和磁盘打交道。
- 默认大小 128M
SHOW VARIABLES LIKE '%innodb_buffer_pool_size%'; -- 查看buffer_pool大小 默认128M
SHOW VARIABLES LIKE '%innodb_old_blocks_pct%'; -- LRU链表冷热区域配置 默认3 7
SHOW VARIABLES LIKE '%innodb_old_blocks_time%'; -- LRU链表冷区域的数据隔多久可以放入到热区域
SHOW VARIABLES LIKE '%innodb_file_size%'; -- 单个logfile的大小 默认48M
SHOW VARIABLES LIKE '%innodb_log_file_in_group%'; -- 配置有几个logfile
SHOW VARIABLES LIKE '%innodb_log_buffer_size%'; -- redo log buffer的大小 默认16M
SHOW VARIABLES LIKE '%innodb_flush_log_at_trx_commit%'; -- redo log buffer 中的内容间隔多久刷新到磁盘, 默认1s
三、Buffer Pool运行机制
当我们读取数据的时候,如果buffer pool中不存在则会从磁盘加载到buffer pool,然后一直读取数据就会一直加载,所以buffer pool就会有爆满的时候。这时候就要采取淘汰策略,buffer pool采取的LRU(最近最少使用)淘汰策略。
在此之前先说的是,使用LRU策略淘汰的时候,就会出现下面的所演示的现象(有数据的控制块是不连续的),这时候再读取数据到buffer pool的时候要填充到哪个空白的区域?–就要用到free链表
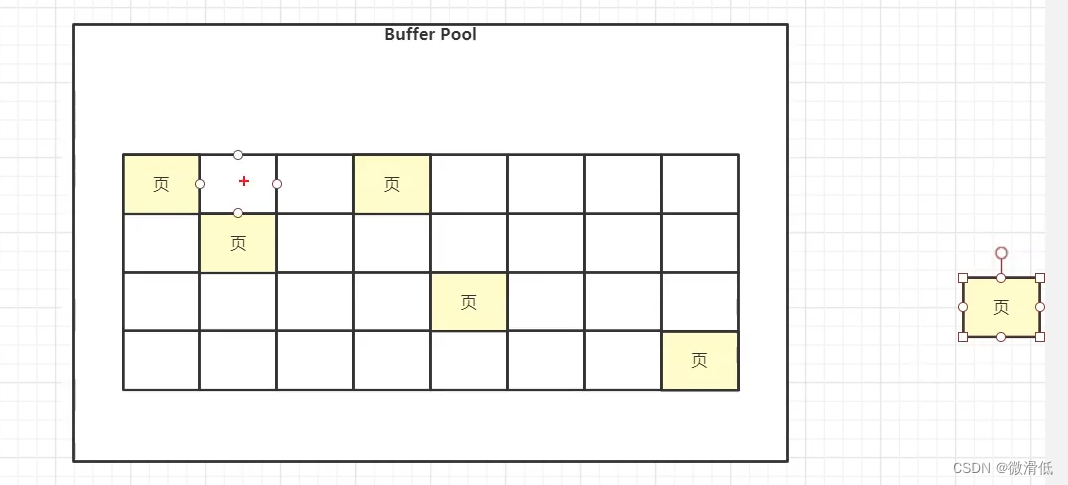
1. free链表
主要管理空白区域,该链表会有一个基节点用于管理链表有多少空白的控制块,还有两个结点,一个连接头结点,一个连接尾结点。当读取数据到buffer pool的时候,会找free链表的头结点对应的控制块进行填充,当进行控制块淘汰的时候,空白的控制块就会连接free链表的尾结点。
2. flush链表
当我们进行update语句的时候,就会对数据进行修改,此时也是对buffer pool的数据进行修改,有数据进行修改又没刷新到磁盘的这页数据我们称为脏页。mysql后台线程会对这些脏页进行刷盘,但是要刷哪些页?此时就得靠flush链表了。
flush链表主要管理上面所说的脏页区域,该链表会有一个基节点用于管理链表有多少脏页的控制块,同样有两个结点,一个连接头结点,一个连接尾结点。当mysql后台线程进行刷盘的时候就会找到flush链表有哪些是脏页来进行刷盘。
3.lru链表
当我们读取一页的数据到buffer pool的时候,这一页的数据就会信息就会被记录到lru链表,再读取一页数据,后一页的数据的信息会插到之前的页之前。当读取的页又被用的话,也会插到链表的头结点,所以lru链表最靠前就是最近被使用的数据。当buffer pool满的时候,就会进行淘汰lru链表尾部的数据。
但是这样的lru链表是存在问题的:比如我们有那么几页是频繁查询的数据页始终位于lru链表的头部部分,此时我们执行一个查询数据量非常大的sql,首页会淘汰lru链表尾部的数据块,还是不够的话就会淘汰头部那些热点数据块。因此就会影响热点数据,所以要对lru链表进行升级。
4.升级版lru链表

升级版的lru链表会分为热数据区域和冷数据区域,占比为5:3,当我们对数据页进行操作时,会插入冷区域的头部,淘汰也是淘汰冷区域的尾部。那么冷区域的数据什么时候才能进入热区域呢?
首先数据页被访问进入冷区域的时候设为t1,该数据页再次被访问的时候设为t2,t2减去t1大于1s的时候就会被放入热数据区域。这样就能预防类似全表扫描这样的sql,对热数据产生的影响,因为一直替换的是冷区域的数据。
这篇关于Buffer Pool运行机制理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







