本文主要是介绍论文解读之A General-Purpose Self-Supervised Model for Computational Pathology,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
目前,有很多无知者认为计算机在疾病诊断上超过了人类,他们的理解是计算机在美丽国的某个什么医师测评上得分超过了人类。这比较可笑和无知。
笔者认为:病理图像的病症复杂、种类繁多,同时数据集很少并且标注极为困难。故而,能用于训练的高质量数据很少,并且模型的可解释性还不足。
因此,AI在疾病诊断上的表现想要接近和超过人类专家还很遥远。故而目前火热的名词只是辅助诊断,并不是AI诊断。
本次讲解的文章是出自麻省总医院和哈佛医学院发表在Nature Medicine期刊上的病理图像基础模型。
其主要研究内容是一种用于解决计算病理学方向问题的自监督模型基础模型——UNI
据笔者理解:计算病理学是使用AI以及其他计算库从而通过计算机系统解决疾病机理方面研究的领域。
二、模型架构
总的来说,UNI是基于ViT-Large的在较大规模的病例图像数据集预训练的一个编码器,可以理解为是对病例图像进行特征提取,然后从而能够将提前到的特征图接到下游的分类或分割模型中执行下游任务。
附带附录中对于几个感兴趣区域的不同维度的注意力热图: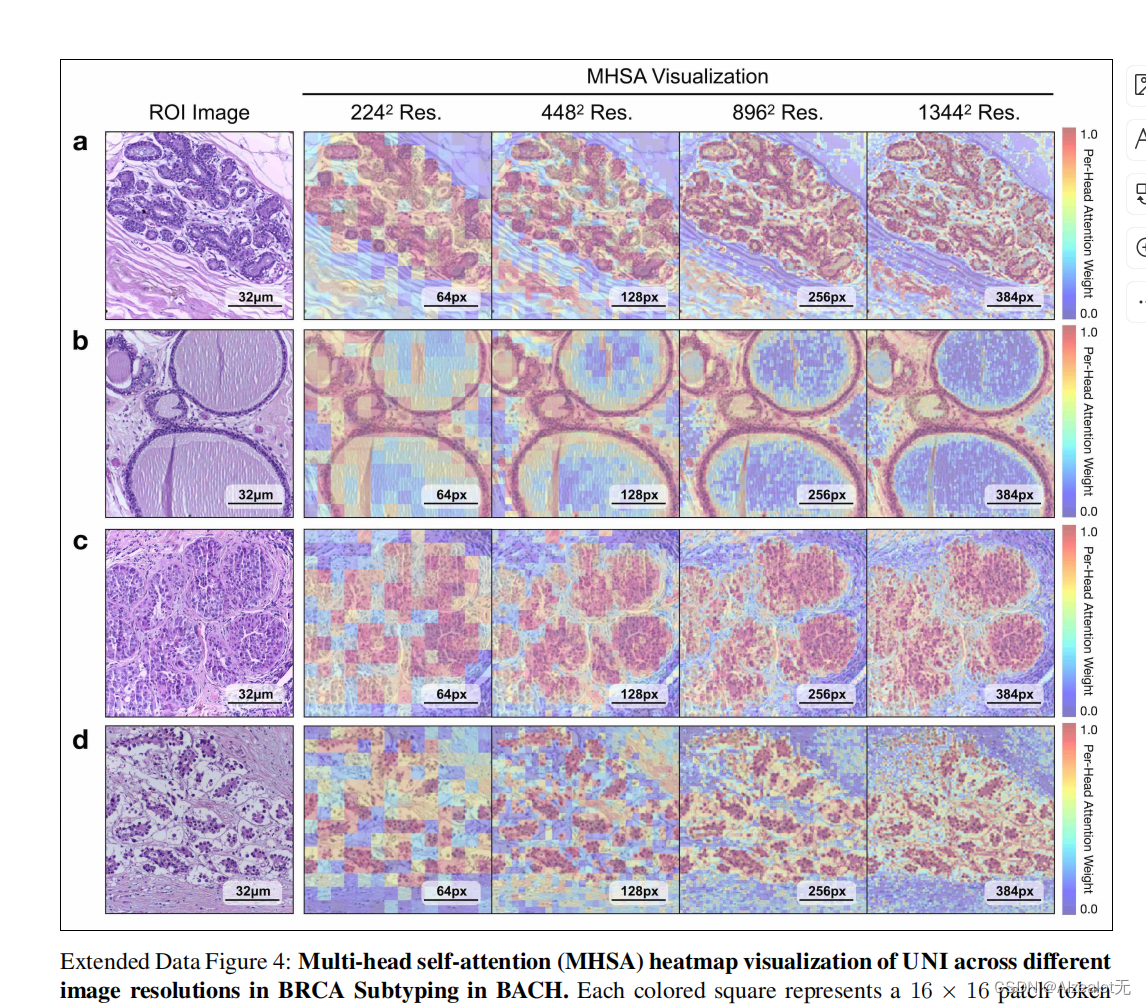
也就是说,模型对病理图片中的小部分区域的处理后的内部是这样的.
这图是分别四种治病等级,从上图的正常知道入侵,内皮的注意力增高,而背景和基质对于诊断没什么帮助,注意力值很低。
三、训练
所用的病例图片数据集:10万张左右,包含20个器官的病理图片:
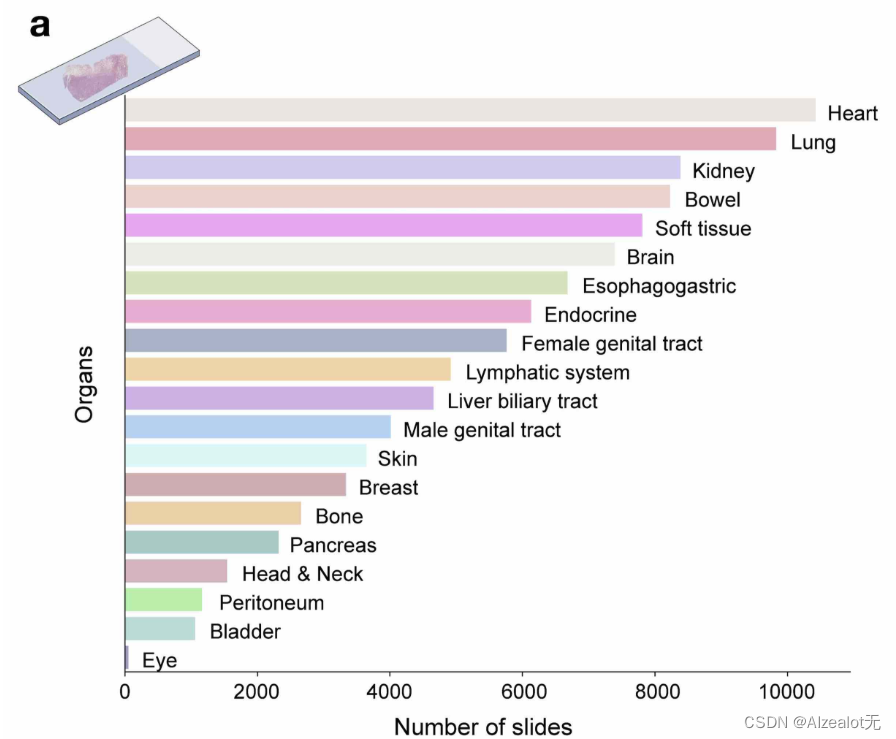
在预训练阶段,本模型使用了一种自监督算法:DINOv2,这种算法能够提取到鲁棒并且即用的
特征.
这种DINOv2算法是一种判别自监督方法。判别自监督方法使用图片或图片组之间的区别信号来学习特征,但是,在DINOv2之前的这类方法很难扩展到大规模的数据。
这种自监督的训练方法使用了一种从NLP中的聚簇方法受启发而实现的流程,以这种流程去利用数据相似性来进行数据的优化。以此能够去解决数据不平衡和因此导致的在少数领域过拟合的现象。
具体的做法,使用在Image-Net-22K预训练过的自监督ViT-H/16计算图像嵌入,然后使用余弦相似度来衡量图片之间的距离,再使用k-means对未优化过的图片进行聚簇。
DINOv2借鉴了很多在图片和批次水平进行特征学习的判别自监督方法,总的来说是DINO和iBOT方法的结合,聚焦于较大规模的数据,使得这种方法更加快速并且占用内存更少。以下是这种流程的示意图:

下图是DINOv2的示意图:
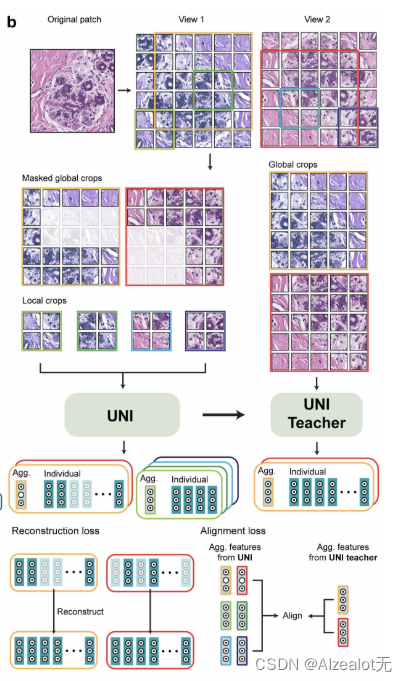
这里的主要流程是:使用ViT对同一张图片,但是不同裁剪(指的是UNI和UNI Teacher的两边)分别提取特征,这两种特征都来自ViT的类别token(不熟悉ViT的读者可以关注博主,近期也会出一期讲解这个模型的),然后将两个token分别输入到各自的可学习MLP头中,得出两个分数,即
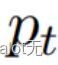 然后用softmax函数处理后,以cross-entropy loss的形式计算得出DINO损失(图像级目标):
然后用softmax函数处理后,以cross-entropy loss的形式计算得出DINO损失(图像级目标):
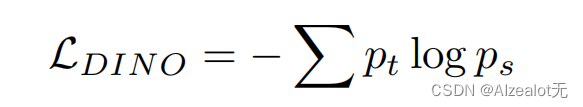
第二个Loss(块级别目标Patch-level objective):
这里很相似,但是不同的是学生的块要随机mask,但是递给教师的patch的token不mask。在原算法即DINOv2的文章中交代了这两个级别的目标头参数是不共享的,在原文章中得出的结论是不共享效果更好,默认本文章使用的这个算法也没有共享,即这两个token是分别传给教师和学生的iBOT头(区别于上述的可学习MLP头),然后类似上一个损失函数
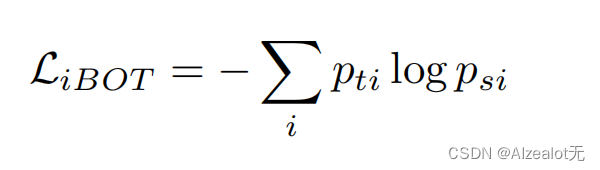
这里的i对应patch的角标
然后,通过这两个Loss更新学生头的参数,使用上一个迭代的指数移动平均值建立教师头。
预训练(在10万张左右HE染色的病理图片上)使用的是4卡80G A100;下游任务是在单卡3090上执行。
三、可执行的下游任务
加入到分割模型(mask2former)进行微调从而执行分割任务,在这个任务上的微调数据集是感兴趣区域级别的细胞分割数据集SegPath,这个任务是先用UNI对silde或者roi进行处理后,经过转化之后,再经过ViT-Adapter后,输入到mask2former模型中进行下游的分割任务,也是本模型所做的唯一的分割任务,还有很多很多的分类任务。
进行少次分类(few shot classification):即每个类别数据使用固定的少量数据集进行下游的微调。
基于类别原型使用提示词激励的半监督学习来检验其检索能力和少次分类学习的能力。
A class prototype is constructed by averaging the extracted features from ROIs of the same class. For a test ROI, SimpleShot assigns the class of the most similar class prototype (smallest Euclidean distance) as the predicted ROI label.
类别原型是使用对感兴趣区域提取的特征进行平均池化后得到;而SimpleShot则对具有和原型最小的欧式距离的感兴趣的区域赋予类别。
其过程入下图: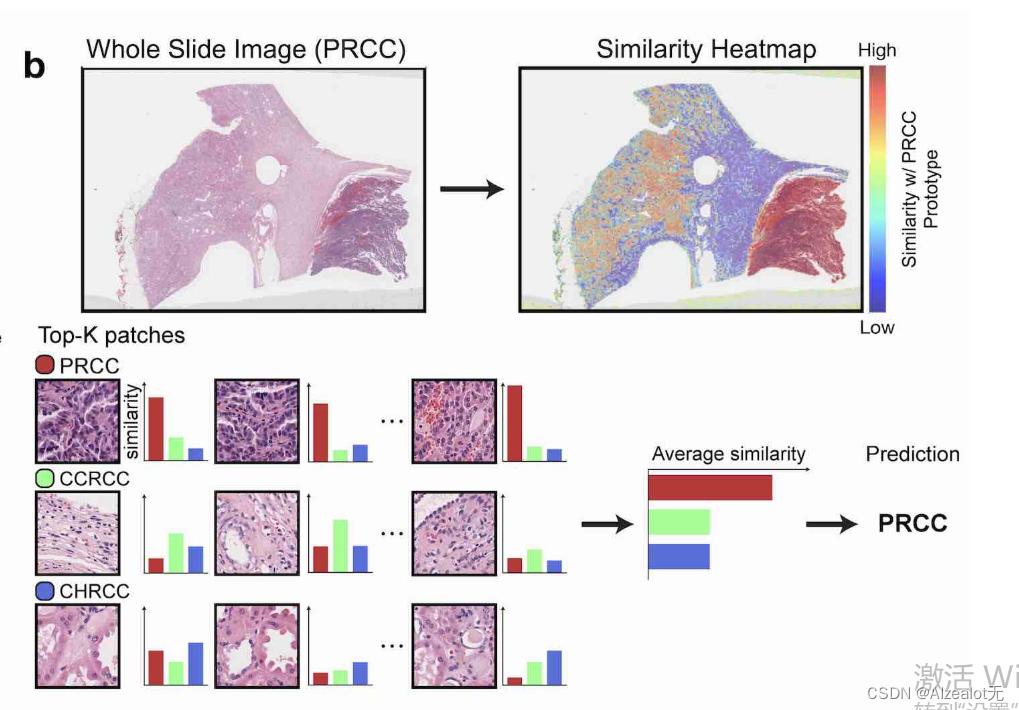
对几个原型计算了相似度,选取对某一原型中的图片具有平均相似度最大的类别为预测结果。
欢迎关注无神,一起学习CV以及医工交叉相关知识
这篇关于论文解读之A General-Purpose Self-Supervised Model for Computational Pathology的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






