本文主要是介绍基于文本来推荐相似酒店,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于文本来推荐相似酒店
查看数据集基本信息
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from sklearn.metrics.pairwise import linear_kernel
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import re
import random
import cufflinks
import cufflinks
from plotly.offline import iplot
df=pd.read_csv("Seattle_Hotels.csv",encoding="latin-1")
df.head()
| name | address | desc | |
|---|---|---|---|
| 0 | Hilton Garden Seattle Downtown | 1821 Boren Avenue, Seattle Washington 98101 USA | Located on the southern tip of Lake Union, the... |
| 1 | Sheraton Grand Seattle | 1400 6th Avenue, Seattle, Washington 98101 USA | Located in the city's vibrant core, the Sherat... |
| 2 | Crowne Plaza Seattle Downtown | 1113 6th Ave, Seattle, WA 98101 | Located in the heart of downtown Seattle, the ... |
| 3 | Kimpton Hotel Monaco Seattle | 1101 4th Ave, Seattle, WA98101 | What?s near our hotel downtown Seattle locatio... |
| 4 | The Westin Seattle | 1900 5th Avenue, Seattle, Washington 98101 USA | Situated amid incredible shopping and iconic a... |
df.shape
(152, 3)
df['desc'][0]
"Located on the southern tip of Lake Union, the Hilton Garden Inn Seattle Downtown hotel is perfectly located for business and leisure. \nThe neighborhood is home to numerous major international companies including Amazon, Google and the Bill & Melinda Gates Foundation. A wealth of eclectic restaurants and bars make this area of Seattle one of the most sought out by locals and visitors. Our proximity to Lake Union allows visitors to take in some of the Pacific Northwest's majestic scenery and enjoy outdoor activities like kayaking and sailing. over 2,000 sq. ft. of versatile space and a complimentary business center. State-of-the-art A/V technology and our helpful staff will guarantee your conference, cocktail reception or wedding is a success. Refresh in the sparkling saltwater pool, or energize with the latest equipment in the 24-hour fitness center. Tastefully decorated and flooded with natural light, our guest rooms and suites offer everything you need to relax and stay productive. Unwind in the bar, and enjoy American cuisine for breakfast, lunch and dinner in our restaurant. The 24-hour Pavilion Pantry? stocks a variety of snacks, drinks and sundries."
查看酒店描述中主要介绍信息
vec=CountVectorizer().fit(df['desc'])
vec=CountVectorizer().fit(df['desc'])
bag_of_words=vec.transform(df['desc'])
sum_words=bag_of_words.sum(axis=0)
words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)
sum_words[1:10]
[('and', 1062),('of', 536),('seattle', 533),('to', 471),('in', 449),('our', 359),('you', 304),('hotel', 295),('with', 280)]
bag_of_words=vec.transform(df['desc'])
bag_of_words.shape
(152, 3200)
bag_of_words.toarray()
array([[0, 1, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 1, 0, 0]], dtype=int64)
sum_words=bag_of_words.sum(axis=0)
sum_words
matrix([[ 1, 11, 11, ..., 2, 6, 2]], dtype=int64)
words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)
sum_words[1:10]
[('and', 1062),('of', 536),('seattle', 533),('to', 471),('in', 449),('our', 359),('you', 304),('hotel', 295),('with', 280)]
将以上信息整合成函数
def get_top_n_words(corpus,n=None):vec=CountVectorizer().fit(df['desc'])bag_of_words=vec.transform(df['desc'])sum_words=bag_of_words.sum(axis=0)words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)return sum_words[:n]
common_words=get_top_n_words(df['desc'],20)
common_words
[('the', 1258),('and', 1062),('of', 536),('seattle', 533),('to', 471),('in', 449),('our', 359),('you', 304),('hotel', 295),('with', 280),('is', 271),('at', 231),('from', 224),('for', 216),('your', 186),('or', 161),('center', 151),('are', 136),('downtown', 133),('on', 129)]
df1=pd.DataFrame(common_words,columns=['desc','count'])
common_words=get_top_n_words(df['desc'],20)
df2=pd.DataFrame(common_words,columns=['desc','count'])
chart_info2=df2.groupby(['desc']).sum().sort_values('count',ascending=False)
chart_info2.plot(kind='barh',figsize=(14,10),title='top 20 before remove stopwords')
<AxesSubplot:title={'center':'top 20 before remove stopwords'}, ylabel='desc'>
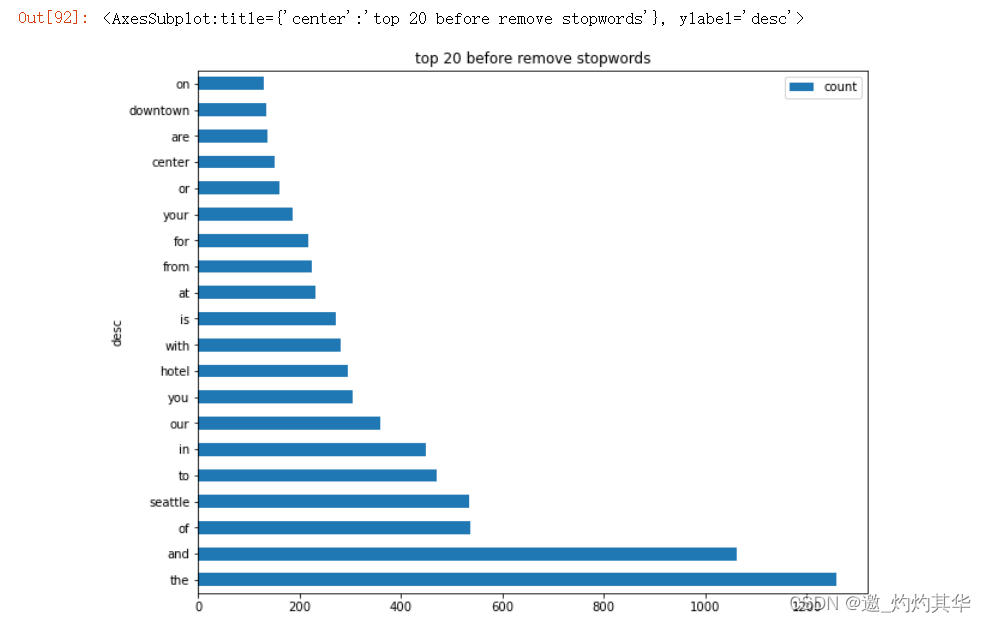
chart_info1=df1.groupby(['desc']).sum().sort_values('count',ascending=False)
chart_info1.plot(kind='barh',figsize=(14,10),title='top 20 before remove stopwords')
<AxesSubplot:title={'center':'top 20 before remove stopwords'}, ylabel='desc'>
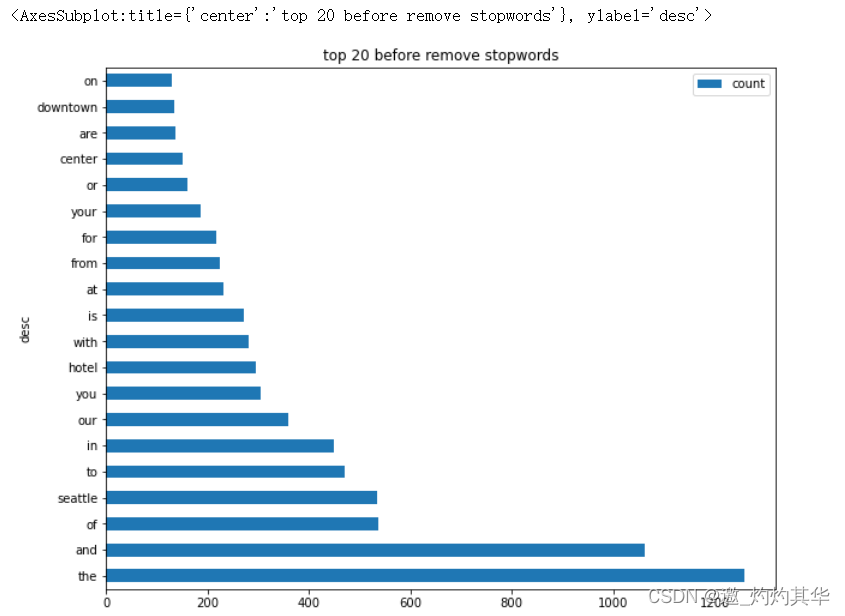
def get_any1_top_n_words_after_stopwords(corpus,n=None):vec=CountVectorizer(stop_words='english',ngram_range=(1,1)).fit(df['desc'])bag_of_words=vec.transform(df['desc'])sum_words=bag_of_words.sum(axis=0)words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)return sum_words[:n]
common_words=get_any1_top_n_words_after_stopwords(df['desc'],20)
df2=pd.DataFrame(common_words,columns=['desc','count'])
chart_info2=df2.groupby(['desc']).sum().sort_values('count',ascending=False)
chart_info2.plot(kind='barh',figsize=(14,10),title='top 20 before after stopwords')
<AxesSubplot:title={'center':'top 20 before after stopwords'}, ylabel='desc'>
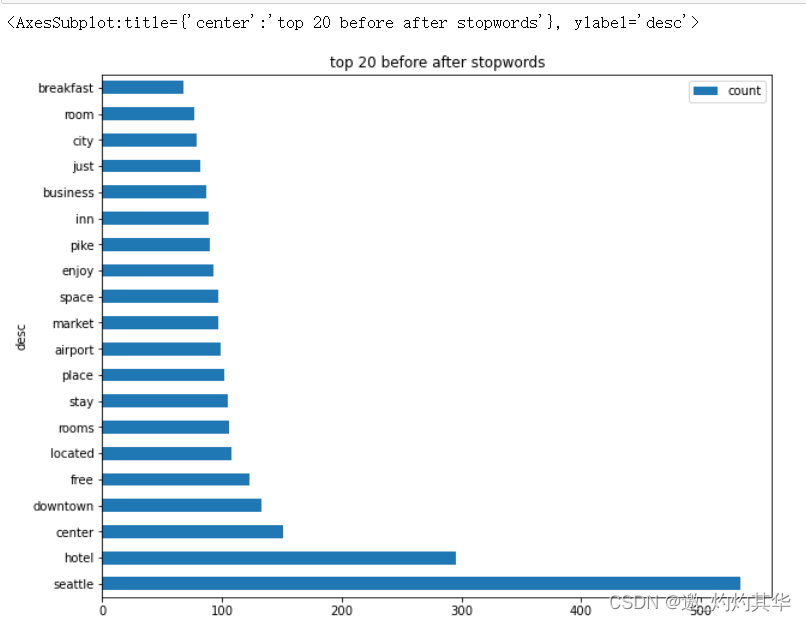
def get_any2_top_n_words_after_stopwords(corpus,n=None):vec=CountVectorizer(stop_words='english',ngram_range=(2,2)).fit(df['desc'])bag_of_words=vec.transform(df['desc'])sum_words=bag_of_words.sum(axis=0)words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)return sum_words[:n]common_words=get_any2_top_n_words_after_stopwords(df['desc'],20)
df2=pd.DataFrame(common_words,columns=['desc','count'])
chart_info2=df2.groupby(['desc']).sum().sort_values('count',ascending=False)
chart_info2.plot(kind='barh',figsize=(14,10),title='top 20 before after stopwords')
<AxesSubplot:title={'center':'top 20 before after stopwords'}, ylabel='desc'>
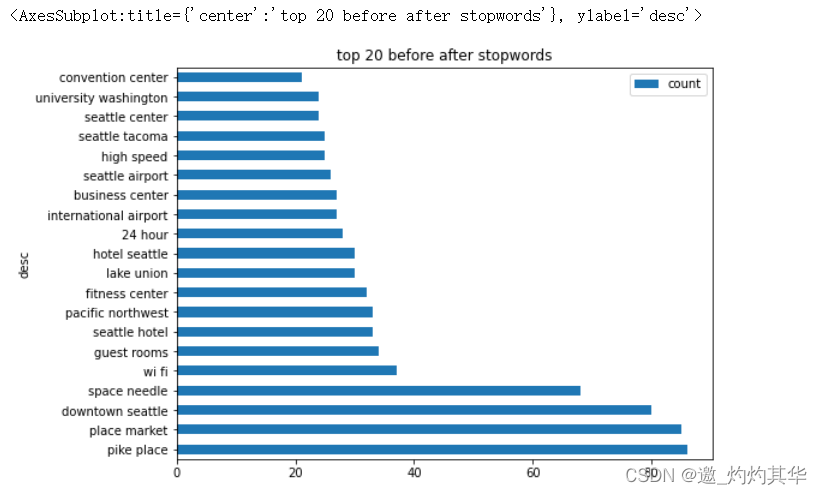
def get_any3_top_n_words_after_stopwords(corpus,n=None):vec=CountVectorizer(stop_words='english',ngram_range=(3,3)).fit(df['desc'])bag_of_words=vec.transform(df['desc'])sum_words=bag_of_words.sum(axis=0)words_freq=[(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]sum_words=sorted(words_freq,key= lambda x: x[1],reverse=True)return sum_words[:n]common_words=get_any3_top_n_words_after_stopwords(df['desc'],20)
df2=pd.DataFrame(common_words,columns=['desc','count'])
chart_info2=df2.groupby(['desc']).sum().sort_values('count',ascending=False)
chart_info2.plot(kind='barh',figsize=(14,10),title='top 20 before after stopwords')
<AxesSubplot:title={'center':'top 20 before after stopwords'}, ylabel='desc'>
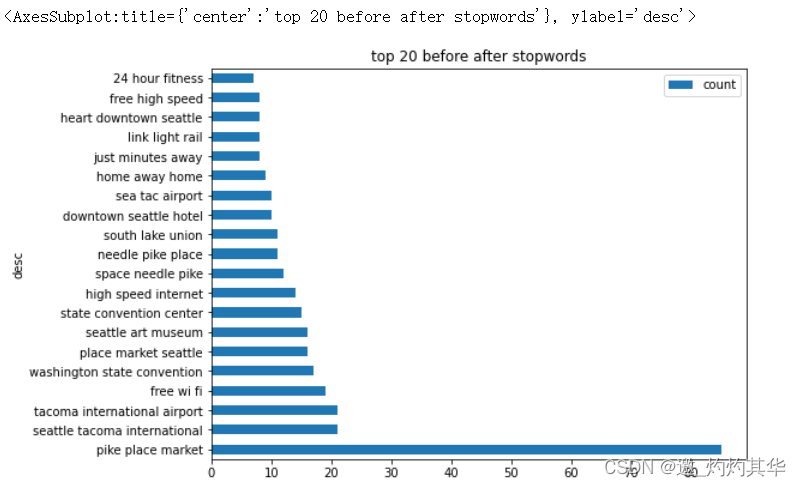
描述的一些统计信息
df=pd.read_csv("Seattle_Hotels.csv",encoding="latin-1")
df['desc'][0]
"Located on the southern tip of Lake Union, the Hilton Garden Inn Seattle Downtown hotel is perfectly located for business and leisure. \nThe neighborhood is home to numerous major international companies including Amazon, Google and the Bill & Melinda Gates Foundation. A wealth of eclectic restaurants and bars make this area of Seattle one of the most sought out by locals and visitors. Our proximity to Lake Union allows visitors to take in some of the Pacific Northwest's majestic scenery and enjoy outdoor activities like kayaking and sailing. over 2,000 sq. ft. of versatile space and a complimentary business center. State-of-the-art A/V technology and our helpful staff will guarantee your conference, cocktail reception or wedding is a success. Refresh in the sparkling saltwater pool, or energize with the latest equipment in the 24-hour fitness center. Tastefully decorated and flooded with natural light, our guest rooms and suites offer everything you need to relax and stay productive. Unwind in the bar, and enjoy American cuisine for breakfast, lunch and dinner in our restaurant. The 24-hour Pavilion Pantry? stocks a variety of snacks, drinks and sundries."
df['word_count']=df['desc'].apply( lambda x:len(str(x).split(' ')) )
df.head()
| name | address | desc | word_count | |
|---|---|---|---|---|
| 0 | Hilton Garden Seattle Downtown | 1821 Boren Avenue, Seattle Washington 98101 USA | Located on the southern tip of Lake Union, the... | 184 |
| 1 | Sheraton Grand Seattle | 1400 6th Avenue, Seattle, Washington 98101 USA | Located in the city's vibrant core, the Sherat... | 152 |
| 2 | Crowne Plaza Seattle Downtown | 1113 6th Ave, Seattle, WA 98101 | Located in the heart of downtown Seattle, the ... | 147 |
| 3 | Kimpton Hotel Monaco Seattle | 1101 4th Ave, Seattle, WA98101 | What?s near our hotel downtown Seattle locatio... | 151 |
| 4 | The Westin Seattle | 1900 5th Avenue, Seattle, Washington 98101 USA | Situated amid incredible shopping and iconic a... | 151 |
df['word_count'].plot(kind='hist',bins=50)
<AxesSubplot:ylabel='Frequency'>
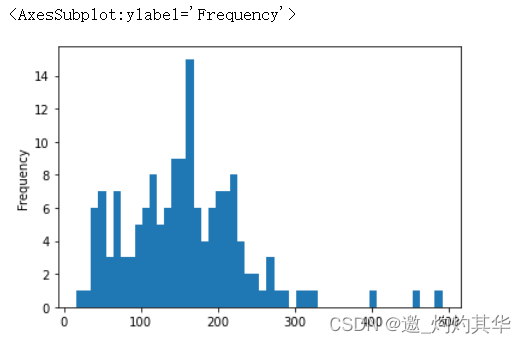
文本处理
sub_replace=re.compile('[^0-9a-z#-]')
from nltk.corpus import stopwords
stopwords=set(stopwords.words('english'))
def clean_txt(text):text.lower()text=sub_replace.sub(' ',text)''.join( word for word in text.split(' ') if word not in stopwords )return text
df['desc_clean']=df['desc'].apply(clean_txt)
df['desc_clean'][0]
' ocated on the southern tip of ake nion the ilton arden nn eattle owntown hotel is perfectly located for business and leisure he neighborhood is home to numerous major international companies including mazon oogle and the ill elinda ates oundation wealth of eclectic restaurants and bars make this area of eattle one of the most sought out by locals and visitors ur proximity to ake nion allows visitors to take in some of the acific orthwest s majestic scenery and enjoy outdoor activities like kayaking and sailing over 2 000 sq ft of versatile space and a complimentary business center tate-of-the-art technology and our helpful staff will guarantee your conference cocktail reception or wedding is a success efresh in the sparkling saltwater pool or energize with the latest equipment in the 24-hour fitness center astefully decorated and flooded with natural light our guest rooms and suites offer everything you need to relax and stay productive nwind in the bar and enjoy merican cuisine for breakfast lunch and dinner in our restaurant he 24-hour avilion antry stocks a variety of snacks drinks and sundries '
相似度计算
df.index
RangeIndex(start=0, stop=152, step=1)
df.head()
| name | address | desc | word_count | desc_clean | |
|---|---|---|---|---|---|
| 0 | Hilton Garden Seattle Downtown | 1821 Boren Avenue, Seattle Washington 98101 USA | Located on the southern tip of Lake Union, the... | 184 | ocated on the southern tip of ake nion the... |
| 1 | Sheraton Grand Seattle | 1400 6th Avenue, Seattle, Washington 98101 USA | Located in the city's vibrant core, the Sherat... | 152 | ocated in the city s vibrant core the herat... |
| 2 | Crowne Plaza Seattle Downtown | 1113 6th Ave, Seattle, WA 98101 | Located in the heart of downtown Seattle, the ... | 147 | ocated in the heart of downtown eattle the ... |
| 3 | Kimpton Hotel Monaco Seattle | 1101 4th Ave, Seattle, WA98101 | What?s near our hotel downtown Seattle locatio... | 151 | hat s near our hotel downtown eattle locatio... |
| 4 | The Westin Seattle | 1900 5th Avenue, Seattle, Washington 98101 USA | Situated amid incredible shopping and iconic a... | 151 | ituated amid incredible shopping and iconic a... |
df.set_index('name' ,inplace=True)
df.index[:5]
Index(['Hilton Garden Seattle Downtown', 'Sheraton Grand Seattle','Crowne Plaza Seattle Downtown', 'Kimpton Hotel Monaco Seattle ','The Westin Seattle'],dtype='object', name='name')
tf=TfidfVectorizer(analyzer='word',ngram_range=(1,3),stop_words='english')#将原始文档集合转换为TF-IDF特性的矩阵。
tf
TfidfVectorizer(ngram_range=(1, 3), stop_words='english')
tfidf_martix=tf.fit_transform(df['desc_clean'])
tfidf_martix.shape
(152, 27694)
cosine_similarity=linear_kernel(tfidf_martix,tfidf_martix)
cosine_similarity.shape
(152, 152)
cosine_similarity[0]
array([1. , 0.01354605, 0.02855898, 0.00666729, 0.02915865,0.01258837, 0.0190937 , 0.0152567 , 0.00689703, 0.01852763,0.01241924, 0.00919602, 0.01189826, 0.01234794, 0.01200711,0.01596218, 0.00979221, 0.04374643, 0.01138524, 0.02334485,0.02358692, 0.00829121, 0.00620275, 0.01700472, 0.0191396 ,0.02340334, 0.03193292, 0.00678849, 0.02272962, 0.0176494 ,0.0125159 , 0.03702338, 0.01569165, 0.02001584, 0.03656467,0.03189017, 0.00644231, 0.01008181, 0.02428547, 0.03327365,0.01367507, 0.00827835, 0.01722986, 0.04135263, 0.03315194,0.01529834, 0.03568623, 0.01294482, 0.03480617, 0.01447235,0.02563783, 0.01650068, 0.03328324, 0.01562323, 0.02703264,0.01315504, 0.02248426, 0.02690816, 0.00565479, 0.02899467,0.02900863, 0.00971019, 0.0439659 , 0.03020971, 0.02166199,0.01487286, 0.03182626, 0.00729518, 0.01764764, 0.01193849,0.02405471, 0.01408249, 0.02632335, 0.02027866, 0.01978292,0.04879328, 0.00244737, 0.01937539, 0.01388813, 0.02996677,0.00756079, 0.01429659, 0.0050572 , 0.00630326, 0.01496956,0.04104425, 0.00911942, 0.00259554, 0.00645944, 0.01460694,0.00794788, 0.00592598, 0.0090397 , 0.00532289, 0.01445326,0.01156657, 0.0098189 , 0.02077998, 0.0116756 , 0.02593775,0.01000463, 0.00533785, 0.0026153 , 0.02261775, 0.00680343,0.01859473, 0.03802118, 0.02078981, 0.01196228, 0.03744293,0.05164375, 0.00760035, 0.02627101, 0.01579335, 0.01852171,0.06768183, 0.01619049, 0.03544484, 0.0126264 , 0.01613638,0.00662941, 0.01184946, 0.01843151, 0.0012407 , 0.00687414,0.00873796, 0.04397665, 0.06798914, 0.00794379, 0.01098165,0.01520306, 0.01257289, 0.02087956, 0.01718063, 0.0292332 ,0.00489742, 0.03096065, 0.01163736, 0.01382631, 0.01386944,0.01888652, 0.02391748, 0.02814364, 0.01467017, 0.00332169,0.0023627 , 0.02348599, 0.00762246, 0.00390889, 0.01277579,0.00247891, 0.00854051])
求酒店的推荐
indices=pd.Series(df.index)
indices[:5]
0 Hilton Garden Seattle Downtown
1 Sheraton Grand Seattle
2 Crowne Plaza Seattle Downtown
3 Kimpton Hotel Monaco Seattle
4 The Westin Seattle
Name: name, dtype: object
def recommendation(name,cosine_similarity):recommend_hotels=[]idx=indices[indices==name].index[0]score_series=pd.Series(cosine_similarity[idx]).sort_values(ascending=False)top_10_indexes=list(score_series[1:11].index)for i in top_10_indexes:recommend_hotels.append(list(df.index)[i])return recommend_hotels
recommendation('Hilton Garden Seattle Downtown',cosine_similarity)
['Staybridge Suites Seattle Downtown - Lake Union','Silver Cloud Inn - Seattle Lake Union','Residence Inn by Marriott Seattle Downtown/Lake Union','MarQueen Hotel','The Charter Hotel Seattle, Curio Collection by Hilton','Embassy Suites by Hilton Seattle Tacoma International Airport','SpringHill Suites Seattle\xa0Downtown','Courtyard by Marriott Seattle Downtown/Pioneer Square','The Loyal Inn','EVEN Hotel Seattle - South Lake Union']
这篇关于基于文本来推荐相似酒店的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




