本文主要是介绍数据中心、HPC、AI等应用场景互联协议混战哪家强?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生成式人工智能快速发展对算力与存力呈指数需求增长,进一步加剧了算力与存力之间既有矛盾,时代在呼唤更大的运力(即计算与存储之间的数据传输)--AIGC时代需要更大带宽,更为快速的数据传输路径。
众所周知,PCIE是目前所知最为常见的高性能I/O通信协议,但受限于PCIE总线的树形拓扑以及有限的设备标识ID号码范围,致使其无法形成一个大规模网络。尤其在NVMe大规模使用时占用大量的PCIe线路,使其原本就为紧张的通道更显捉襟见肘,同时也限制了GPU、NIC、FPGA/ASIC卡的接入数量。尽管可以使用PCIe Switch来缓解通道数量不够的问题,对于PCIE总线设备ID号的不足,PCIE Switch并没有可以一劳永逸的解决方案。
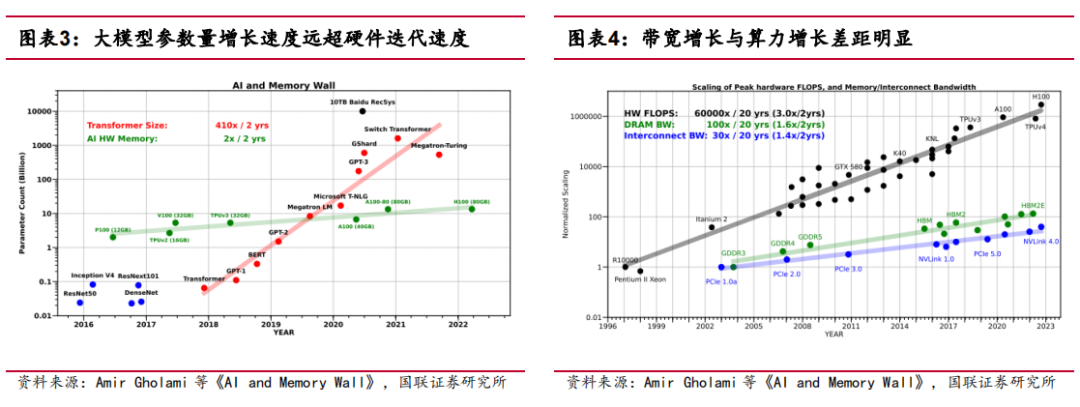
除此之外,PCIE的设计还存在两个致命的缺陷:存储器地址空间隔离、不支持Cache Coherency事务。PCIE原本设计初衷是地址空间是私有的,它与原有的CPU地址空间不相融合,需要借助地址翻译寄存器来做基地址翻译。尽管这并不影响CPU与PCIE互相访问地址中的数据,但由于PCIE事务层不支持Cache Cohernecy事务的处理,因此PCIE设备端无法缓存CPU地址域中的数据,这直接导致数据通信时的延迟。
为了解决上述问题,英特尔在2019年联合业界推出了Compute Express Link(CXL技术协议)用以加速CPU与GPU以及FPGA等异构结构之间的互联通信。总的说来,CXL基于PCIE技术,通过将设备挂载到PCIe总线上,实现了设备到CPU之间的互联。CXL可以视为PCIE技术的升级版本,因此它兼容现有PCIe端口的处理器(绝大部分的通用CPU、GPU 和 FPGA)。CXL 通过将计算和存储分离,形成内存池,从而能动态按需配置内存资源,提升数据中心工作效率。CXL作为一种新出现的技术,几乎一年一次更新。
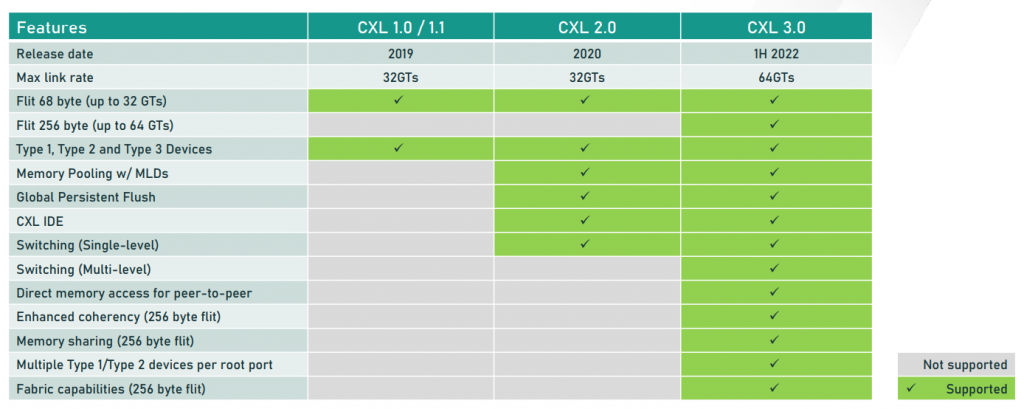
在CXL1.0的技术基础上,CXL2.0增加了一个重要的功能:它成功实现了内存资源的池化。通信瓶颈的问题由来已久,随着NVMe硬盘的推出,迟延得到大幅度降低,但是吞吐依然是很明显的缺陷,因此并不能完全替代内存,随着AI/ML等对高速I/O的需求,因此池化成为了最佳选择。CXL2.0的架构支持Memory sharing技术,而这种技术成功突破了某一个物理内存只能属于某一台服务器的限制,在硬件上实现了多机共同访问同样内存地址的能力,能够跨系统设备实现资源共享。目前CXL已经升级到了3.0版本,带宽提升了两倍,支持更复杂的连接拓扑,如通过它使多个Switch互相连接,可以实现上百个服务器互联并共享内存。
而Gen-Z则是除了CXL互联技术之外,在数据中心、高性能计算领域、AI领域等场景的全新数据设备互联协议的另一统治者。Gen-Z的出现主要是为了弥补CXL在服务器节点外部的机架层级,远距离传输和大规模拓扑互联场景的缺陷。值得一提的是,在2022年Gen-Z 联盟同意接入CXL 技术协议,两个联盟实现了协议兼容。
英伟达也推出了其自主研发的NVLink技术,NVLink同样提供高带宽,适用于连接NVIDIA GPU。NVLink也支持GPU之间的内存共享,优化了大规模并行计算的性能,在GPU之间的通信中具有更低的延迟。NVLink可以支持CPU-GPU间链路也可以支持GPU-GPU间链路。除此之外,英伟达还研发了自己的 NVLink Switch,支持搭载16个GPU+NVLink Switch,不过价格昂贵。
CXL擅长于计算相关的数据处理,如数据中心、人工智能、科学计算等应用领域,具备更高的灵活性与高性能,而NVLink主要用于连接NVIDIA GPU,在图形处理和深度学习等领域表现出色。
其实在最初为了解决 CPU 和设备、设备和设备之间的内存鸿沟,IBM就率先推出了CAPI(Coherent Accelerator Processor Interface)接口,但由于IBM在数据中心设备占比率低与日渐式微的影响力,CAPI并没有得到大规模的使用,而后又演变了逐渐演化成了OpenCAPI。而后ARM又加入另一个开放的访存和I/O网络平台(CCIX)Cache Coherent Interconnect for Accelerators。总而言之,在研发推出的时间上:CAPI->GenZ->CCIX->NVLINK->CXL。
尽管解决处理器与内存之间通讯瓶颈之路永无止境,但我们可以清晰预见在不远的将来,随着CXL技术的发展,内存资源彻底池化,服务器的外观形态将会发生根本的变化,存储和处理器会被分离开来,放在彼此独立的机箱内。
这篇关于数据中心、HPC、AI等应用场景互联协议混战哪家强?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





