本文主要是介绍AI分析SP和pk进行sk分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SP原始表行标题代表题目序号,列代表学生,如果学生答对题目为1,否则为0。问题知识点矩阵这个文件横轴代表每个知识点,列标题代表每个题目序号,如果题目包含这个知识点则该处值为1。通过两个文件判断学生对于每个知识点的掌握,生成一个Excel,列为学生,行标题为知识点。如果学生对每个知识点关联的题目都能答对吗,值为2,都答错值为0,一些答对一些答错值为1
1
按行遍历这个Excel中含1的单元格返回该单元格所在列
2
到这一步能成功返回结果
import pandas as pd# 读取Excel文件
df1 = pd.read_excel('问题-知识点矩阵.xlsx')class knowledge:def __init__(self, name):self.name = nameflag=0class question:def __init__(self, name):self.name = nameself.knowledge = []self.flag=0class student:def __init__(self, name):self.name = nameself.question= []# 创建student列表
students = []
questions = []knowledges=[]# 第一列的列名
first_column_name = df1.columns[0]students = []def get_student_results(file_path):# 读取Excel文件df = pd.read_excel(file_path)# 初始化一个空字典来存储结果results = {}# 遍历数据框的每一行for index, row in df.iterrows():# 初始化student对象student_obj = student(row['学生'])# 遍历除'学生'列之外的其他列for col in df.columns[1:]:# 检查学生的答案是否为1(正确)或0(错误)if row[col] == 1:flag = 1else:flag = 0# 创建question对象,并设置flagquestion_obj = question(col)question_obj.flag = flag# 将question对象添加到student对象的question列表中for index, value in df1[first_column_name].items():# 找到当前行中所有包含1的列ones_columns = [col for col in df1.columns[1:] if df1.at[index, col] == 1]# 遍历ones_columns列表中的每个列名# 创建question对象#print(question_obj.name)if question_obj.name == value:#value 是 题目#print(value)for col in ones_columns:# 将question对象添加到questions列表中question_obj.knowledge.append(col)questions.append(question_obj)student_obj.question.append(question_obj)# 遍历第一列的所有元素# 将student对象添加到students列表中students.append(student_obj)
get_student_results('sp原始表.xlsx')
# 遍历student列表,打印
for student in students:print(student.name)for question in student.question:print(question.name, question.flag)for knowledge in question.knowledge:print(knowledge)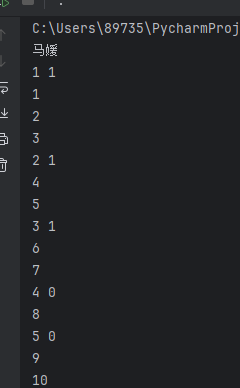
分别返回 题目:答对还是打错
涉及到的知识点包括
。
成功获取集合:
import pandas as pd# 读取Excel文件
df1 = pd.read_excel('问题-知识点矩阵.xlsx')class knowledge:def __init__(self, name):self.name = nameflag=0class question:def __init__(self, name):self.name = nameself.knowledge = []self.flag=0class student:def __init__(self, name):self.name = nameself.question= []# 创建student列表
students = []
questions = []knowledges=[]# 第一列的列名
first_column_name = df1.columns[0]students = []def get_student_results(file_path):# 读取Excel文件df = pd.read_excel(file_path)# 初始化一个空字典来存储结果results = {}# 遍历数据框的每一行for index, row in df.iterrows():# 初始化student对象student_obj = student(row['学生'])# 遍历除'学生'列之外的其他列for col in df.columns[1:]:# 检查学生的答案是否为1(正确)或0(错误)if row[col] == 1:flag = 1else:flag = 0# 创建question对象,并设置flagquestion_obj = question(col)question_obj.flag = flag# 将question对象添加到student对象的question列表中for index, value in df1[first_column_name].items():# 找到当前行中所有包含1的列ones_columns = [col for col in df1.columns[1:] if df1.at[index, col] == 1]# 遍历ones_columns列表中的每个列名# 创建question对象#print(question_obj.name)if question_obj.name == value:#value 是 题目#print(value)for col in ones_columns:# 将question对象添加到questions列表中question_obj.knowledge.append(col)questions.append(question_obj)student_obj.question.append(question_obj)# 遍历第一列的所有元素# 将student对象添加到students列表中students.append(student_obj)
get_student_results('sp原始表.xlsx')right=[]
worng=[]
hunhe=[]
name=[]# 更改类名为AllResults以避免与内置函数all()冲突
class AllResults:def __init__(self, name):self.name = nameself.right = [] # 答对的知识点self.wrong = [] # 答错的知识点self.hunhe = [] # 交集,即答对和答错中都有的知识点# 假设students是已经定义好的学生列表
# students = [...]# 初始化存储结果的列表
all_results_list = []for student in students:# 创建AllResults实例all_results = AllResults(student.name)right_set = set() # 使用集合来避免重复wrong_set = set()for question in student.question:if question.flag == 1:right_set.update(question.knowledge)elif question.flag == 0:wrong_set.update(question.knowledge)# 更新AllResults实例的属性all_results.right.extend(right_set)all_results.wrong.extend(wrong_set)all_results.hunhe.extend(right_set.intersection(wrong_set))# 移除交集部分all_results.right = list(right_set - wrong_set)all_results.wrong = list(wrong_set - right_set)# 添加到结果列表all_results_list.append(all_results)# 遍历all_results_list,写入txt文件
for i, all_results in enumerate(all_results_list):with open(f'{all_results.name}.txt', 'w') as f:f.write(f'{all_results.name}\n')f.write(f'答对知识点:{all_results.right}\n')f.write(f'答错知识点:{all_results.wrong}\n')f.write(f'交集知识点:{all_results.hunhe}\n')下面开始判断
sk:
我要判断的是每个学生对于不同的问题,这些不同问题下面的相同知识点的flag是否一致
判断knowledge.name 的name相同的知识点 的flagflag是否都是1,或者都是0,或者有1有0三种情况
,返回给我关于每个knowledge.name所在的三种情况class AllResults:
def init(self, name):
self.name = name
self.right = [] # 答对的知识点
self.wrong = [] # 答错的知识点
self.hunhe = [] # 交集,即答对和答错中都有的知识点 写本地代码把AllResults类中的name和s.xlsx对应以后,s.xlsx的表头是知识点,self.right = [] #
答对的知识点里面单元格填2,self.wrong = [] # 答错的知识点单元格填0, self.hunhe = [] #
交集,即答对和答错中都有的知识点用1填充,无需你运行,给我代码
这篇关于AI分析SP和pk进行sk分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







