本文主要是介绍论文解读 Combating Adversarial Misspellings with Robust Word Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 简介
论文链接 https://www.aclweb.org/anthology/P19-1561.pdf
这篇文章发表在ACL19,目的是为了解决错误拼写的对抗(adversarial misspellings)问题。尽管现在的deep learning和Transformer已经非常先进,但是当他们面对错误拼写时仍然十分的脆弱(brittle),一个单词的字母写错就可以愚弄(fool)这些高级的算法。
比如一个垃圾邮件的生产者(spammer)仅对邮件的几个字母轻微修改就可以骗过垃圾邮件识别系统,从而成功地将广告邮件送到您的电子邮箱中。
在这篇文章中,作者提出使用一个拼写检查器(spelling corrector)可以有效解决这种错误拼写的对抗攻击。具体的方法是在将文本输入喂给下游模型之前,调用检查器对其中的错误拼写进行改正,之后再将优化的文本喂给下游模型。
这种方法直观而且有效,在BERT模型上,一个简单单字符攻击(single character attack)可以使其在情感分析任务上由准确率90.3%下降到45.8%,而在使用本文的防守(defense)方法后,准确率可以恢复到75%。
2. 模型
为了对抗字符级别的对抗攻击,作者提出了一个二阶段的解决方案:在下游分类器(C)之前放一个单词识别模型(W)。
这种方法有两个优点
- 一个单词识别模型可以被重复利用,也就是这种方法是与任务无关的(task-agnostic)
- 单词识别模型可以单独在一个大规模预料上训练,而不必受限于任务的数据规模
在对抗攻击时,我们需要考虑两个因素,一个是单词识别模型的准确率(Accuracy or Error Rate),这意味着这个纠错器的性能,是不是能把所有错别字纠正成原有准确的词。
另一个需要考虑的是单词识别模型的敏感度(sensitivity),这是作者定义的一个指标。具体地说,对于一个输入的句子和攻击器,我们可以生成多个受攻击的句子,那么我们期望在使用纠错模型后,所有的这些句子都是一模一样的。
灵敏度高的模型在纠错后会有多个不同的句子,而灵敏度低的纠错模型会稳定的将所有句子映射成完全一样的句子。这么来看灵敏度当然是越低越好,这样无论你怎么攻击,我都能把句子还原成原有的意思。
但是,作者在实验中发现,纠错模型的准确率和灵敏度是相互影响的,鱼和熊掌的问题,我们需要在其中做一个权衡(trade-off)。
2.1 纠错模型
作者使用的是半字符的RNNs模型,具体参考的这篇文章。我们不对这个模型做过多的介绍,有兴趣的同学可以自行查看。
上面的这个模型有一个缺点,就是仅在有限的单词集合上,这回产生许多未知的词UNK,作者针对这种问题提出了三种解决方案
- Pass-through。对UNK单词不做任何操作
- Backoff to neutral word。对UNK单词补偿一个中立词,比如‘a’
- Backoff to background model。训练一个更大规模的纠错模型去解决UNK单词
如下图所示,如果Foreground纠错模型预测为UNK,就唤醒Background纠错模型。

2.2 模型的敏感度(Sensibility)
设想,如果一个模型将字符攻击的单词都使用UNK表示,那么这种模型其实是非常鲁棒的(Robust),因为它将各种类型的攻击都使用UNK表示了。
而一个单词加上字符的模型或者使用Sub-word的模型很容易受到各种攻击的影响,这样看感觉很有意思,简单的模型反而鲁棒性好,而复杂的模型鲁棒性却低。
如何量化这种现象呢,作者定义了敏感度这一概念,如下公式,W是纠错模型,V是一个函数将句子转化成ID列表,Si是一个相同的句子被攻击后的句子。#u是一个计数器,用来数这个集合中一共有多少不一样的ID列表(也就是不同的句子)。
这个指标越高,说明纠错器对攻击越敏感,指标越高说明对攻击就不敏感。我们当然需要低敏感度的纠错器,这样无论你怎么攻击,我都可以将被攻击的句子还原成一样的句子。
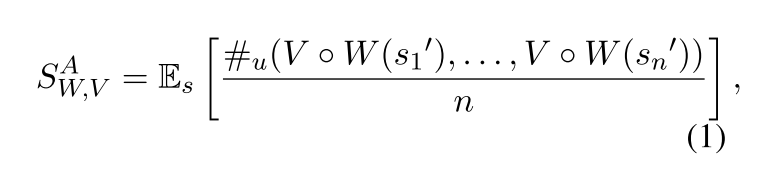
2.3 人工的对抗攻击
这篇文章只关注对情感分析的攻击,也就是文本分类,作者定义了文本分类在对抗攻击下的鲁棒性(Robustness),这表示在对抗攻击下的模型的准确率。

允许的攻击(Allowed Pertubations)
这篇文章里允许四种攻击类型
- Swap。交换一个单词内的两个字符
- Drop。丢弃单词内的一个字符
- Keyboard。使用键盘距离替换单词内的字母
- ADD。在单词内部插入一个字符
为了使攻击后的单词人还能理解,只对单词内部进行操作,长度小于4的单词不做攻击
攻击策略(Attack Strategy)
对于单字符攻击,使用以上各种策略直到找到一种能够使分类器发生错误的攻击。
对于双字符攻击,基于单字符攻击再加上以上任意一种攻击。
3. 实验
3.1 单词纠错器的错误率
如下表所示,作者改良版的ScRNN单词错误率最低,而且Background方法是非常有效的。

3.2 对抗攻击下的鲁棒性
作者对四种不同的结构的模型进行攻击,发现加了纠错器能有效防御攻击,比如BERT模型那里,加不加纠错器准确率能差绝对25个百分点。
其次,尽管Background模型单词错误率最低,但是表现不是最好,这说明一个坚固的防守应该给与攻击者更少的选择,即低敏感度的模型。

3.3 理解模型的敏感度
首先作者分析不同策略的敏感度,如下表所示,Neutral策略的敏感度最低,所以在抵抗攻击时表现最好。

其次,作者分析了敏感度、错误率和鲁棒性之间的关系,如下图所示,我们可以看出,错误率貌似跟鲁棒性关系不大,反而敏感度越低鲁棒性就好。

总结
本文提出的方法可谓简单而且有效,作者详细分析了鲁棒性、错误率、敏感度之间的关系,但实际上我总觉得敏感度和鲁棒性这里有些反直觉。
纠错模型表现越好反而越容易受到攻击,尽管作者引入了敏感度进行解释,但是还是迷迷糊糊。
如果说缺点的话,那就是下游模型依赖于纠错器,会产生效率问题、错误传播问题。
这篇关于论文解读 Combating Adversarial Misspellings with Robust Word Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







