本文主要是介绍llama3-8b-instruct-262k微调过程的问题笔记(场景为llama论文审稿),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、环境配置
1.1、模型
1.2、微调环境
1.3、微调数据
二、发现的问题
2.1、过拟合问题
2.2、Qlora zero3 保存模型时OOM问题(已解决)
一、环境配置
1.1、模型
llama3-8b-instruct-262k (英文)
1.2、微调环境
Package Version
----------------------------- -----------
absl-py 2.1.0
accelerate 0.31.0.dev0
aiohttp 3.9.5
aiosignal 1.3.1
annotated-types 0.7.0
anyio 4.3.0
async-timeout 4.0.3
attrs 23.2.0
bitsandbytes 0.43.1
certifi 2024.2.2
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
contourpy 1.2.1
cryptography 42.0.7
cycler 0.12.1
datasets 2.19.1
datatrove 0.2.0
deepspeed 0.14.0
Deprecated 1.2.14
dill 0.3.8
docker-pycreds 0.4.0
docstring_parser 0.16
einops 0.8.0
et-xmlfile 1.1.0
evaluate 0.4.2
exceptiongroup 1.2.1
filelock 3.14.0
flash-attn 2.5.7
fonttools 4.51.0
frozenlist 1.4.1
fsspec 2024.3.1
gitdb 4.0.11
GitPython 3.1.43
grpcio 1.64.0
h11 0.14.0
hf_transfer 0.1.6
hjson 3.1.0
httpcore 1.0.5
httpx 0.27.0
huggingface-hub 0.23.1
humanize 4.9.0
idna 3.7
Jinja2 3.1.4
joblib 1.4.2
kiwisolver 1.4.5
loguru 0.7.2
Markdown 3.6
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.9.0
mdurl 0.1.2
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.16
networkx 3.3
ninja 1.11.1.1
nltk 3.8.1
numpy 1.26.4
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.19.3
nvidia-nvjitlink-cu12 12.5.40
nvidia-nvtx-cu12 12.1.105
openpyxl 3.1.2
packaging 24.0
pandas 2.2.2
peft 0.11.2.dev0
pillow 10.3.0
pip 24.0
platformdirs 4.2.2
protobuf 3.20.3
psutil 5.9.8
py-cpuinfo 9.0.0
pyarrow 16.1.0
pyarrow-hotfix 0.6
pycparser 2.22
pydantic 2.7.1
pydantic_core 2.18.2
PyGithub 2.3.0
Pygments 2.18.0
PyJWT 2.8.0
PyNaCl 1.5.0
pynvml 11.5.0
pyparsing 3.1.2
python-dateutil 2.9.0.post0
pytz 2024.1
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.2
rich 13.7.1
safetensors 0.4.3
scikit-learn 1.5.0
scipy 1.13.1
sentencepiece 0.2.0
sentry-sdk 2.3.1
setproctitle 1.3.3
setuptools 69.5.1
shtab 1.7.1
six 1.16.0
smmap 5.0.1
sniffio 1.3.1
sympy 1.12
tensorboard 2.16.2
tensorboard-data-server 0.7.2
threadpoolctl 3.5.0
tiktoken 0.7.0
tokenizers 0.19.1
torch 2.2.1
tqdm 4.66.4
transformers 4.42.0.dev0
transformers-stream-generator 0.0.5
triton 2.2.0
trl 0.8.7.dev0
typing_extensions 4.12.0
tyro 0.8.4
tzdata 2024.1
unsloth 2024.5
urllib3 2.2.1
wandb 0.17.0
Werkzeug 3.0.3
wheel 0.43.0
wrapt 1.16.0
xformers 0.0.25
xxhash 3.4.1
yarl 1.9.4
1.3、微调数据
- 数量:1.5k
- 格式:jsonl,字典的key:input: paper, output: review
二、发现的问题
2.1、过拟合问题
问题简述:
整个微调的过程中没有使用合适的验证集验证最佳模型保存时机,一是因为数据量太少,使用少量的验证集验证不具有可信度,二是选择什么样的方式进行验证。由于没有相关验证集验证的过程,模型训练epoch过高过拟合反而推理会效果会变差,下面是推理效果比较(yarn那篇论文,除了迭代次数140的模型仅推理一次,其他迭代次数推理都是用了多次推理取较好的结果)
引申一些问题:
1. early stop:不同的数据最佳模型的迭代次数不一样,怎么精准判断最佳模型的迭代次数,保存最佳模型(仅通过loss判断可能有待商榷,因为模型推理的语言风格也是比较重要的考量方式,差别可以看下面的截图实例)
2. 验证集的验证方法选择什么样的方式来判断最佳模型
- 迭代批次为140的(仅推理一次),1.4 左右epoch

- 迭代批次为260的(推理多次取了最优的效果),2.7左右epoch

- 迭代批次为280的(推理多次取了最优的效果),2.9左右epoch

2.2、Qlora zero3 保存模型时OOM问题(已解决)
问题简述:
我使用longqlora zero3模型微调 llama3-8b-instruct-262k,开启了shift short attention + flash attention v2,训练的过程中一切正常,loss正常下降,使用的设备为 A6000 (48G),占用的显存为30G左右,但在trainer保存模型时(模型 + zero3 优化器状态),显存的占用会出现短暂的暴涨为58G,模型保存后显存暂用恢复至30G左右。
我使用A100尝试关闭shift short attention,仅使用flash attention v2训练,依然在模型保存时显存占用增加,但A100为80G显存,训练便正常进行了
疑问❓:为何仅仅在模型保存的时候显存会出现爆发式增加呢?
- 正常的训练的显存占用
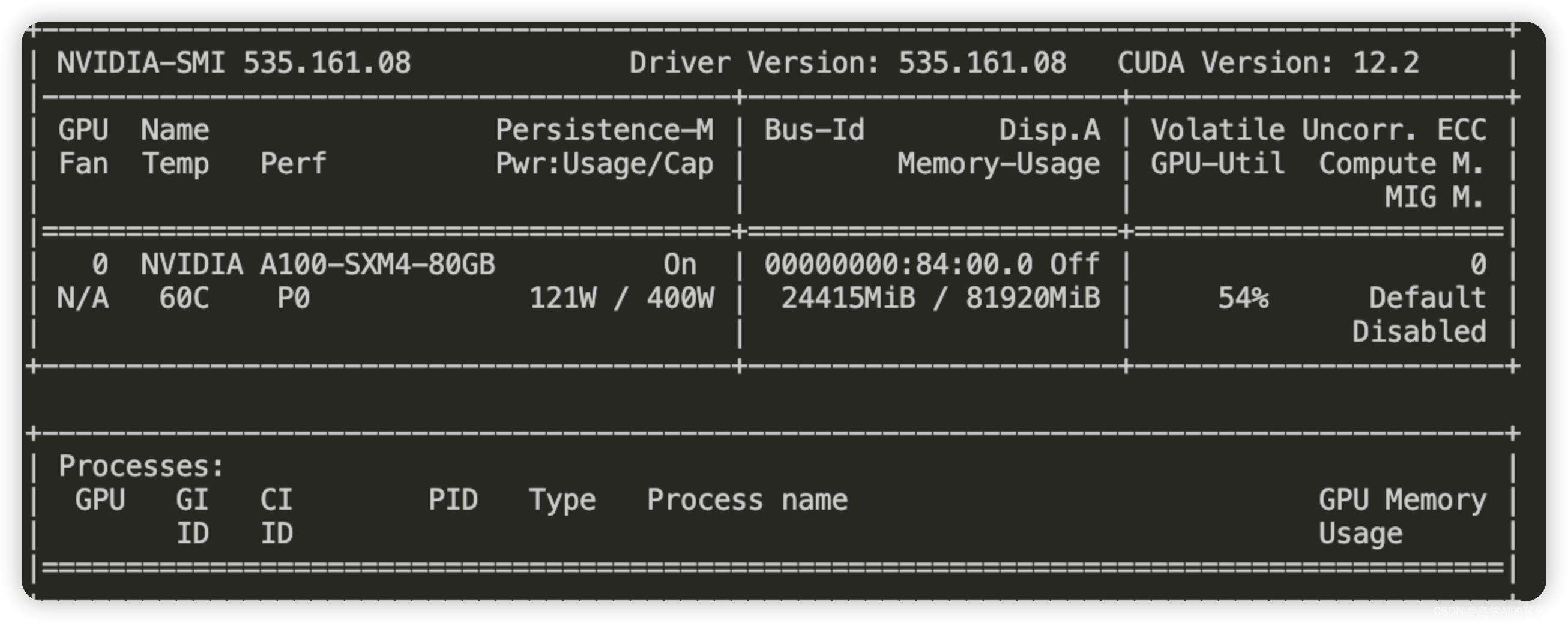
- 保存model时显存瞬间占用
(图:略)
- 排查问题与解决方式:per_device_eval_batch_size设置太大了,模型保存时会进行验证集验证过程,per_device_eval_batch_size 设置小一些降低显存溢出的可能性。
这篇关于llama3-8b-instruct-262k微调过程的问题笔记(场景为llama论文审稿)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








