本文主要是介绍【Python】【Scrapy 爬虫】理解HTML和XPath,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为了从网页中抽取信息,必须对其结构有更多了解。我们快速浏览HTML、HTML的树状表示,以及在网页上选取信息的一种方式XPath。
HTML、DOM树表示以及XPath
互联网是如何工作的?
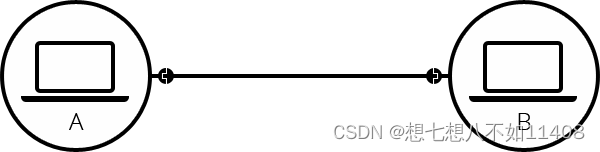
当两台电脑需要通信的时候,你必须要连接他们,无论通过有线方式 (通常是网线) 还是无线方式(比如 WiFi 或 蓝牙 )。所有现代电脑都支持这些连接。
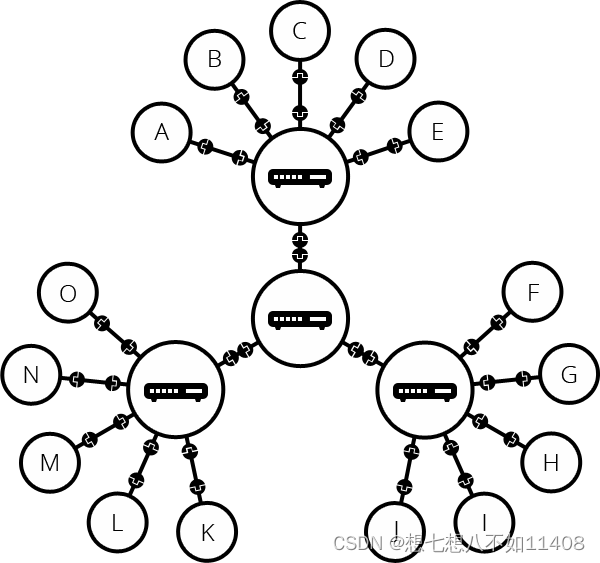
但是当电脑多了,两两链接就会需要很多的网线,这个时候我们将网络上的每台电脑接到一个叫做路由器(router)的特殊小电脑。路由器只干一件事:就像火车站的信号员,它要确保从一台电脑上发出的一条信息可以到达正确的电脑。
但是我们要连接成百上千,上亿台电脑呢?一台路由器覆盖不了这么远,所以我们为什么不把两个路由器彼此连接呢?我们把电脑连接路由器,接着路由器连接路由器,我们就会有无穷的规模。
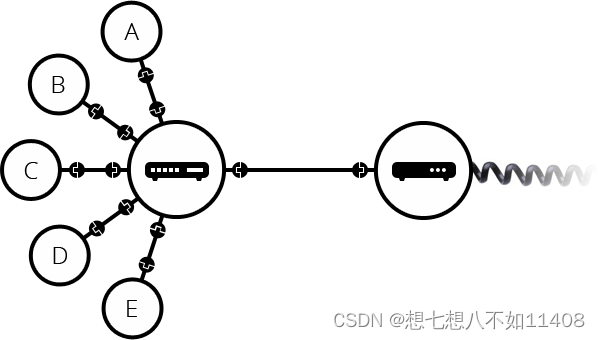
这样网络越来越接近我们所说的互联网,但是我们遗漏了一些东西。我们建立网络是为了我们自己的目的。所以不同的人会建立不同的网络:你的朋友,你的邻居,每个人都可以拥有自己的计算机网络。在你的房子和世界其他地方之间架设电缆将这些不同的网络连接起来是不可能的,那么你该如何处理这件事呢?其实已经有电缆连接到你的房子了,比如,电线和电话。电话基础设施已经可以把你家连接到世界的任何角落,所以它就是我们需要的线。为了连接电话这种网络我们需要一种基础设备叫做调制解调器(modem),调制解调器可以把网络信息变成电话设施可以处理的信息,反之亦然。
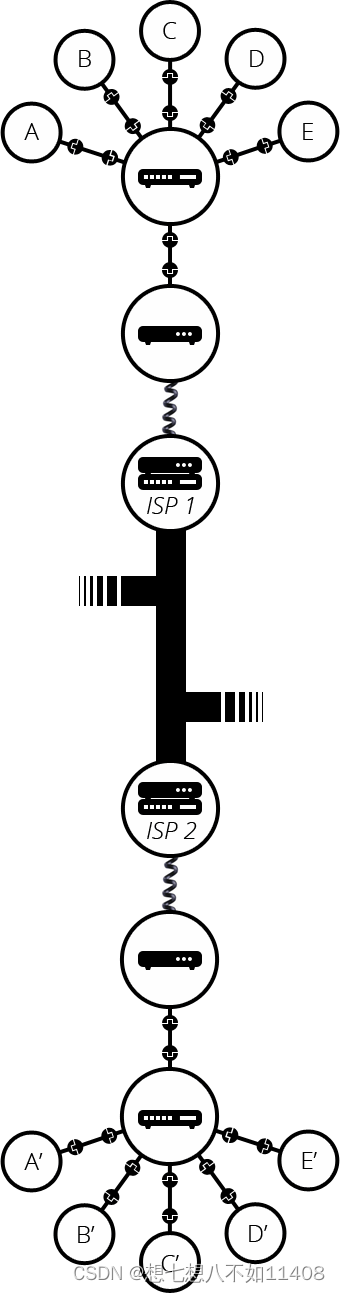
这样,我们可以通过电话基础设施相互连接。下一步是把信息从我们的网络发送到我们想要到达的地方。为了做这些,我们需要把我们的网络连接到互联网服务提供商(Internet Service Provider,ISP)。ISP 是一家可以管理一些特殊的路由器的公司,这些路由器连接其他 ISP 的路由器。你的网络消息可以被 ISP 捕获并发送到相应的网络。互联网就是由这些所有的网络设施所组成。
为了确定信息发送的地址,任何连接到网络中的电脑都需要有一个唯一的地址来标记它,叫做 "IP 地址" (IP 代表网络协议)。这个地址由四部分被点分隔的数字序列组成,比如:
192.168.2.10。但是数字对于人来说并不好读,于是我们给 IP 地址取一个容易阅读的别名:域名。比如,
google.com被用于 IP 地址172.217.7.14。这样我们通过这些域名可以很容易的通过网络连接到电脑。参考:互联网是如何工作的 - 学习 Web 开发 | MDN (mozilla.org)
How the Internet Works in 5 Minutes (youtube.com)
网页,网站,网络服务器和搜索引擎的区别是什么? - 学习 Web 开发 | MDN (mozilla.org)
什么是超链接? - 学习 Web 开发 | MDN (mozilla.org)

什么是URL?
一个 URL 由不同的部分组成,其中一些是必须的,而另一些是可选的。
http是协议。它表明了浏览器必须使用何种协议。它通常都是 HTTP 协议或是 HTTP 协议的安全版,即 HTTPS。Web 需要它们二者之一,但浏览器也知道如何处理其他协议,比如mailto:(打开邮件客户端)或者ftp:(处理文件传输)。
www.example.com是域名。它表明正在请求哪个 Web 服务器。或者,可以直接使用IP address,但是因为它不太方便,所以它不经常在网络上使用。
:80是端口。它表示用于访问 Web 服务器上的资源的技术“门”。如果 Web 服务器使用 HTTP 协议的标准端口(HTTP 为 80,HTTPS 为 443)来授予其资源的访问权限,则通常会被忽略。否则是强制性的。
/path/to/myfile.html是网络服务器上资源的路径。在 Web 的早期阶段,像这样的路径表示 Web 服务器上的物理文件位置。如今,它主要是由没有任何物理现实的 Web 服务器处理的抽象。
?key1=value1&key2=value2是提供给网络服务器的额外参数。这些参数是用&符号分隔的键/值对列表。在返回资源之前,Web 服务器可以使用这些参数来执行额外的操作。每个 Web 服务器都有自己关于参数的规则,唯一可靠的方式来知道特定 Web 服务器是否处理参数是通过询问 Web 服务器所有者。
#SomewhereInTheDocument是资源本身的另一部分的锚点。锚点表示资源中的一种“书签”,给浏览器显示位于该“加书签”位置的内容的方向。例如,在 HTML 文档上,浏览器将滚动到定义锚点的位置;在视频或音频文档上,浏览器将尝试转到锚代表的时间。值得注意的是,#后面的部分(也称为片段标识符)从来没有发送到请求的服务器。你可能想到一个 URL 类似普通信件的地址:协议代表你要使用的邮政服务,域名是城市或者城镇,端口则像邮政编码;路径代表着你的信件所有递送的大楼;参数则提供额外的信息,如大楼所在单元;最后,锚点表示信件的收件人。
什么是 URL? - 学习 Web 开发 | MDN (mozilla.org)

有了上面的基础我们就可以讨论下面的问题了。
输入URL到显示页面的全过程
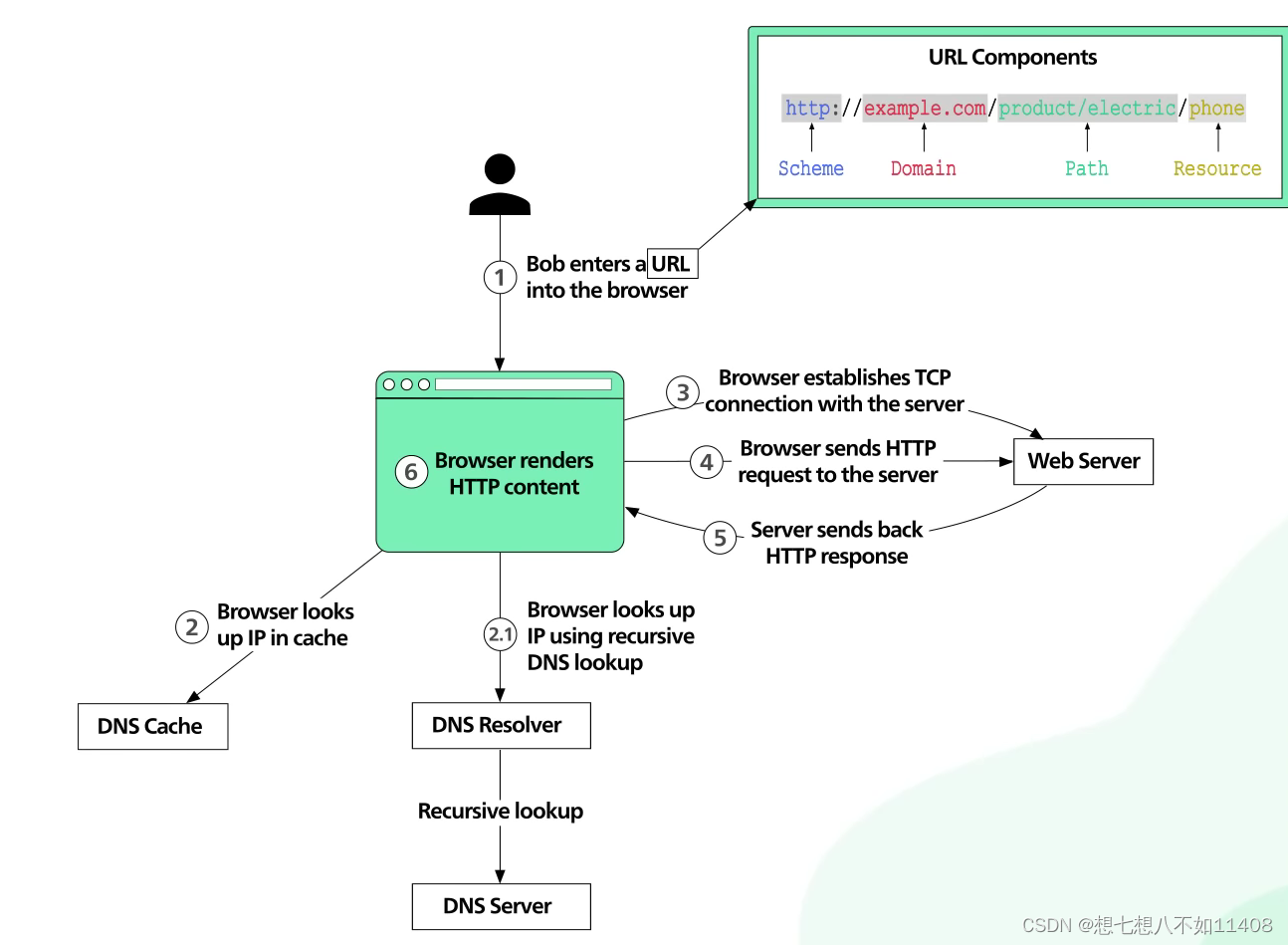
哇这个视频讲的巨好,千万不要错过。What happens when you type a URL into your browser? (youtube.com)
1. 在地址栏输入链接
2. 浏览器在缓存中找IP
2.1缓存中没有,就在域名服务器(DNS,Domain Name System)中递归查找
3. 浏览器和网站服务器建立TCP连接
4. 浏览器通过建立的TCP连接向网站服务器发送HTTP请求
5. 网站服务器发回HTTP响应
6. 浏览器接收响应并渲染HTML内容
一文彻底搞懂从输入URL到显示页面的全过程_浏览器输入url后发送的过程是先渲染还是先断开了tcp连接-CSDN博客

HTML文档
在大部分浏览器中使用Ctrl+U快捷键可以显示源代码。Example Domains (iana.org)


使用XPath选择HTML元素
XPath插件安装。最新版edge浏览器中安装xpath插件_edge浏览器调试xpath-CSDN博客
安装好之后输入快捷键 CTRL + ALT +X即可使用,
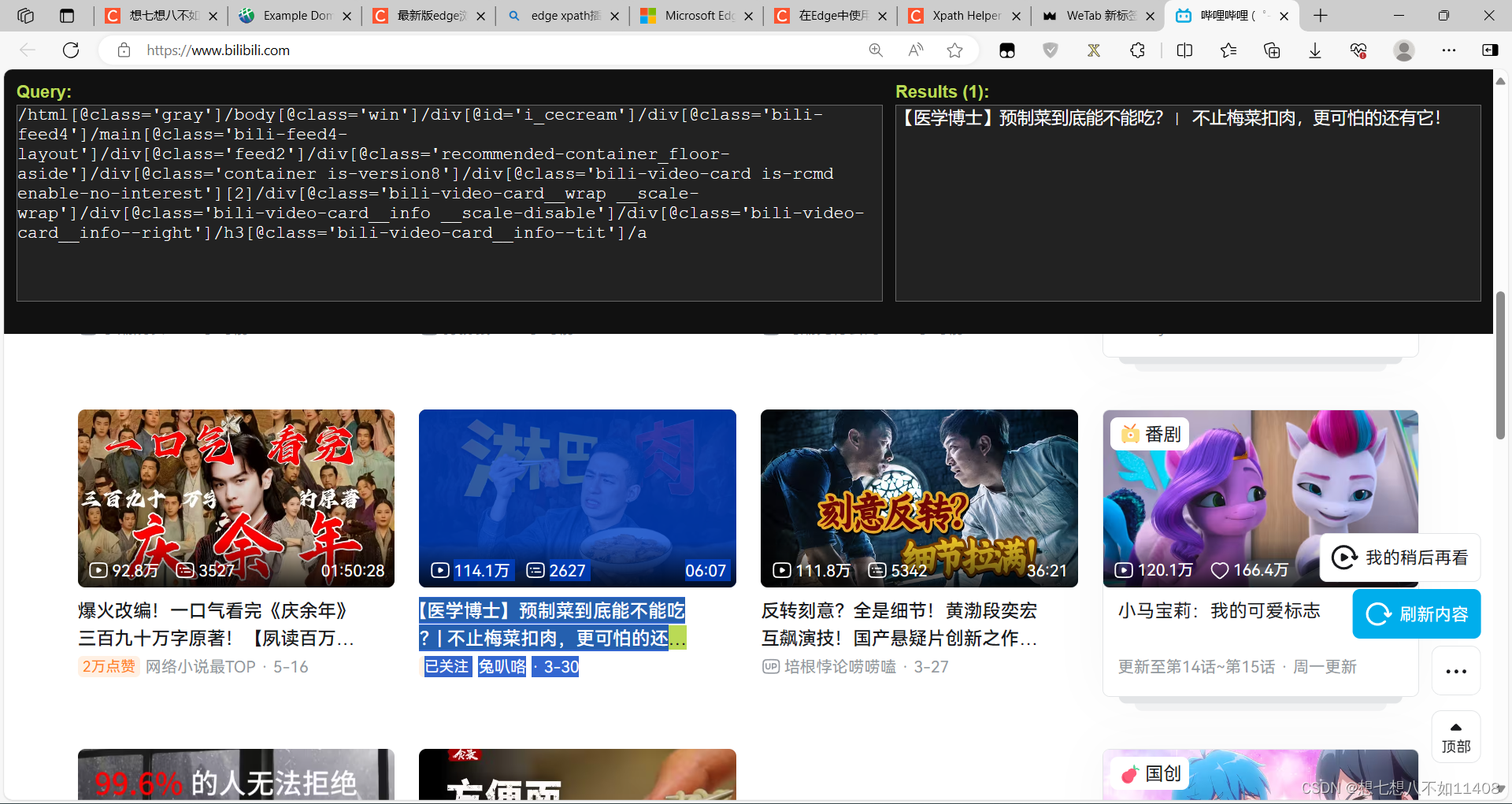
打开之后用鼠标选中,就是蓝色的这块区域,如何用CTRL+ALT即可选中。
这篇关于【Python】【Scrapy 爬虫】理解HTML和XPath的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




