本文主要是介绍弱监督语义分割-对CAM的生成过程进行改进3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
三、擦除图像高响应部分以获取更多的分割领域
ECS-Net: Improving Weakly Supervised Semantic Segmentation by Using Connections Between Class Activation Maps(ICCV,2021)
1.引言
我们首先从图像中擦除高响应区域,并生成这些擦除图像的新 CAM。然后,我们从新 CAM 中抽样可靠的像素,并将它们的分割预测作为语义标签应用于训练相应的原始 CAM。与多次擦除不同,我们的方法只需要进行一次擦除,避免引入过多的噪音。我们进行了大量的消融研究,以发现最佳的超参数,如抽样阈值。具体来说,我们可以实现以下目标:
- 为了解决弱监督语义分割中的问题,我们提出了一个简单、高效、新颖的框架:擦除CAM监督网(ECS-Net)。该方法利用目标区域挖掘技术和两次cam之间的关系,提供了额外的分割线索。实验表明,ECS-Net预测的CAMs能够更好地学习到物体的边界和形状等分割信息。
- 由于过度激活等噪声严重损害分割性能,我们的ECS-Net设计了采样规则来抑制从擦除图像的cam带来的噪声。实验结果表明,该方法有助于剔除不可靠样本,加快网络收敛速度。
- 在PASCAL VOC 2012数据集测试集上的实验表明,我们的框架在VGG-16主干网和ResNet-38主干网上的mIoU分别达到63.4%和67.6%,优于之前最先进的方法。
2.相关工作
细化和扩展类激活映射,以扩展整个对象:
- SEC[17]引入了三个损失函数,播种、扩展和约束损失来指导网络训练。然而,静态种子线索太少且稀疏,限制了分割性能。为了提高低响应目标区域的识别能力,
- AE[32]迭代地擦除输入图像中的高响应特征,迫使网络从低响应区域学习新的亮点特征。然而,迭代学习是费时的。
- MDC[34]采用高扩张率的扩张卷积对整个目标区域的特征进行采样和研究。由于采样位置固定,MDC难以灵活捕获目标边界。
- FickleNet[18]对此问题进行了研究,尝试利用不同掉落率的Dropout方法来随机选择和组合特征。FickleNet在一张图像上生成多个位置图,获得不同形状的区域。由于dropout的随机性较大,flicklenet不可避免地引入了噪声。
- PSA[2]生成亲和矩阵来研究像素之间的相似性,并应用随机游走来预测最终结果。
大多数方法无法抑制采样带来的过度激活,因为少量背景像素被错误分类,可能不会影响分类损失。为了突破这些限制,我们提出了ECS-Net。据我们所知,我们的方法可能是第一个在探索阶段引入可靠的伪分割监督的算法。
使用cam之间的连接:
- MDC[34]对不同扩张卷积预测的CAMs求和。
- 同样,RRM[37]计算不同尺度下CAM的平均值。
- AE[32]从每个cam中裁剪高亮片,并根据相应位置粘贴在一起。
- 我们认为过于简化的装配设计不能发挥不同CAMs的功能。
- SEAM[31]通过将图像大小调整为两个尺度来生成相应的cam。此外,它利用等变正则化来缩小这两个cam之间的差异。通过这种自监督学习方法,SEAM为分割任务生成了更加鲁棒的cam。
-
在一定程度上,小尺度图像的CAM激活了更多物体的部分,但加剧了过度激活。相反,大规模图像的CAM具有较少的激活区域,包括较少的过度激活。这两个cam相互监督,在扩展对象区域和过度激活之间提供了良好的平衡。然而,在SEAM中很难修正两种cam中相同的预测误差。
3.我们的方法
首先,我们详细阐述了应用cam生成片段监督的详尽过程。我们还介绍了抑制噪声标签的方法,并进一步讨论了我们的框架的实现,包括损失函数,网络结构,以及其他一些改进,如缩放和多扩展覆盖模块。整个框架如图2所示。最后,我们详尽地解释了算法的工作原理。

图1:空间维度标注的不足导致网络过于关注突出的目标区域,降低了对目标边缘的敏感性(左)。我们的方法使网络不会遗漏另一个有价值的区域,并且可以更好地捕获边缘(右)。
空间维度注释存在的问题是指在语义分割任务中,使用的注释信息缺乏对像素级别的空间位置信息。传统的图像级别标签或注释无法提供像素级别的对象位置信息,这导致网络在学习时可能过度关注显著的对象区域,而忽略了对象的边缘或细节部分。因此,缺乏空间维度注释会限制网络对对象结构的全面理解,可能导致分割结果缺乏准确性和细节。通过解决空间维度注释不足的问题,可以帮助网络更好地捕捉对象的边缘和细节信息,提高语义分割的性能。

- 将分类标签为L的图像I输入网络F,预测热图H
,
- C为对象类别
- 将H归一化得到原始CAM a,
- 分类权重W={
|
L,else
c
![]()
- 分数越高意味着分类特征越明显,我们设置阈值δ = 0.6从s中选择擦除区域R。
- 对选定区域的像素应用高斯模糊来擦除M上的这些特征。
- ECS-Net将处理后的图像I'发送到与F共享权重的网络F'中,并输出热图H'
- 根据式(1),得到擦除后图像a '的CAM。然后,通过argmax函数对a '进行处理,得到粗分割标签L '。
![]()

图2: 我们提议的ECS-Net的整个框架。F中cam的高响应区域在图像上被擦除。通过抑制噪声,F'中的CAMs被用作附加的分割标签。F和F'共享权重。
-
图2显示,通过擦除高响应特征(红色区域),我们的网络将注意力转移到其他低响应对象区域。到目前为止,我们制作的粗略标签包含大量的预测误差,远远低于要求
-
噪声抑制:我们遵循从L '中选择可靠分割标签的规则。首先,我们忽略来自擦除区域的标签。有两个原因:(1)这些区域,被认为是简单的例子,没有贡献。(2)由于擦除,这些区域遗漏了特征,导致预测不可靠。我们进一步忽略背景标签。最后,对分数图s '施加阈值θ,得到可靠标签。

- f(x)=exp(-x),o是GAP层预测的长度为C的向量,
- 我们的lcls忽略背景类别,即c = 0。

对于语义分割任务,我们采用交叉熵损失

- Q '表示伪分割标签L'的一个结果,Φ定义为可靠标签的位置集,P经过softmax操作后的CAM E在F中的结果,表示对CAM进行了一定的处理后得到的结果。
![]()
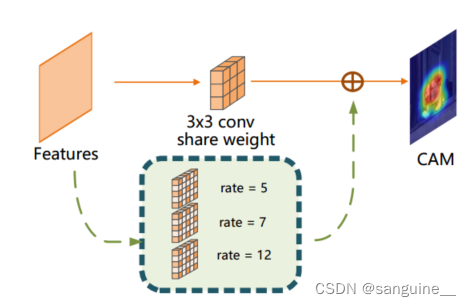
图3:在我们的方法中有多个扩展的覆盖模块。实线表示F中的CAM预测过程,虚线表示F '中擦除后的图像生成H '的过程。在多重膨胀叠加模块中,3×3卷积层与每个膨胀卷积层共享权重。
其他改进:我们还讨论了提高预测性能的其他改进。首先,在将图像送入F之前,我们用比例因子β∈[0,1]重新缩放原始图像M。这意味着我第一输入图像小于m .更具体地说,我第二输入图像的具有相同的形状与m .此外,出于这一事实扩张卷积层能够扩大接受域[8],我们添加K扩张卷积层在不同的rates与层B并联(如图3)。值得一提的是,这些额外的层与B和分享重量仅应用于F '在训练阶段。因此,我们的网络可能会捕捉到更多健壮的特征。热图H '的计算方法如下
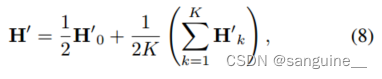
其中定义为B的输出,
定义为第k个扩张卷积层的输出。
这篇关于弱监督语义分割-对CAM的生成过程进行改进3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







