本文主要是介绍ColossalAI open-sora 1.0 项目技术报告 (视频生成),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目信息
- 项目地址:https://github.com/hpcaitech/Open-Sora
- 技术报告:
- Open-Sora 1:https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_01.md
- Open-Sora 1.1:https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
- 项目介绍:
- Open-Sora 是潞晨科技 (ColossalAI) 团队实现的一个致力于高效生产高质量视频的开源项目,旨在让所有人都能够访问先进的视频生成技术。该项目遵循开源原则,不仅使视频生成技术的访问民主化,还提供了一个简化和用户友好的平台,以简化视频制作的复杂性。Open-Sora 的目标是在内容创作领域激发创新、创造力和包容性。
- 目前发布了两个版本
- Open-Sora 1.0:生成 512x512 的 2s 视频
- Open-Sora 1.1:生成 2s~15s, 144p to 720p, any aspect ratio,支持 text-to-video, image-to-video, video-to-video, infinite time generation 等模式
Open-Sora 1.0 技术报告
效果展示
text prompt: A serene night scene in a forested area. […] The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop.

从生成的效果来看指令跟随能力一般,day to night 的效果一般
VAE 选择
- 为了降低计算成本,希望利用现有的 VAE 模型。Sora 使用空间-时间 (spatial-temporal) VAE 来减少时间维度。然而,我们发现没有开源的高质量空间-时间 VAE 模型。 MAGVIT 的 4x4x4 倍数下采样 VAE 没有开源,而 VideoGPT 的 2x4x4 VAE 在我们的实验中质量较低。因此,我们决定在我们第一个版本中使用 2D VAE(来自Stability-AI)。
attention
-
视频训练涉及大量的 token。考虑到 24 帧/秒的 1 分钟视频,我们有 1440 帧。通过 VAE 下采样 4 倍和补丁大小下采样 2 倍,我们有 1440x1024≈1.5M token。对 1.5M token 进行完全关注 (full attention) 将导致巨大的计算成本。因此,我们遵循 Latte 的方法使用空间-时间注意力 (spatial-temporal attention) 来降低成本。
-
如图所示,我们在 STDiT(ST 代表空间-时间)的每个空间注意力之后插入了一个时间注意力。这类似于 Latte 论文中的变体 3。然而,我们没有为这些变体控制类似数量的参数。尽管 Latte 的论文声称他们的变体比变体 3 更好,但我们在 16x256x256 视频上的实验表明,在相同数量的迭代下,性能排名为:DiT(完整)> STDiT(顺序)> STDiT(并行)≈ Latte。因此,出于效率考虑,我们选择了STDiT(顺序)。
- STDiT(顺序) 如下图所示,就是现在空间维度做 attention,然后再在时间维度上做 attention
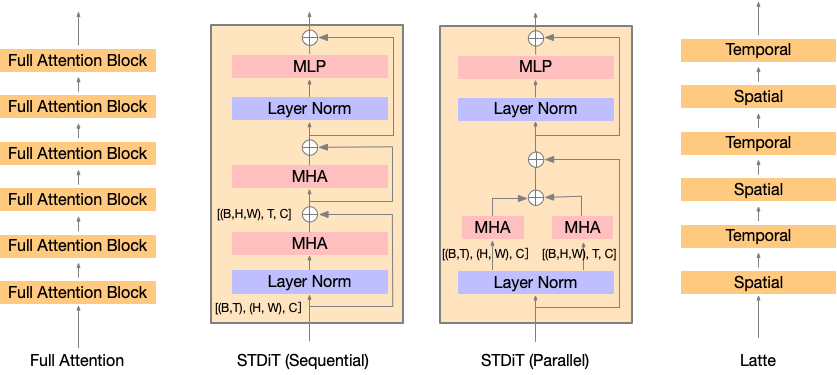
- STDiT(顺序) 如下图所示,就是现在空间维度做 attention,然后再在时间维度上做 attention
-
与直接在 DiT 上应用全注意力相比,随着帧数的增加,STDiT 更加高效。训练速度在应用加速技术后的8块H800 GPU上测量,GC 表示梯度检查点 (gradient checkpointing)。
| Model | Setting | Throughput (sample/s/GPU) | Throughput (tokens/s/GPU) |
|---|---|---|---|
| DiT | 16x256 (4k) | 7.20 | 29k |
| STDiT | 16x256 (4k) | 7.00 | 28k |
| DiT | 16x512 (16k) | 0.85 | 14k |
| STDiT | 16x512 (16k) | 1.45 | 23k |
| DiT (GC) | 64x512 (65k) | 0.08 | 5k |
| STDiT (GC) | 64x512 (65k) | 0.40 | 25k |
| STDiT (GC, sp=2) | 360x512 (370k) | 0.10 | 18k |
随着 Video-VAE 对时间维度进行4倍下采样,一个每秒 24 帧的视频有 450 帧。STDiT(每秒 28k 个token)在视频上与 DiT 在图像上的速度(最高每秒 45k 个token)之间的差距主要来自 T5 和 VAE 编码以及时间注意力。
图像模型初始化
- 为了专注于视频生成,我们希望基于一个强大的图像生成模型来训练模型。PixArt-α 是一个训练效率高、质量高的图像生成模型,具有 T5-conditioned 的 DiT 结构。我们用 PixArt-α 初始化我们的模型,并用零初始化插入的时间注意力的投影层。这种初始化在开始时保留了模型的图像生成能力,而 Latte 的架构则不能。插入的注意力将参数数量从 580M 增加到 724M。
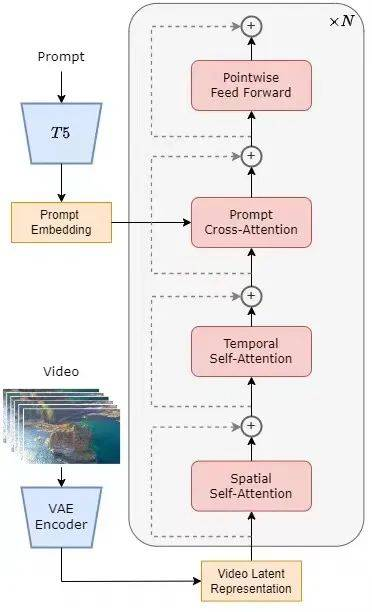
训练分辨率
借鉴 PixArt-α 和 Stable Video Diffusion 的成功,我们还采用了渐进式训练策略:在 366K 预训练数据集上进行 16x256x256 的训练,然后在 20K 数据集上进行 16x256x256、16x512x512 和 64x512x512 的训练。通过缩放位置嵌入,这种策略大大降低了计算成本。
时间下采样
我们还尝试在 DiT 中使用 3D 块嵌入器。然而,在时间维度上 2 倍下采样后,生成的视频质量较低。因此,我们将下采样留给我们下一版本的空间 VAE。目前,我们每 3 帧采样一次,进行 16 帧训练,每 2 帧采样一次,进行 64 帧训练。
数据是高质量的关键
我们发现,数据的数量和质量对生成视频的质量有很大的影响,甚至比模型架构和训练策略的影响还要大。目前,我们只准备了来自 HD-VG-130M 的第一批分割(366K视频片段)。这些视频的质量差异很大,而且 caption 也不够准确。因此,我们进一步从 Pexels 收集了 20k 相对高质量的视频, Pexels 提供免费许可的视频。我们使用 LLaVA(一个图像标题生成模型)对视频进行 caption 标注,使用三个帧和一个设计好的 prompt。通过设计好的 prompt,LLaVA可以生成高质量的标题。

训练细节
由于训练预算有限,我们只进行了一些探索。我们发现学习率 1e-4 过大,后来降低到 2e-5。当以大批量训练时,我们发现 fp16 比 bf16 不稳定,可能导致生成失败。因此,我们切换到 bf16 进行 64x512x512 的训练。对于其他超参数,我们遵循了之前的工作
- loss 降的似乎不太好
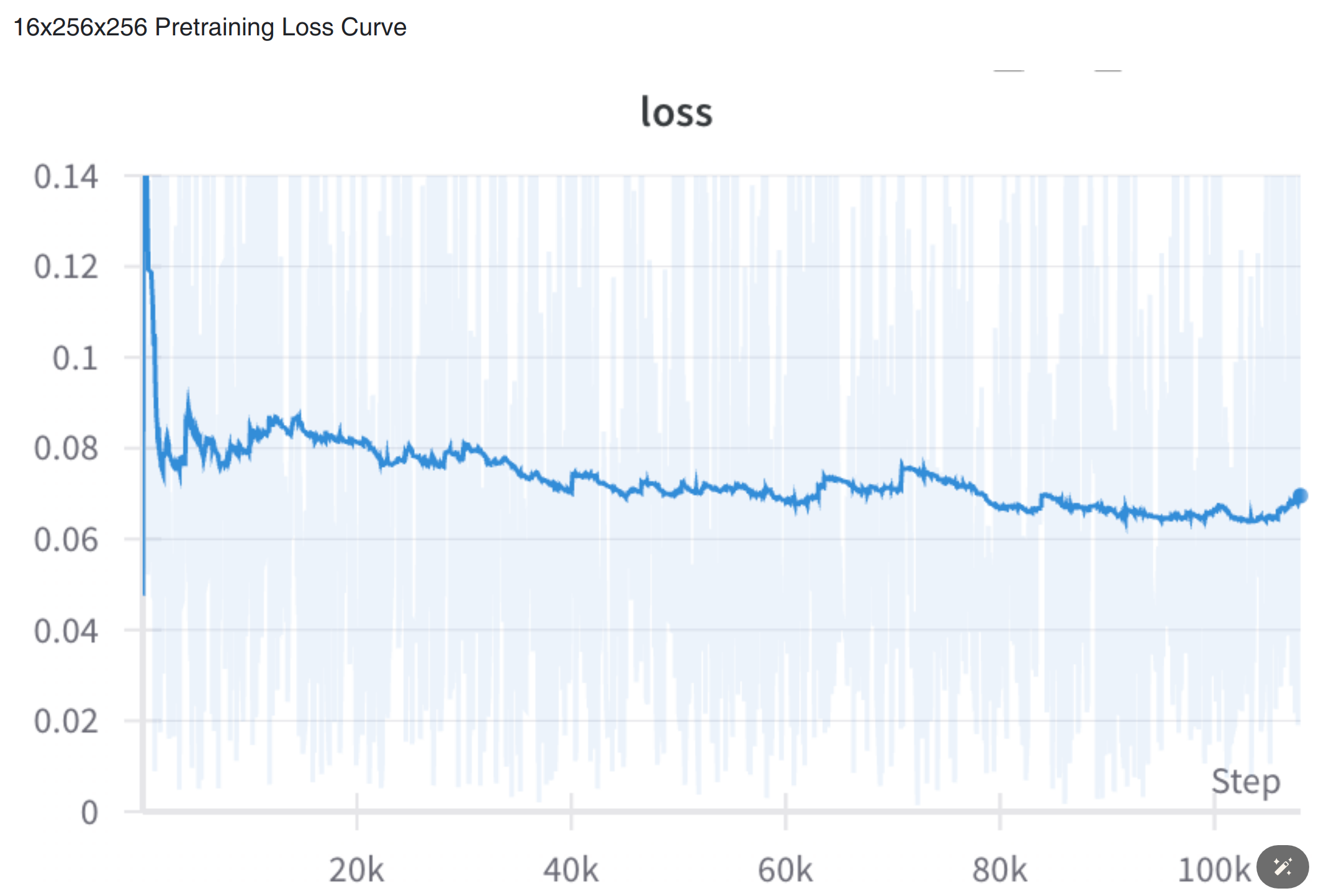
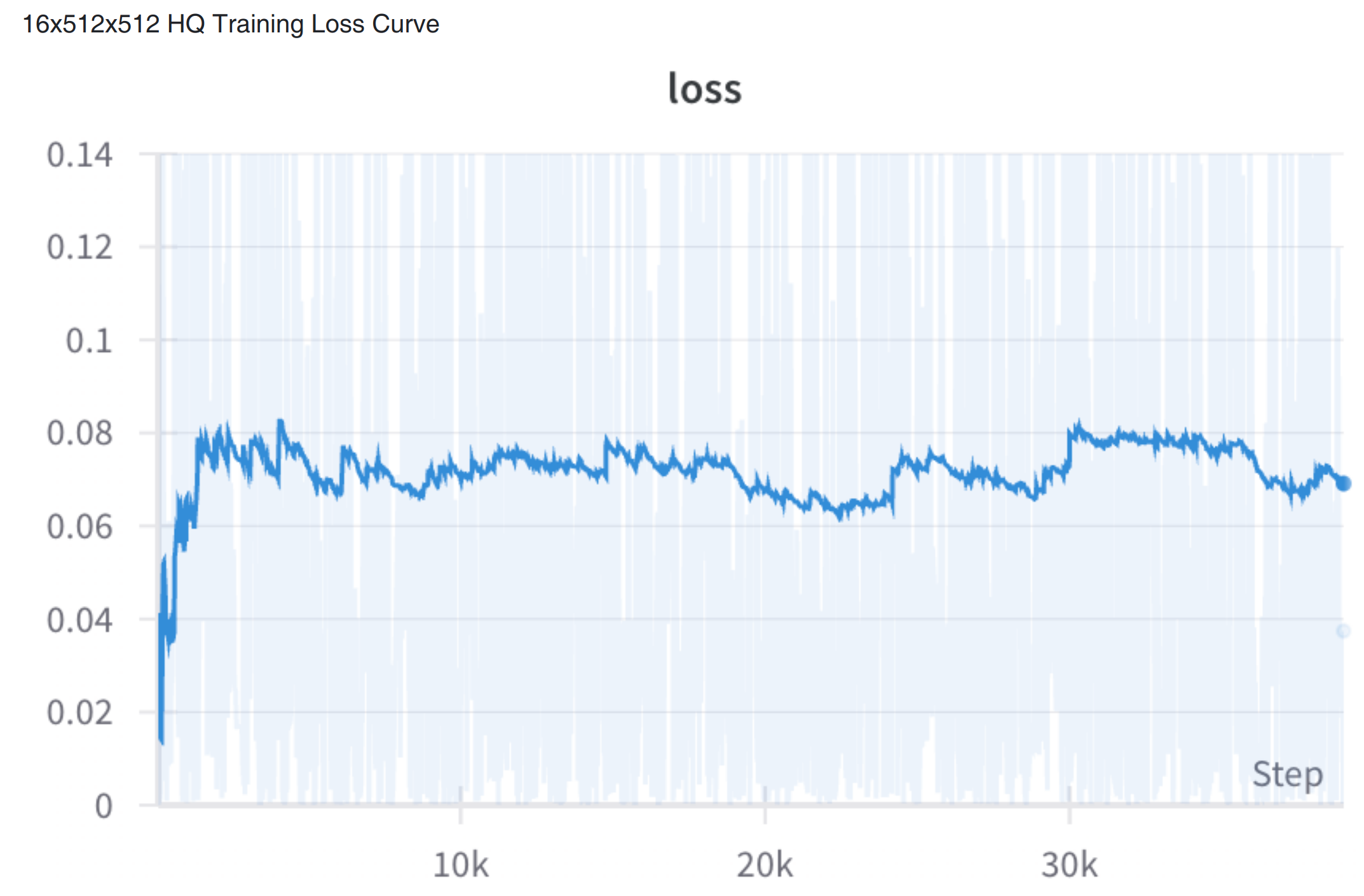
总结
- open sora 1.0 做到的效果和 sora 还有显著差距,不过其实通过借助开源的 SD VAE 工作等基本把整个视频生成的框架走通了,包括 STDiT、高质量数据生成等各个环节。后续对各个模块进一步更新可以实现更好的效果
这篇关于ColossalAI open-sora 1.0 项目技术报告 (视频生成)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






