本文主要是介绍2024年收集搜索引擎蜘蛛大全以及浏览器模拟蜘蛛方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于做SEOer来说经常和搜索引擎蜘蛛打交道,下面整理收集了最全的搜索引擎蜘蛛大全。供有需要的朋友使用,建议收藏。
搜索引擎蜘蛛大全
"TencentTraveler",
"Baiduspider+",
"BaiduGame",
"bingbot",//必应蜘蛛
"DotBot",
"DataForSeoBot",
"SemrushBot",
"Googlebot",//谷歌蜘蛛 很勤奋的蜘蛛
"Sosospider+",
"Sogou web spider",
"ia_archiver",
"Yahoo! Slurp",
"YoudaoBot",
"Yahoo Slurp",
"MSNBot",
"Java (Often spam bot)",
"BaiDuSpider",
"Voila",
"Yandex bot",
"BSpider",
"twiceler",
"Sogou Spider",
"Speedy Spider",
"Google AdSense",
"Heritrix",
"Python-urllib",
"Alexa (IA Archiver)",
"Ask",
"Exabot",
"Custo",
"OutfoxBot/YodaoBot",
"yacy",
"SurveyBot",
"legs",
"lwp-trivial",
"Nutch",
"StackRambler",
"The web archive (IA Archiver)",
"Perl tool",
"MJ12bot",
"Netcraft",
"MSIECrawler",
"WGet tools",
"larbin",
"Fish search",
"360Spider",//360蜘蛛 比较懒的蜘蛛
"YisouSpider",//神马蜘蛛UC浏览器默认搜索sm.cn的蜘蛛
"SogouSpider",//搜狗蜘蛛
"Bytespider",//今日头条旗下:高频抓取 被很多站长封禁后 有所改善
"AspiegelBot",//华为旗下Aspiegel公司 疯狂高频爬行无节制
"YoudaoBot",//有道蜘蛛
"MJ12bot",//英国SEO分析页面蜘蛛
"SemrushBot",//美国SEO综合分析网站的蜘蛛
"YandexBot",//俄罗斯搜索引擎
"Yahoo",//雅虎蜘蛛
浏览器模拟蜘蛛方法
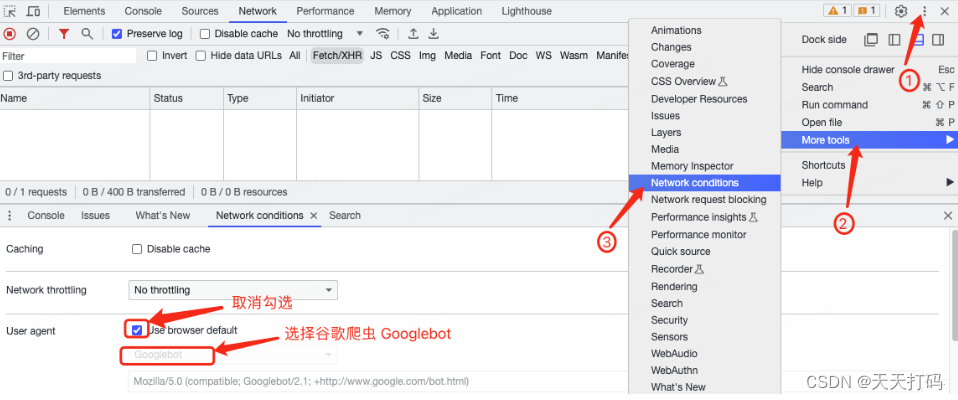
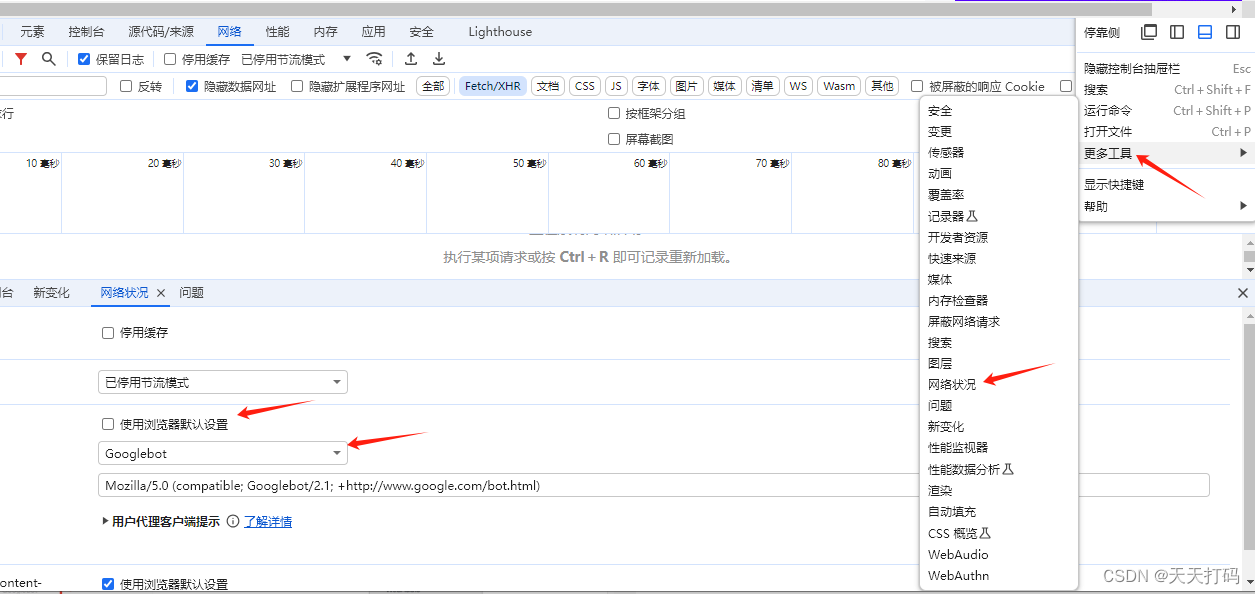
第一步:按压键盘上的F12键打开开发这工具,并点击右上角三个小黑点
第二步:选择More tools
第三步:选择Network conditions
第四步:找到User agent一列,取消复选框的勾选
第五步:选择谷歌爬虫agent即Googlebot
第六步:在当前浏览器地址栏中,输入想要访问的网站地址,直接访问。返回的页面就是爬虫看到的页面。
中文版浏:
Web浏览日志UA
PC搜索UA:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
移动搜索UA
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
PHP判断蜘蛛方法
/*** 判断是否是蛛蛛访问* @return bool|void*/
public function is_spider() {$agent= strtolower($_SERVER['HTTP_USER_AGENT']);if (!empty($agent)) {$spiderSite= array("TencentTraveler","Baiduspider+","BaiduGame","bingbot",//必应蜘蛛"DotBot","DataForSeoBot","SemrushBot","Googlebot",//谷歌蜘蛛 很勤奋的蜘蛛"Sosospider+","Sogou web spider","ia_archiver","Yahoo! Slurp","YoudaoBot","Yahoo Slurp","MSNBot","Java (Often spam bot)","BaiDuSpider","Voila","Yandex bot","BSpider","twiceler","Sogou Spider","Speedy Spider","Google AdSense","Heritrix","Python-urllib","Alexa (IA Archiver)","Ask","Exabot","Custo","OutfoxBot/YodaoBot","yacy","SurveyBot","legs","lwp-trivial","Nutch","StackRambler","The web archive (IA Archiver)","Perl tool","MJ12bot","Netcraft","MSIECrawler","WGet tools","larbin","Fish search","360Spider",//360蜘蛛 比较懒的蜘蛛"YisouSpider",//神马蜘蛛UC浏览器默认搜索sm.cn的蜘蛛"SogouSpider",//搜狗蜘蛛"Bytespider",//今日头条旗下:高频抓取 被很多站长封禁后 有所改善"AspiegelBot",//华为旗下Aspiegel公司 疯狂高频爬行无节制"YoudaoBot",//有道蜘蛛"MJ12bot",//英国SEO分析页面蜘蛛"SemrushBot",//美国SEO综合分析网站的蜘蛛"YandexBot",//俄罗斯搜索引擎"Yahoo",//雅虎蜘蛛);foreach($spiderSite as $val) {$str = strtolower($val);if (strpos($agent, $str) !== false) {return true;}}} else {return false;}
}
这篇关于2024年收集搜索引擎蜘蛛大全以及浏览器模拟蜘蛛方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





