本文主要是介绍kapacitor脚本tick针对bool类型的处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
stream类型的tick脚本
bool()函数
正确的做法
最终完整的tick脚本(batch)
telegraf采集k8s endpoint metric的时候会存一些bool类型的值到influxdb里面。
如判断endpoint是否ready,就是bool类型。

直接使用influxql查询是没问题的。
stream类型的tick脚本
pod_alert.tick
stream|from().measurement('kubernetes_endpoint').where(lambda: "namespace" == 'ctg')|window().period(10m).every(1s)|alert().id('stream pod not ready alerting').message('type: pod | {{ .Level}}: pod is not ready ').warn(lambda: "ready" == false).log('/root/pod_alerts.log').email('xxx@qq.com')kapacitor define pod_unready -type "stream" -dbrp "telegraf"."autogen" -tick pod_alert.tick 报错
invalid TICKscript: name "false" is undefined. Names in scope: time,streambool()函数
https://docs.influxdata.com/kapacitor/v1.5/tick/expr/#stateless-functions
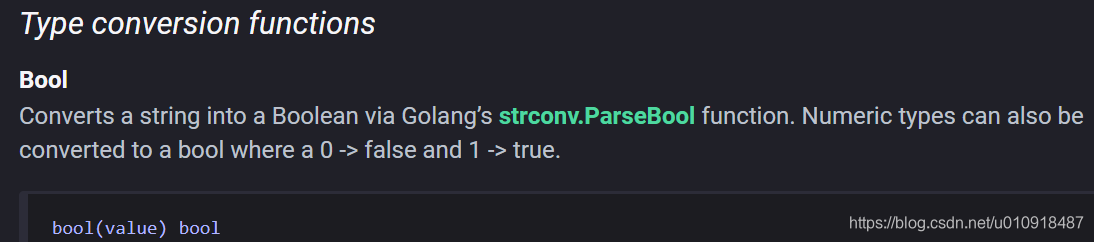
对于int类型:
bool(0) 对应false
bool(1) 对应true
对于string类型:
'0', 'f','F', 'false', 'FALSE','False', 对应false
'1', 't', 'T', 'true', 'TRUE', 'True' , 对应true
bool() 函数的参数如果是tring类型,只能是单引号,不可用双引号,否则报错 :
Cannot call function \"bool\" argument \"0\" is missing, values in scope are [\"ready\"]
后来把stream修改为了batch,生效了 。
正确的做法
把bool值使用bool()方法进行转换。
lambda: "ready" == bool(0) 或者lambda: "ready" == bool('0')
bool(value) bool
调用的是golang 的strconv.ParseBool()方法,源码如下:package strconv// ParseBool returns the boolean value represented by the string.
// It accepts 1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False.
// Any other value returns an error.
func ParseBool(str string) (bool, error) {switch str {case "1", "t", "T", "true", "TRUE", "True":return true, nilcase "0", "f", "F", "false", "FALSE", "False":return false, nil}return false, syntaxError("ParseBool", str)
}
最终完整的tick脚本(batch)
类型batch
batch|query('''SELECT * FROM "telegraf"."autogen"."kubernetes_endpoint" WHERE "namespace"='ctg' ''').period(1m).every(1s)|alert().message('{{ .Level}}:{{ index .Fields "pod"}} is unready, pls check.host: {{ index .Fields "host"}}, node name: {{ index .Fields "node_name"}}').warn(lambda: "ready" == bool('0')).log('/root/pod_alerts.log').email('xxx@qq.com')
这篇关于kapacitor脚本tick针对bool类型的处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



