score专题

856. Score of Parentheses
856. Score of Parentheses class Solution:def scoreOfParentheses(self, s: str) -> int:stack=[]i=0for c in s:if c=='(':stack.append(c)else:score=0while stack[-1]!='(':score+=stack.pop()stack.pop()score

Elasticsearch func_score
场景介绍 衰减函数 总结 官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/query-dsl-function-score-query.html 作者公众号: 1.场景介绍 在全文检索中,排序是一个很讲究的事。关键字命中,是全文检索中一个很关键的因素。然而,某些时候,我们关键字的命中可能非常低,或者来两个

Redis Zset 类型:Score 属性在数据排序中的作用
Zset 有序集合 一 . zset 的引入二 . 常见命令2.1 zadd、zrange2.2 zcard2.3 zcount2.4 zrevrange、zrangebyscore2.5 zpopmax、zpopmin2.6 bzpopmax、bzpopmin2.7 zrank、zrevrank2.8 zscore2.9 zrem、zremrangebyrank、zremrangebysc

机器学习三:cumulative match score
1.这是机器学习中knn算法的一个概念,没有找到中文资料,那么可以看这个: https://stats.stackexchange.com/questions/142323/cumulative-match-score 2.同时我读的论文中也有对其的解释: 3.这是一篇人脸识别的论文,人脸一共C=200个,那么knn最后会有个p*200的矩阵,p是想要知道的人脸,也就是测试,p

Noise Conditional Score Networks 简单总结
Noise Conditional Score Networks Score S c o r e = ∇ x l o g p ( x ) (1) Score = \nabla_xlog~{p(x)} \tag{1} Score=∇xlog p(x)(1) Score 是论文中的一个定义,表示概率密度 p ( x ) p(x) p(x)的梯度,沿着概率密度的梯度向前走,会走到概率密度最高的
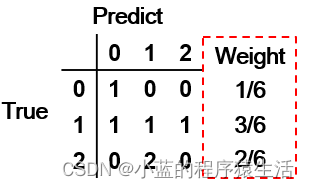
多分类问题中评价指标F1-Score 加权平均权重的计算方法
多分类问题中评价指标F1-Score 加权平均权重的计算方法 众所周知,F1分数(F1-score)是分类问题的一个衡量指标。在分类问题中,常常将F1-score作为评价分类结果好坏的指标。它是精确率和召回率的调和平均数,值域为[0,1]。 F 1 = 2 ∗ P ∗ R P + R F_1=2*\frac{P*R}{P+R} F1=2∗P+RP∗R 其中,P代表着准确率(

Elastic Search 搜索结果中 _score 字段为 null
参考了 使用elasticsearchTemplate.query()查询发现score字段为null 出现原因 搜索时使用了其他字段作为排序条件,ES 默认是使用 _score 作为排序条件的 解决方案 在 sort 里增加 _score 字段排序
Score Matching(得分匹配)
Score Matching(得分匹配)是一种统计学习方法,用于估计概率密度函数的梯度(即得分函数),而无需知道密度函数的归一化常数。这种方法由Hyvärinen在2005年提出,主要用于无监督学习,特别是在密度估计和生成模型中。 基本原理 在概率论中,得分函数(Score Function)是概率密度函数关于其参数的梯度。对于一个随机变量 x x x 的概率密度函数 p ( x ) p(
HDU2148 Score【水题】
Score Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submission(s): 4767 Accepted Submission(s): 3079 Problem Description 转眼又到了一年的年末,L
ElasticSearch中的Scirpt Score查询
文章目录 Script Score查询1.1 Painless简介1.2 在Script Score中使用Painless1.3 使用文档数据1.3.1 使用普通字段1.3.2 使用数组字段1.3.3 使用object类型的字段1.3.4 使用文档评分 1.4 向脚本传参1.5 在Script Score中使用函数1.5.1 saturation函数1.5.2 sigmoid函数1.5.3
Ethereum-Score-Hella怎么使用,举例说明
目录 Ethereum-Score-Hella怎么使用,举例说明 1. 环境准备 2. 使用 Ethereum-Score-Hella 3. 示例 注意事项 Node.js 和 npm是什么,举例说明作用 Node.js npm(Node Package Manager) windows系统怎么安装 Node.js 和 npm 一、安装Node.js 二、安装npm(npm是
东方博宜1565 - 成绩(score)
问题描述 牛牛最近学习了 C++ 入门课程,这门课程的总成绩计算方法是: 总成绩=作业成绩 ×20% + 小测成绩 ×30% + 期末考试成绩 ×50%。 牛牛想知道,这门课程自己最终能得到多少分。 输入 三个非负整数 A、B、C ,分别表示牛牛的作业成绩、小测成绩和期末考试成绩。 相邻两个数之间用一个空格隔开,三项成绩满分都是 100 分。 输出 一个整数,即牛牛这门课程的总成绩,满分
z score vs. min-max scaling 优缺点
Min-max:所有特征具有相同尺度 (scale) 但不能处理outlier z-score:与min-max相反,可以处理outlier, 但不能产生具有相同尺度的特征变换 More opinions (from researchgate): – If you have a PHYSICALLY NECESSARY MAXIMUM (like in the number of voters

python Z-score标准化
python Z-score标准化 Zscore标准化sklearn库实现Z-score标准化手动实现Z-score标准化 Zscore标准化 Z-score标准化(也称为标准差标准化)是一种常见的数据标准化方法,它将数据集中的每个特征的值转换为一个新的尺度,使得转化后的数据具有均值为0,标准差为1的分布。Z-score标准化公式如下: 其中: X 是原始数据值μ 是数据的均
**Leetcode 861. Score After Flipping Matrix
先写的状压,因为数据说只有<=20 然后挂了。。 贪心 class Solution {public:int matrixScore(vector<vector<int>>& A) {if (!A.size() || !A[0].size()) return 0;for (int i = 0; i < A.size(); i++) {if (!A[i][0]) {for (int j = 0
precision_score, recall_score, f1_score的计算
1 使用numpy计算true positives等 [python] view plain copy import numpy as np y_true = np.array([0, 1, 1, 0, 1, 0]) y_pred = np.array([1, 1, 1, 0, 0, 1]) # true positive TP = np.

Redis利用zset数据结构如何实现多字段排序,score的调整(finalScore = score*MAX_NAME_VALUE + getIntRepresentation(name) )
1、原文: 2、使用sql很容易实现多字段的排序功能,比如: select * from user order by score desc,name desc; 3、问题:用两个字段(score,name)排序。在redis中应该怎么做? 4、使用按分数排序的redis集合。你必须根据你的需要准备分数。 finalScore = score*MAX_NAME_VALUE +
流媒体服务器(20)—— mediasoup 之媒体流score评分计算(一)
目录 前言 正文 《流媒体服务器》专栏总览丨蓄力计划_开源流媒体服务器对比-CSDN博客 前言 mediasoup 有一套评估媒体传输通道优劣的机制,主要是通过 score 评分来判断的。今天就先介绍一下这个机制的大体逻辑,后面的文章再详细介绍具体计算的算法。 正文 mediasoup 的 score 评分机制需要依赖 rtcp 报文,那就从媒体服务收到报文开始讲起,在所有数据包
sklearn和torch计算的r2 score不一样
检查一下函数参数的位置,预测值和真实值位置不一样,可以参考函数定义 torch_r2score = torch_r2(pred, y) sklearn_r2score = r2_score(y, pred) https://pytorch.org/torcheval/main/generated/torcheval.metrics.functional.r2_score.html Parame

python计算precision@k、recall@k和f1_score@k
sklearn.metrics中的评估函数只能对同一样本的单个预测结果进行评估,如下所示: from sklearn.metrics import classification_reporty_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]y_pred = [0, 2, 4, 5, 2, 3, 1, 1, 4, 2]print(classification_repo
Beam Search score function
一般情况下,beam search 通常用于翻译等句子生成任务中。 beam_size 用来在翻译所所需时长和翻译准确度之间进行权衡。当beam_size = 1时,beam search 则退化为 greedy search。 另一方面,当 n_best 的取值大于1时,由 beam search 可以得到一个 approximate n-best list,而不是只输入一个最优值。 Hyp
![[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score](https://img-blog.csdnimg.cn/20210418025501926.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RyYW5jZTk1,size_16,color_FFFFFF,t_70)
[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score
准确率(Accuracy) = (TP + TN) / 总样本 =(40 + 10)/100 = 50%。 定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。 精确率(Precision) = TP / (TP + FP) = 40/60 = 66.67%。它表示:预测为正的样本中有多少是真正的正样本,它是针对我们预测结果而言的。Precision又称为查准率。 召回率

【NOI-题解】1320. 时钟旋转1323. 扩建花圃问题1462. 小明的游泳时间1565. 成绩(score)1345. 玫瑰花圃
文章目录 一、前言二、问题问题:1320. 时钟旋转问题:1323. 扩建花圃问题问题:1462. 小明的游泳时间问题:1565. 成绩(score)问题:1345. 玫瑰花圃 三、感谢 一、前言 本章节主要对基本运算中整数运算、小数运算题目进行讲解。包括《1320. 时钟旋转》《1323. 扩建花圃问题》《1462. 小明的游泳时间》《1565. 成绩(score)》《1345
H - High Score Gym - 101623H
题意: 给你a,b,c,d四个数,d可以分配到a,b,c中,结果为 a 2 + b 2 + c 2 + 7 ∗ m i n ( a , b , c ) a^2+b^2+c^2+7*min(a,b,c) a2+b2+c2+7∗min(a,b,c),要使得结果最大。 思路: 到了某个范围肯定全部分给一个数最优,这个范围之下就枚举每个数分配了多少。 这个范围设置为100就够了。 #include <
Accuracy准确率,Precision精确率,Recall召回率,F1 score
真正例和真反例是被正确预测的数据,假正例和假反例是被错误预测的数据。然后我们需要理解这四个值的具体含义: TP(True Positive):被正确预测的正例。即该数据的真实值为正例,预测值也为正例的情况; TN(True Negative):被正确预测的反例。即该数据的真实值为反例,预测值也为反例的情况; FP(False Positive):被错误预测的正例。即该数据的真实值为反例,但被错误预
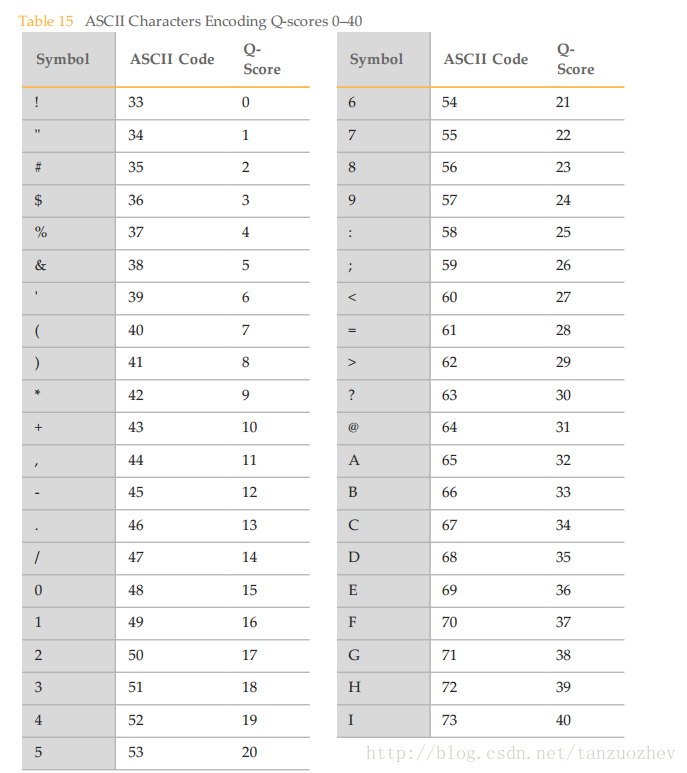
Illumina Fastq Q-score
Illumina Nextseq500 Miseq HiseqXten 测序仪 Q-score均采用下面的编码格式,仅作简要介绍。 Q-score Q-score 在fastq中每个序列的第4行,代表测序错误的概率。 Quality Score Q(X) ## Error Probability P(~X) Q40 ## 0.0001 (1 in 10,000) Q30 ## 0.0