hadoop1.2专题

fedora22下hadoop1.2.1wordcount测试
在配置好hadoop后进行第一个测试,如果没有配置可以看http://blog.csdn.net/u013372441/article/details/49849047内容 建立一个名为words的文件,内容如下h 然后使用start-all.sh正常启动之后输入下面的命令 hadoop dfs -mkdir input hadoop dfs -put /opt/words inp

Nutch1.8+Hadoop1.2+Solr4.3分布式集群配置
[b][color=green][size=large]Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。当然在百度百科上这种方法在Nutch1.2之后,已经不再适合这样描述Nutch了,因为在1.2版本之后,Nutch专注的只是爬取数据,而全文检索的部分彻底的交给Lucene和Solr,ES来做了,当然因为他们都是近亲关系,所
hadoop1.2.1运行wordcount报错
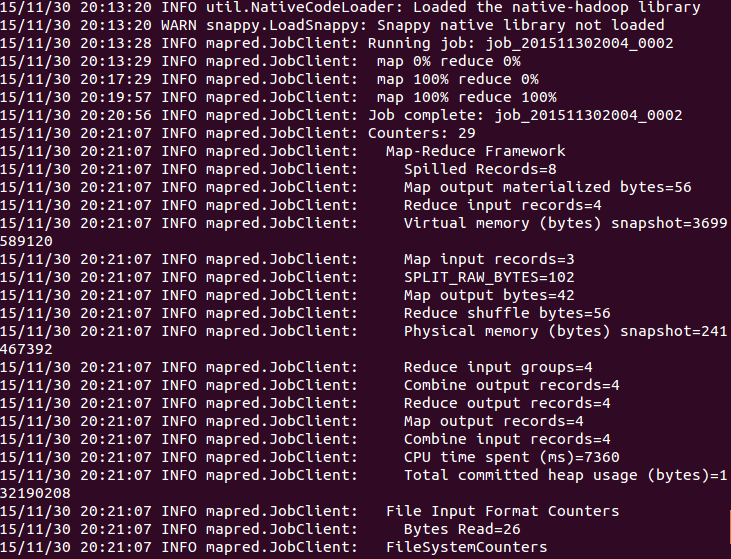
安装步骤参见http://www.tuicool.com/articles/NBvMv2 根据上述网站中的步骤安装好hadoop1.2.1,安装过程中一定要细心,文件位置不要随意放。 我就是文件位置设置同上述网站不一样,导致后续执行wordcount不成功,放出日志如下: Meta VERSION=”1” . Job JOBID=”job_201511301937_0004” JOBNA

在Hadoop1.2.1分布式集群环境下安装hive0.12
● 前言: 1. 大家最好通读一遍过后,在理解的基础上再按照步骤搭建。 2. 之前写过两篇<<在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境>>、《在Hadoop1.2.1分布式集群环境下安装Mahout0.9框架》都是Hadoop家族一系列的,后续还会有其它内容,敬请期待! 3. 好记性不如烂笔头,最新突然想把自己学习的东西整理出来,然而我也是刚刚学习,而且
编译hadoop1.2.1 eclipse插件
目录说明 在编译之前,我们需要先下载后Hadoop 1.2.1的源码文件,并解压到合适的位置。在此我是把hadoop直接放到D盘根目录,另外由于在编译的工程中需要知道eclipse的路径,所以首先计划目录结构如下如下: Eclipse: D:\DTools\eclipse Hadoop: D:\hadoop-1.2.1 Step1 导入 Had