130b专题

GLM-130B本地部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍GLM-130B本地部署的实战方案,希望对学习大语言模型的同学们有所帮
【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
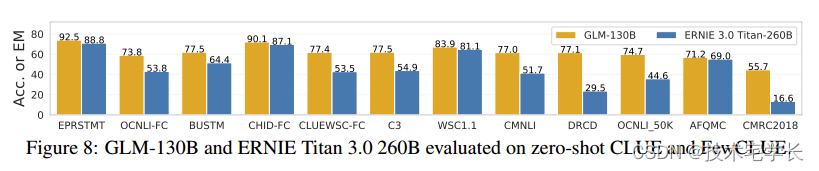
Glm-130b:开放式双语预训练模型 摘要 我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中,我们面临着许多意想不到的技术和工程挑战,特别是在损失峰值和分歧方面。在本文中,我们介绍了GLM-130B的训练过程,包括它
【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
Glm-130b:开放式双语预训练模型 摘要 我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中,我们面临着许多意想不到的技术和工程挑战,特别是在损失峰值和分歧方面。在本文中,我们介绍了GLM-130B的训练过程,包括它
番外02.GLM-130B
文章目录 前言泛读相关知识GPTBERTT5小结 背景介绍主要贡献和创新点GLM 6B 精读自定义Mask模型量化1TB 的中英双语指令微调RLHFPEFT训练策略 实验分析与讨论模型参数六个指标其他测评结果 代码复现(6B)环境准备运行调用代码调用网页服务命令行调用 模型微调 前言 首发公众号:学姐带你学AI 本课程来自深度之眼《大模型——前沿论文带读训练营》公开课,部分截