本文主要是介绍ChuanhuChatGPT集成百川大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
搭建步骤:
- 拷贝本地模型,把下载好的Baichuan2-7B-Chat拷贝到models目录下
-
修改modules\models\base_model.py文件,class ModelType增加Baichuan
Baichuan=16elif"baichuan"inmodel_name_lower:model_type=ModelType.Baichuan -
修改modules\models\models.py文件,get_model方法增加ModelType.Baichuan
elifmodel_type==ModelType.Baichuan:from.BaichuanimportBaichuan_Clientmodel=Baichuan_Client(model_name, user_name=user_name) -
增加modules\models\Baichuan.py文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
frommodelscopeimportsnapshot_download, AutoModelForCausalLM, AutoTokenizer,GenerationConfigfromtransformersimportAutoModelForCausalLM, AutoTokenizerfromtransformers.generationimportGenerationConfigimportloggingimportcoloramafrom..index_funcimport*from..presetsimport*from..utilsimport*from.base_modelimportBaseLLMModelfrom..presetsimportMODEL_METADATAfromdatetimeimportdatetimeclassBaichuan_Client(BaseLLMModel):def__init__(self, model_name, user_name="")->None:super().__init__(model_name=model_name, user=user_name)importtorchfromtransformersimportAutoModel, AutoTokenizerglobalCHATGLM_TOKENIZER, CHATGLM_MODELprint("__init__ Baichuan_Client")ifCHATGLM_TOKENIZERisNoneorCHATGLM_MODELisNone:model_path=Noneifos.path.exists("models"):model_dirs=os.listdir("models")ifmodel_nameinmodel_dirs:model_path=f"models/{model_name}"ifmodel_pathisnotNone:model_source=model_pathelse:model_source=snapshot_download(f"baichuan-inc/{model_name}", revision='v1.0.4')CHATGLM_TOKENIZER=AutoTokenizer.from_pretrained(model_source, device_map="auto", trust_remote_code=True, torch_dtype=torch.float16)quantified=Falseif"int4"inmodel_name:quantified=Truemodel=AutoModelForCausalLM.from_pretrained(model_source, device_map="auto", trust_remote_code=True, torch_dtype=torch.float16)model.generation_config=GenerationConfig.from_pretrained(model_source)model=model.eval()CHATGLM_MODEL=modeldef_get_glm_style_input(self):print("_get_glm_style_input")print(f"the history is: {self.history}")history=[x["content"]forxinself.history]query=history.pop()print(f"the message is: {query}")returnhistory, querydefget_answer_at_once(self):print("get_answer_at_once")history,query=self._get_glm_style_input()messages=[]messages.append({'role':'user','content': query})now=datetime.now()print("get_answer_at_once start"+"++++++++"+now.strftime("%Y-%m-%d %H:%M:%S"))response=CHATGLM_MODEL.chat(CHATGLM_TOKENIZER, messages)now=datetime.now()print("get_answer_at_once end"+"++++++++"+now.strftime("%Y-%m-%d %H:%M:%S"))print(f"the response is: {response}")returnresponse,len(response)defget_answer_stream_iter(self):history,query=self._get_glm_style_input()messages=[]messages.append({'role':'user','content': query})result=""now=datetime.now()print("get_answer_stream_iter start"+"++++++++"+now.strftime("%Y-%m-%d %H:%M:%S"))forresponseinCHATGLM_MODEL.chat(CHATGLM_TOKENIZER,messages):print(f"the response is: {response}")result+=responseyieldresultnow=datetime.now()print("get_answer_stream_iter end"+"++++++++"+now.strftime("%Y-%m-%d %H:%M:%S")) - 答案回调开关控制get_answer_at_once、get_answer_stream_iter方法调用选择
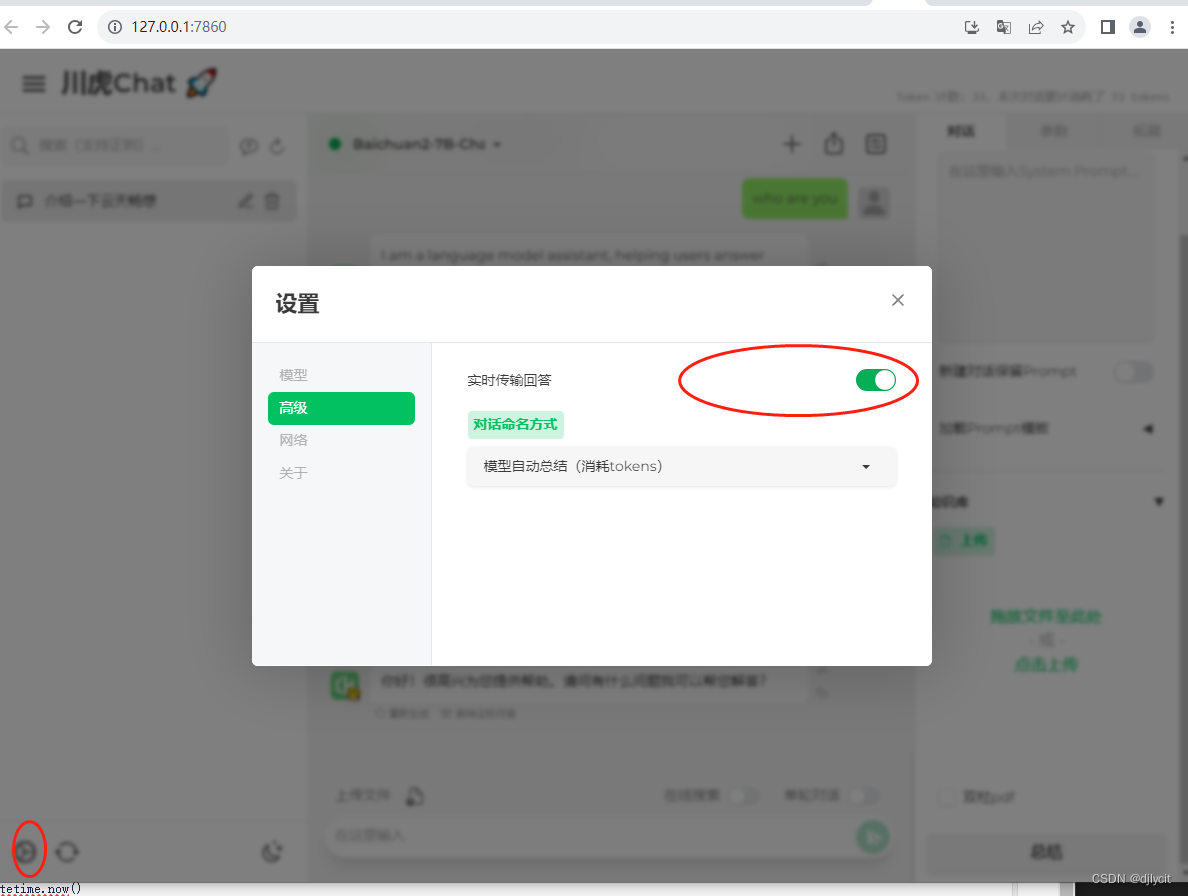
- 执行效果
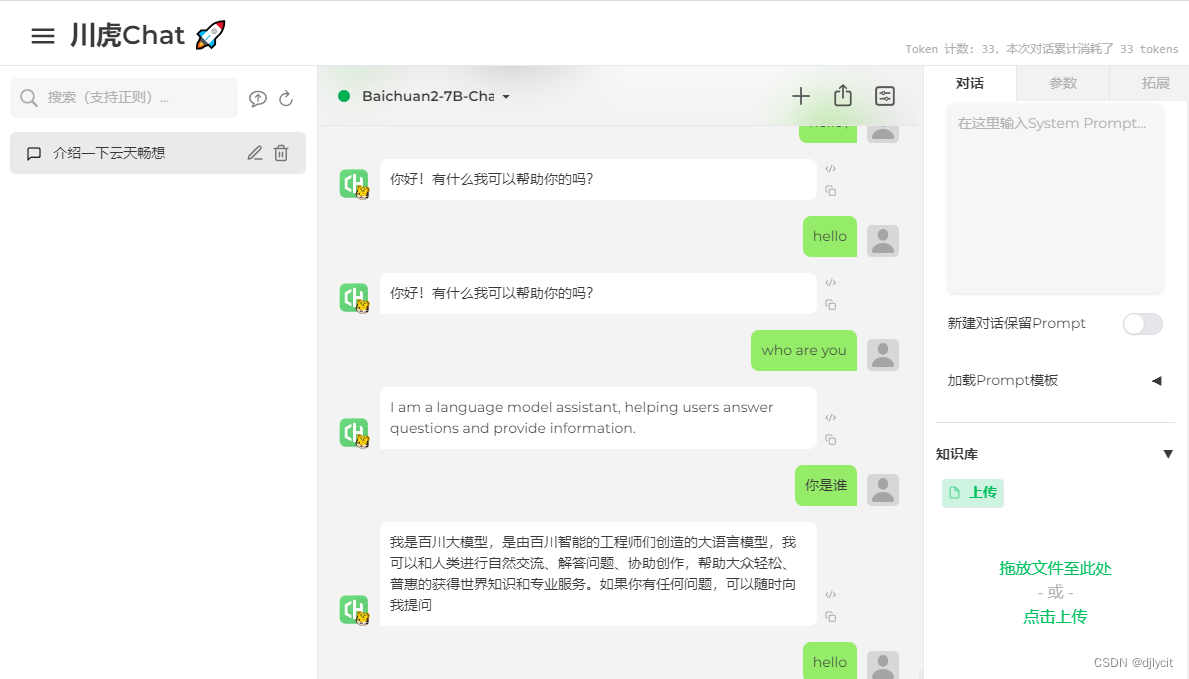
这篇关于ChuanhuChatGPT集成百川大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!