爬取专题

谈资是你的敲门砖之一!差评引发下跪的底层逻辑!——早读(逆天打工人爬取热门微信文章解读)
谈资对于我们很重要 引言Python 代码第一篇 洞见 武汉女导游雨中下跪磕头事件:动辄打差评的人,真的很坏第二篇 【冯站长之家】三分钟新闻早餐结尾 话题的深度是思考的催化剂 亦是人际关系的纽带 深度话题的引入 自然而然地激发思考 悄然拉近心灵的距离 促进人际间的紧密联系 引言 后面会开一档夜话 谈的是今天的所见所闻 当然作为三分之一个死宅 是不可能会有自己亲身体
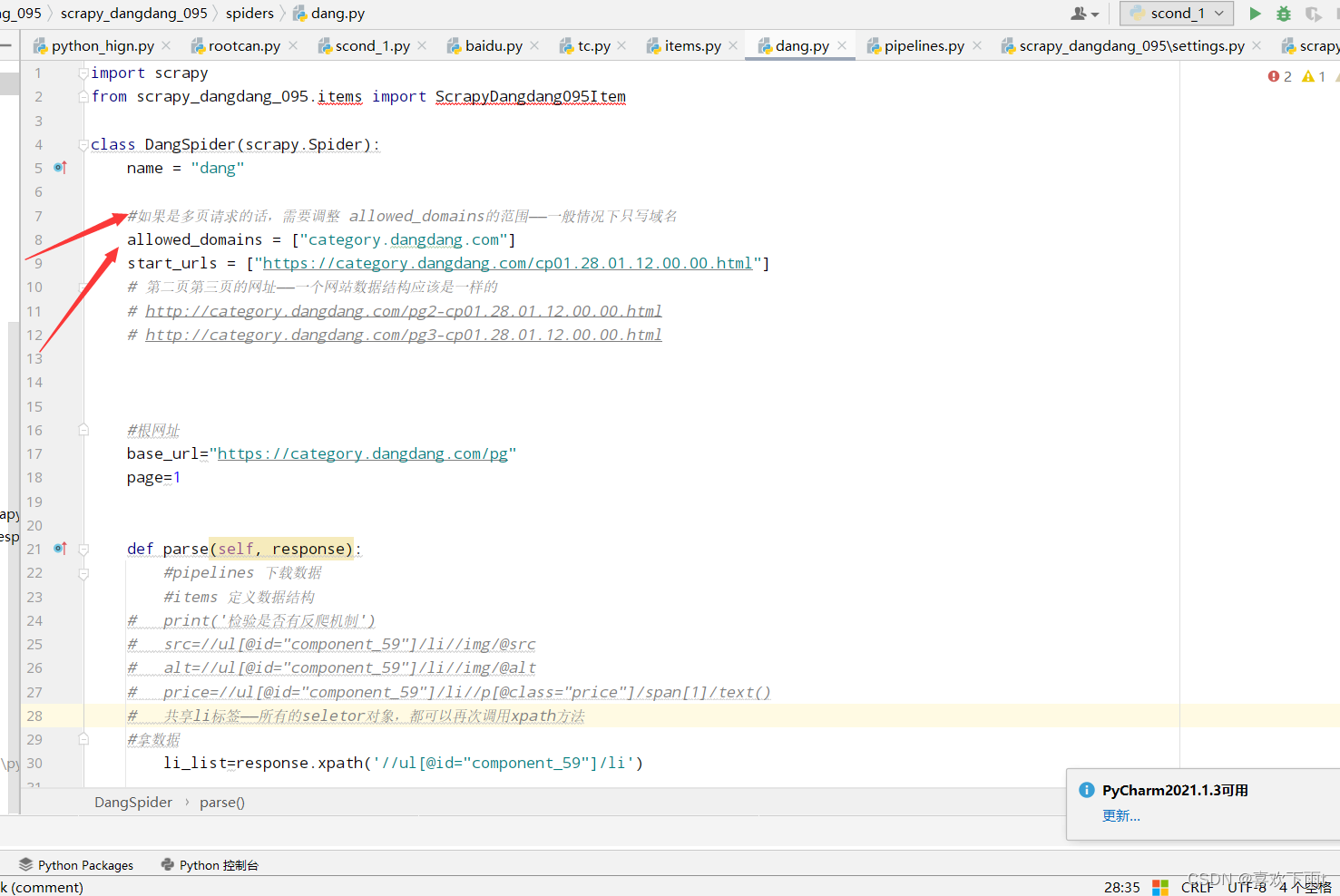
【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】
爬虫之scrapy框架——基本原理和步骤+爬取当当网(基本步骤) 下载scrapy框架创建项目(项目文件夹不能使用数字开头,不能包含汉字)创建爬虫文件(1)第一步:先进入到spiders文件中(进入相应的位置)(2)第二步:创建爬虫文件(3)第三步:查看创建的项目文件——检查路径是否正确 运行爬虫代码查看robots协议——是否有反爬取机制——君子协议(修改君子协议)(1)查看某网站的君子
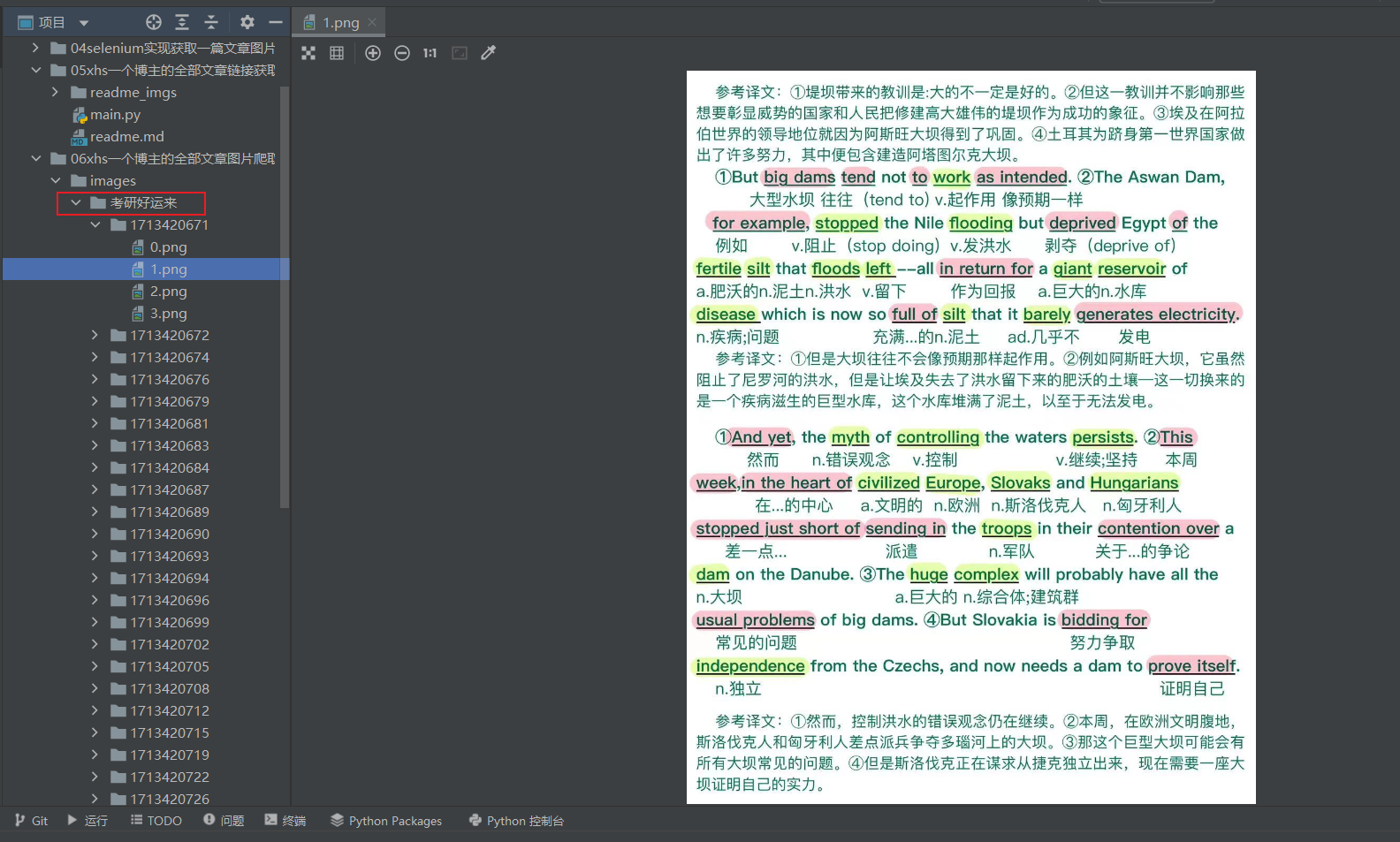
selenium进行xhs图片爬虫:06xhs一个博主的全部文章图片爬取
📚博客主页:knighthood2001 ✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下) 🎃知识星球:【认知up吧|成长|副业】介绍 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️ 🙏笔者水平有限,欢迎各位大佬指点,相互学习进步! 保存文章url 本来我想这把实现爬取一个博主的全部文章图片爬取放在一个py文件中,后来想想还是

代码-功能-Python-运用bs4技术爬取汽车之家新闻信息
第三方库安装指令: pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simplepip install BeautifulSoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 运行代码: #这个代码并不完整,有很大的问题,但目前不知道怎么改,就先这样吧!import r
猪都能胜任某些高管!梦会反映一个人的过去!——早读(逆天打工人爬取热门微信文章解读)
吓醒了,没尿出来 引言Python 代码第一篇 九边 有些高管确实连猪都能胜任第二篇 人民日报 新闻早班车要闻社会政策 结尾 习惯乃心灵之舵 引领人生航向深邃之境 在梦与现实的交叠幻象中 我顿悟了习惯铸就的意志堡垒 引言 神奇 小时候尿床和长大后尿床 做了一个梦 好急 好想找个厕所 好不容易在教学楼找了一个厕所 刚要尿 发现好脏 人好多 所以就出来了 匆匆忙忙
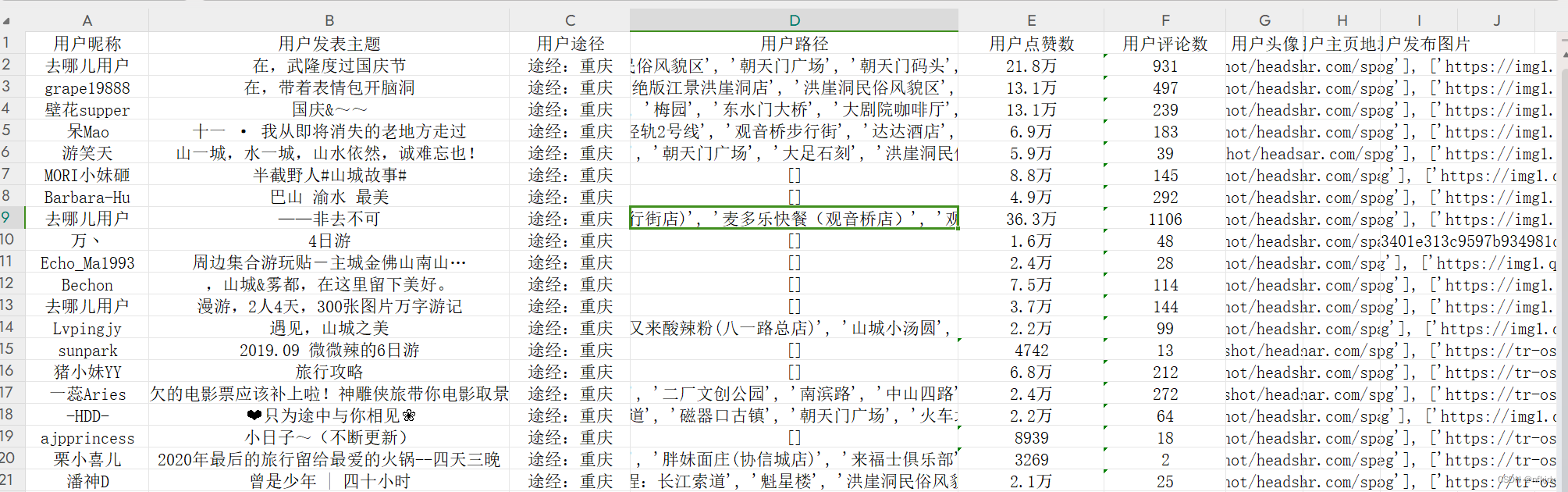
Python爬虫实战:爬取【某旅游交通出行类网站中国内热门景点】的评论数据,使用Re、BeautifulSoup与Xpath三种方式解析数据,代码完整
一、分析爬取网页: 1、网址 https://travel.qunar.com/ 2、 打开网站,找到要爬取的网页 https://travel.qunar.com/p-cs299979-chongqing 进来之后,找到评论界面,如下所示:在这里我选择驴友点评数据爬取 点击【驴友点评】,进入最终爬取的网址:https://travel.qunar.com/p-cs299

selenium爬取TapTap评论
上一篇写的beautifulsoup和request爬取出的结果有误。首先,TapTap网页以JS格式解析,且评论并没有“下一页”,而是每次加载到底部就要进行等待重新加载。我们需要做的,是模仿浏览器的行为,所以这里我们用Selenium的方式爬取。 下载ChromeDriver ChromeDriver作用是给Pyhton提供一个模拟浏览器,让Python能够运行一个模拟的浏览器进行网页访问
python爬取sci论文等一系列网站---通用教程超详细教程
环境准备 确保安装了Python以及requests和BeautifulSoup库。 pip install requests beautifulsoup4 确定爬取目标 选择一个含有SCI论文的网站,了解该网站的内容布局和数据结构。 (1)在浏览器中访问目标网站,右键点击页面并选择“检查”或使用快捷键(如Chrome浏览器的Ctrl+Shift+I)打开开发者工具。 (2)在“

C#爬虫爬取某东商品信息
🏆作者:科技、互联网行业优质创作者 🏆专注领域:.Net技术、软件架构、人工智能、数字化转型、DeveloperSharp、微服务、工业互联网、智能制造 🏆欢迎关注我(Net数字智慧化基地),里面有很多高价值技术文章,是你刻苦努力也积累不到的经验,能助你快速成长。升职+涨薪!! 在一个小项目中,需要用到京东的所有商品ID,因此就用c#写了个简单的爬虫。 在解析HTML中没有使用
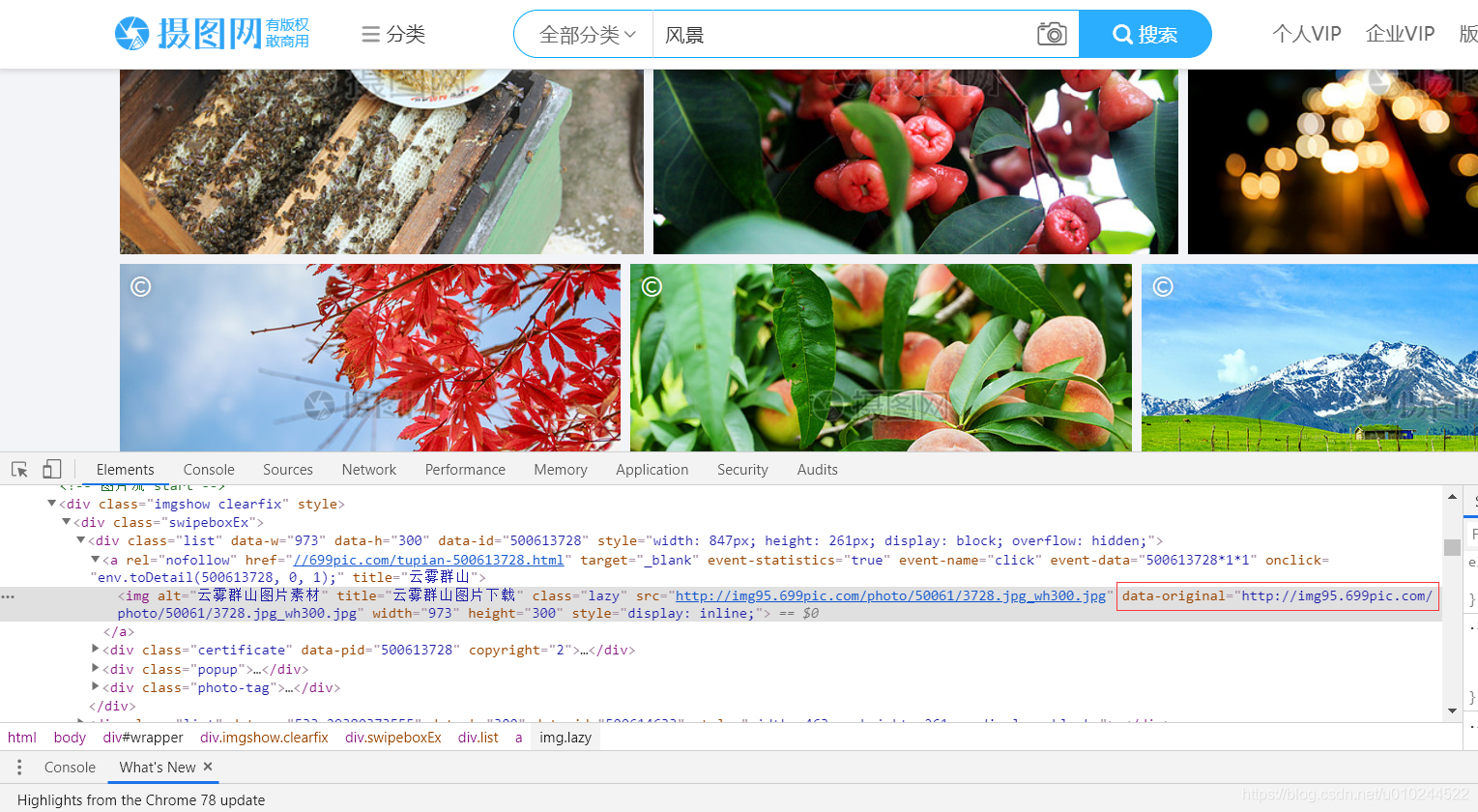
request+BeautifulSoup爬取网站内容
目标网站:http://699pic.com/sousuo-218808-13-1-0-0-0.html 如图,目标图片对于tag名为''img'',class=''lazy'' 查找时使用 find_all('img',class_='lazy') # conding :utf-8from bs4 import BeautifulSoupimport requestsurl
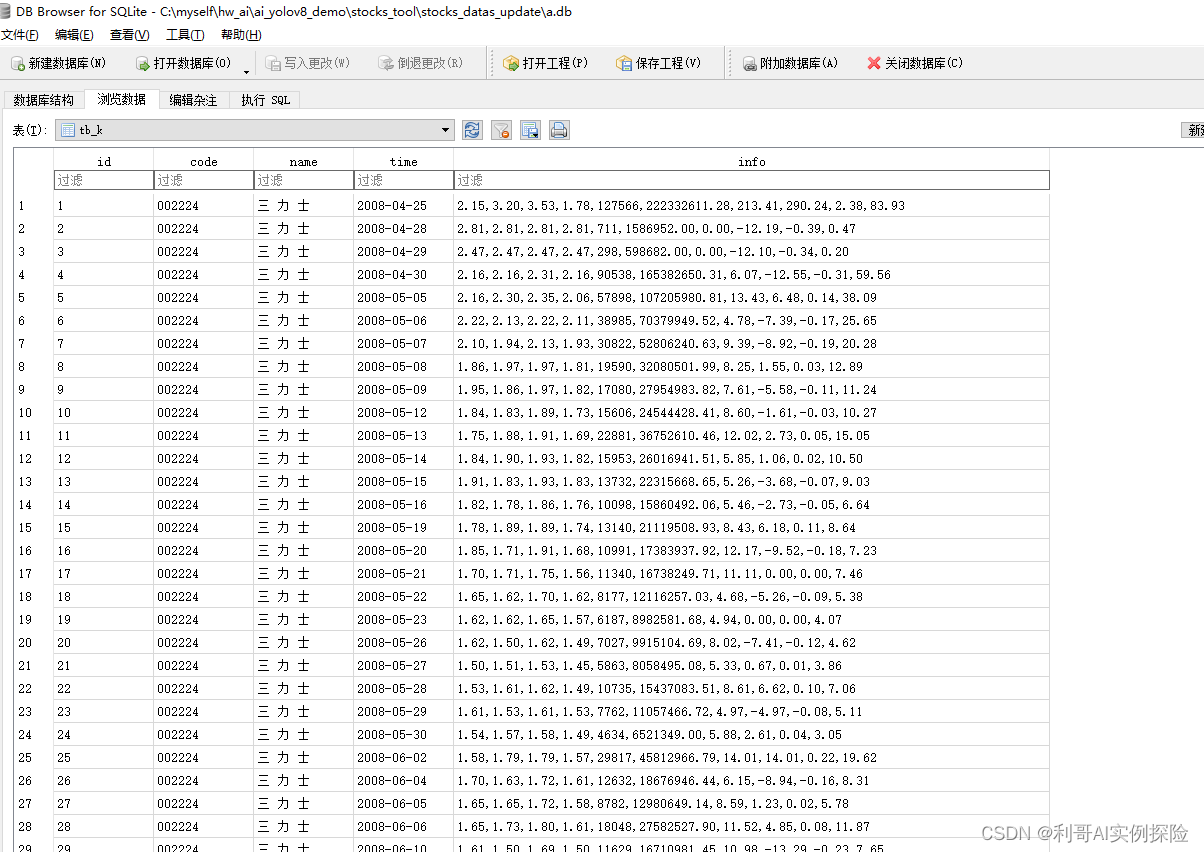
【爬虫】爬取股票历史K线数据写入数据库(三)
前几天有写过两篇: 【爬虫】爬取A股数据写入数据库(二) 【爬虫】爬取A股数据写入数据库(一) 现在继续完善,分析及爬取股票的历史K线数据通过ORM形式批量写入数据库。 2024/05,本文主要内容如下: 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。将爬取的数据写入通过 sqlalchemy ORM
爬虫爬取必应和百度搜索界面的图片
爬虫爬取必应和百度搜索界面的图片 爬取bing搜索图片界面爬取百度搜索界面图片结果如下 爬取bing搜索图片界面 浏览器驱动下载地址 对应版本即可 浏览器驱动 mad直接用 import osimport refrom selenium import webdriverfrom selenium.webdriver import Keysfrom seleni
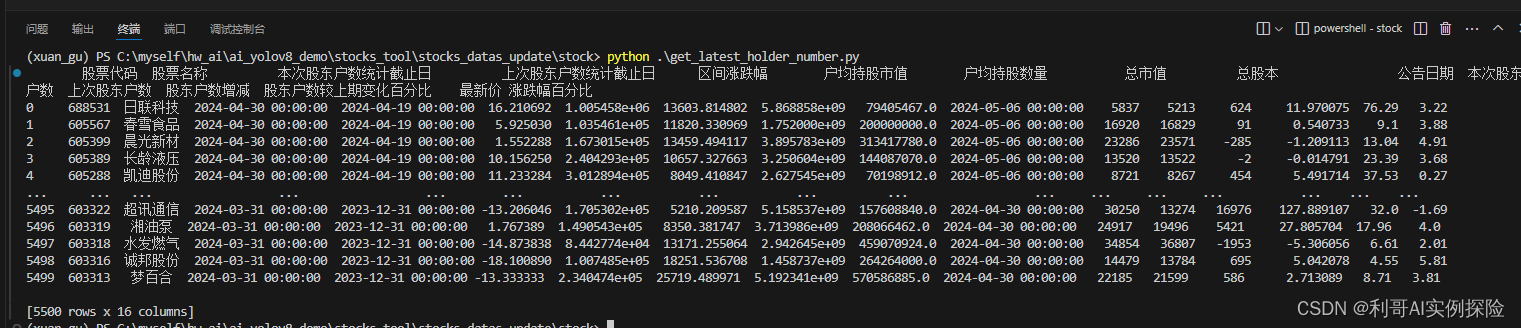
【爬虫】爬取A股数据写入数据库(一)
1. 对东方财富官网的分析 步骤: 通过刷新网页,点击等操作,我们发现https://datacenter-web.eastmoney.com/api/data/v1/get?请求后面带着一些参数即可以获取到相应数据。我们使用python来模拟这个请求即可。 我们以如下选择的页面为切入点,以此获取当前所有A股的一些基本数据。 通过F12调出浏览器调试框,对该网站的数据拉取协议为参考,然
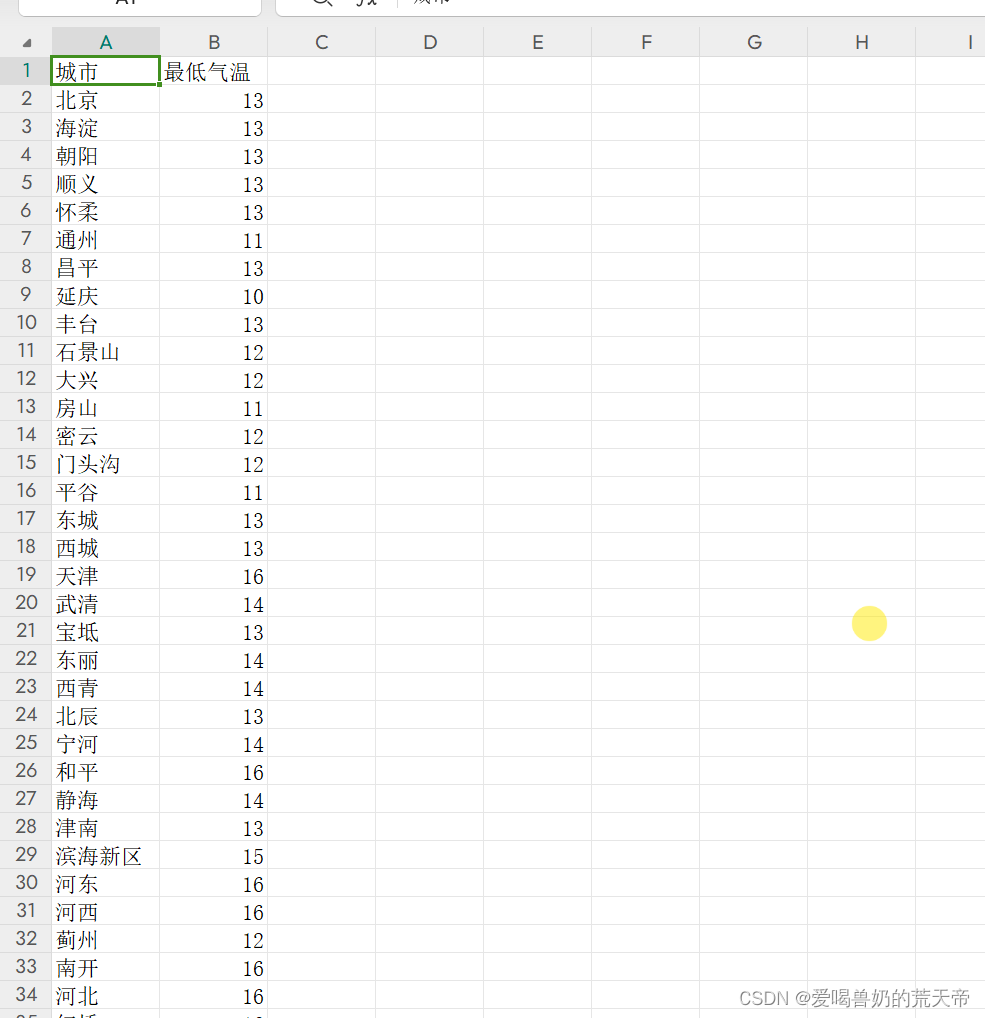
【Python爬虫实战入门】:全球天气信息爬取
文章目录 一、爬取需求二、所需第三方库2.1 简介 三、实战案例四、完整代码 一、爬取需求 目标网站:http://www.weather.com.cn/textFC/hb.shtml 需求:爬取全国的天气(获取城市以及最低气温) 目标url:http://www.weather.com.cn/textFC/hz.shtml 二、所需第三方库 requests B
selenium简介、使用selenium爬取百度案例、selenium窗口设置、
1 selenium简介 2 使用selenium爬取百度案例 3 selenium窗口设置 1 selenium简介 '''【一】web自动化随着互联网的发展,前端技术也在不断变化,数据的加载方式也不再是单纯的服务端渲染了。现在你可以看到很多网站的数据可能都是通过接口的形式传输的,或者即使不是接口那也是一些 JSON 的数据,然后经过 JavaScript 渲染得出来的。这时
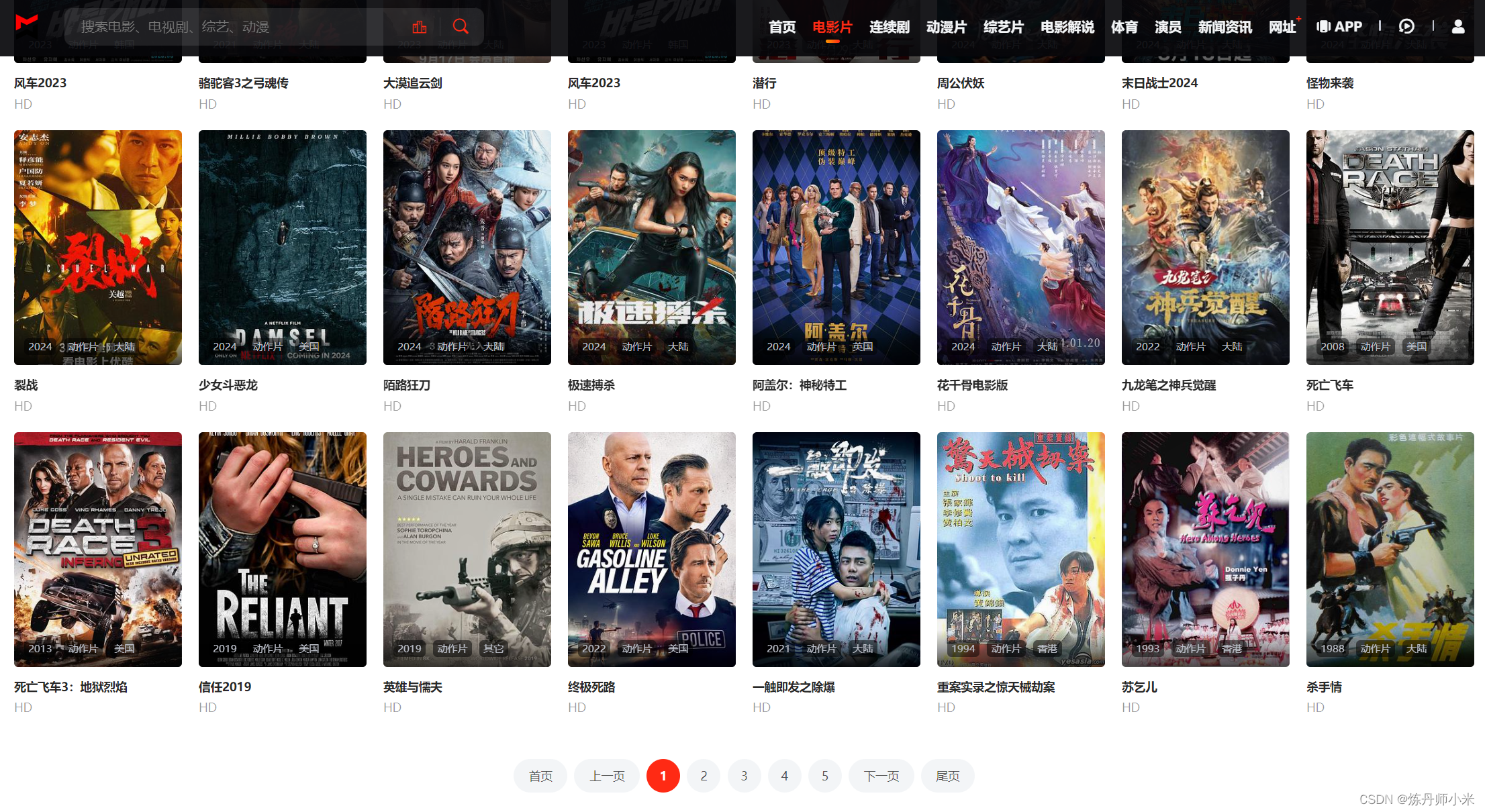
1.python爬虫爬取视频网站的视频可下载的源url
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、爬取的源网站二、实现代码总结 一、爬取的源网站 http://www.lzizy9.com/ 在这里以电影片栏下的动作片为例来爬取。 可以看到视频有多页,因此需要多页爬取。 二、实现代码 import requestsfrom bs4 import BeautifulSoupi

Python3网络爬虫(二):使用Beautiful Soup爬取小说
转载请注明作者和出处:http://blog.csdn.net/c406495762 运行平台: Windows Python版本: Python3.x IDE: Sublime text3 一、Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下: Beautiful Soup提供
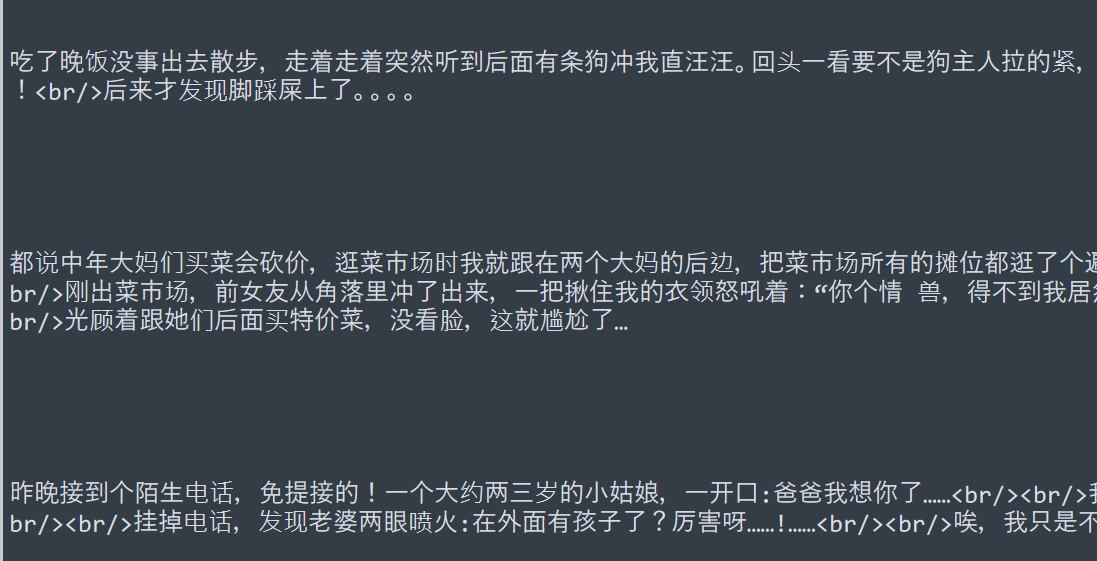
Python爬虫--爬取糗事百科段子
爬取糗事百科段子: 段子在 <div class="content"> 里面的 <span> 标签里面 不过这里有个坑,div 标签跟 span 标签 之间有很多空行 普通 .*? 是匹配不了的,需要使用模式修饰符 S S 的意思 让 .(点) 匹配,包括换行符 我们来爬文字的段子 先看看他的 url 有什么规律, https://www.qiushibaike.com/

java爬取网页内容 简单例子(2)——附jsoup的select用法详解
来源:http://www.cnblogs.com/xiaoMzjm/p/3899366.html?utm_source=tuicool&utm_medium=referral 【背景】 在上一篇博文 java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表达式 对
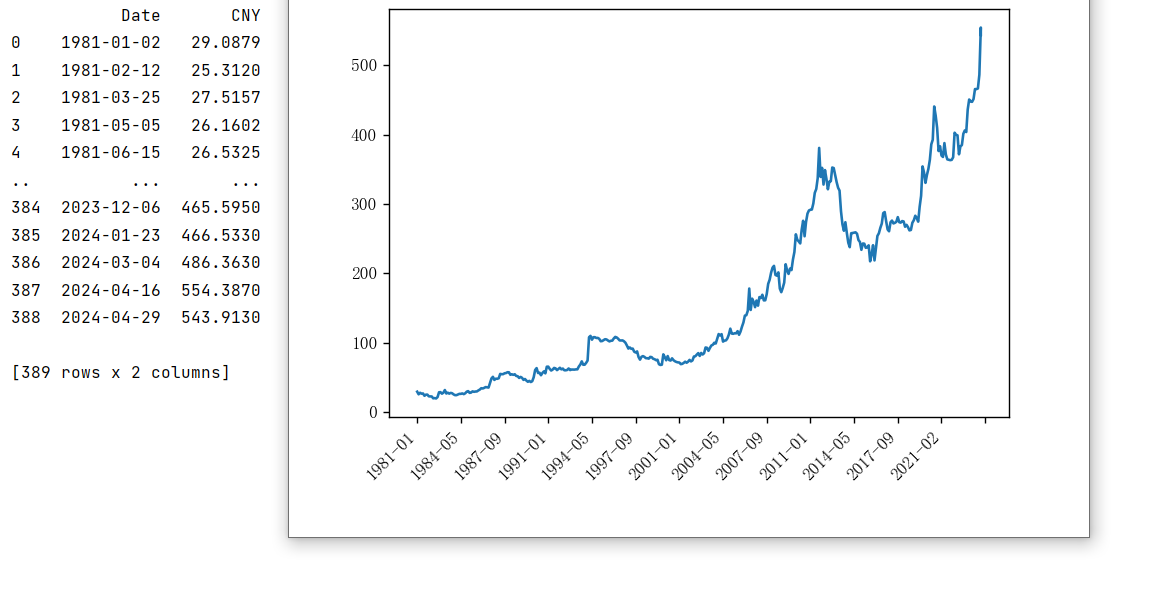
python爬取网页趋势图的底层数据信息——以历年的黄金价格为例
一、问题引入 黄金价格网址:https://china.gold.org/goldhub/data/gold-prices 问题引入:现有历年的黄金价格信息(如图所示),但呈现的方式是趋势图,并没有直接以表格的形式罗列出来,只有当鼠标悬停在趋势图上方才显示所指日期的黄金价格信息,本次python程序的目标是将历年的黄金价格信息爬取下来并绘图展示。 二、基本思路 右键
【酱浦菌-爬虫项目】python爬取彼岸桌面壁纸
首先,代码导入了两个库:requests和parsel。这些库用于处理HTTP请求和解析HTML内容。 然后,它定义了一个变量url,指向网站’樱花2024年4月日历风景桌面壁纸_高清2024年4月日历壁纸_彼岸桌面’。 接下来,设置了一个HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。 通过requests.get()方法,发送一个GET请求到指定的URL,并将响应内容保存在
五一假期终于到了!是时候偷偷发力了!——早读(逆天打工人爬取热门微信文章解读)
狗子,别偷跑!给我好好休息 引言Python 代码第一篇 洞见 无论在哪儿上班,冷漠是你最后的底线第二篇 人民日报要闻社会政策 结尾 我们不应该把休息 仅仅看作身体的需求 而敷衍了事 我们要把休息 看成一种机遇 停下工作 好好休息 并没有妨碍创造力 而是对创造力进行的一种投资 引言 今天是四月最后一天啦 明天开始就是五一假期 让我们开始 进入假期状态! 什

【酱浦菌-爬虫项目】四种方法爬取百度首页信息
项目原理: 首先,定义了四个函数,每个函数都有不同的功能: func1():发送一个GET请求到百度网站,并获取响应内容,演示如何使用`requests`库来获取网页内容。 func2():发送一个GET请求到百度网站,并获取响应内容。然后将响应内容保存为名为“baidu.png”的图片文件。 func3():使用Splash执行Lua脚本,加载百度网站并等待2秒,然后返回HTML内容。
【酱浦菌-爬虫项目】爬取百度文库文档
1. 首先,定义了一个变量`url`,指向百度文库的搜索接口 ‘https://wenku.baidu.com/gsearch/rec/pcviewdocrec’。 2. 然后,设置了请求参数`data`,包括文档ID(`docId`)和查询关键词(`query`)。 3. 定义了HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。 4. 使用`requests.get()`方法,发送一个