注意力专题
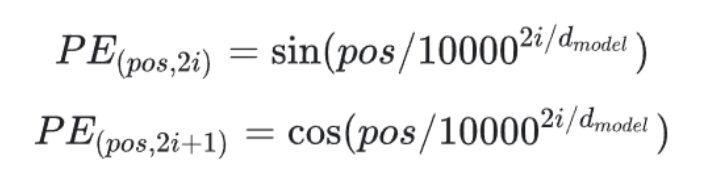
Python深度学习基于Tensorflow(9)注意力机制
文章目录 注意力机制是怎么工作的注意力机制的类型 构建Transformer模型Embedding层注意力机制的实现Encoder实现Decoder实现Transformer实现 注意力机制的主要思想是将注意力集中在信息的重要部分,对重要部分投入更多的资源,以获取更多所关注目标的细节信息,抑制其他无用信息; 在注意力机制的背景下,我们将自主性提示称为查询(Query)。对
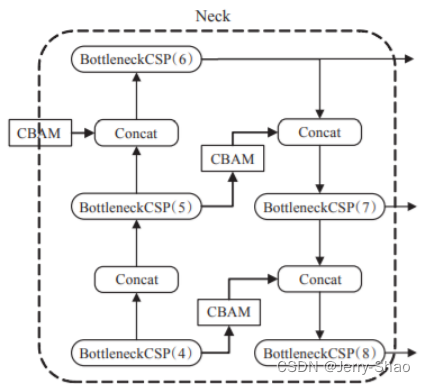
改进YOLOv5,YOLOv5+CBAM注意力机制
目录 1. 目标检测模型 2. YOLOv5s 3. YOLOv5s融合注意力机制 4. 修改yolov5.yaml文件 5. ChannelAttentionModule.py 6. 修改yolo.py 1. 目标检测模型 目标检测算法现在已经在实际中广泛应用,其目的是找出图像中感兴趣的对象,并确定对象的类别和位置。本文将目标检测算法分为传统的技术和

EfficientNet网络结构详细解读+SE注意力机制+pytorch框架复现
文章目录 🚀🚀🚀前言一、1️⃣ 网络详细结构1.1 🎓 MBConv结构1.2 ✨SE注意力机制模块1.3 ⭐️Depthwise Separable Convolution深度可分离卷积1.3.1 普通卷积操作(Convolution)1.3.2 逐深度卷积(Depthwise Convolution)1.3.3 逐点卷积(Pointwise Convolution)🔥
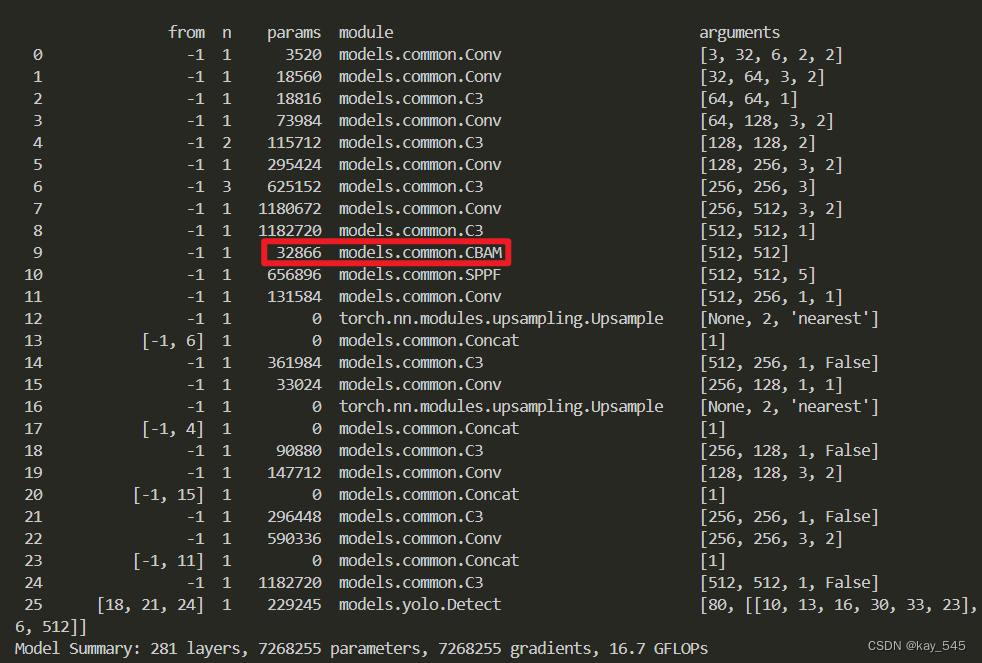
YOLOv5改进 | 注意力机制 | 通道和空间的双重作用的CBAM注意力机制
在深度学习目标检测领域,YOLOv5成为了备受关注的模型之一。本文给大家带来的是通道和空间的双重作用的CBAM注意力机制。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。 专栏地址:YOLOv5改进+入门——持续更新各种有效涨点方法 目
从头理解transformer,注意力机制(下)
交叉注意力 交叉注意力里面q和KV生成的数据不一样 自注意力机制就是闷头自学 解码器里面的每一层都会拿着编码器结果进行参考,然后比较相互之间的差异。每做一次注意力计算都需要校准一次 编码器和解码器是可以并行进行训练的 训练过程 好久不见输入到编码器,long time no see输入到解码器,按照transformer的编码和解码这个过程逐渐往上进行计算。 有交叉注
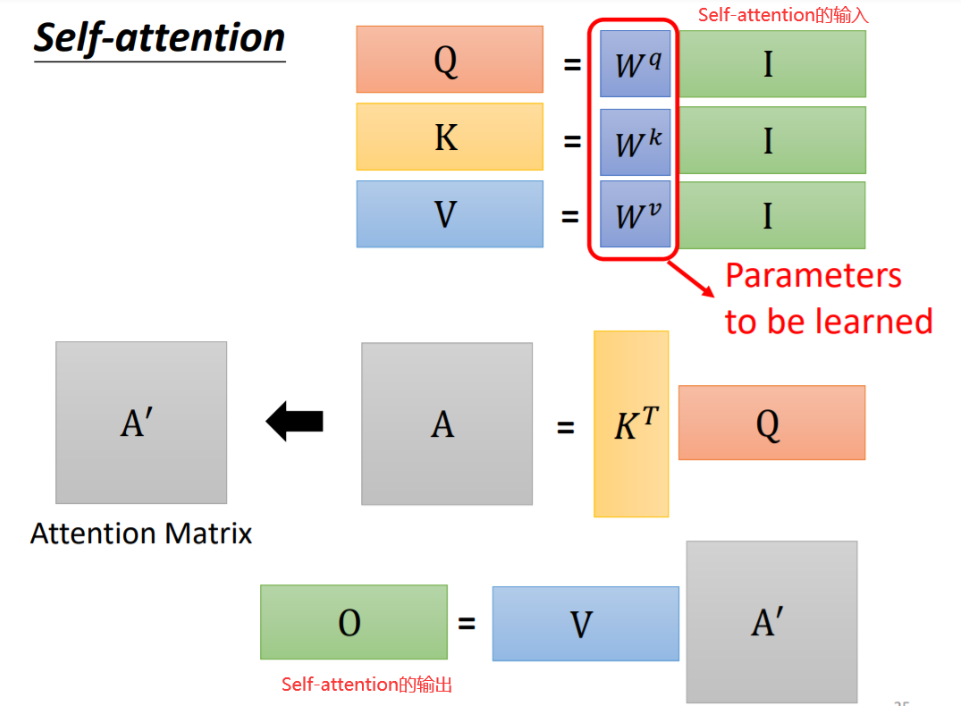
李宏毅-注意力机制详解
原视频链接:attention 一. 基本问题分析 1. 模型的input 无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量,长度可能会不同,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样。解决这个问题的方法是One-hot Encoding以及Word Embedding,其中Wo

即插即用篇 | YOLOv8引入PSAModule | 高效金字塔压缩注意力模块
本改进已集成到 YOLOv8-Magic 框架。 最近研究表明,通过在深度卷积神经网络中嵌入注意力模块可以有效地提高网络性能。在这项工作中,提出了一种新的轻量级且有效的注意力方法,名为金字塔挤压注意力(PSA)模块。通过在ResNet的瓶颈块中用PSA模块替换3x3卷积,得到了一种新的表征块,称为高效金字塔挤压注意力(EPSA)块。EPSA块可以轻松地作为即插即用的组件添加到一个成熟
邻域注意力Transformer
邻域注意力(NA),这是第一个高效且可扩展的视觉滑动窗口注意力机制,NA是一种逐像素操作,将自注意力(SA)定位到最近的相邻像素,因此与SA的二次复杂度相比,具有线性时间和空间复杂度。与Swin Transformer的窗口自注意力不同,滑动窗口模式允许NA的感受野增长,而无需额外的像素移位,并保留平移等变性。 Neighborhood Attention Transformer可以自适应地将
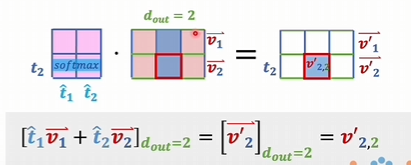
从头理解transformer,注意力机制(上)
深入理解注意力机制和Transformer架构,及其在NLP和其他领域的突破。 要想理解transformer,先从编码器解码器结构开始理解 基于transformer发展起来的llm 右边:只有解码器,强项是生成内容 左边:只有编码器,强项是学习和理解语言的内容 编码和解码的码究竟是什么码 图像领域 CNN 文字领域 RNN 从数学角度看,transformer和RNN是
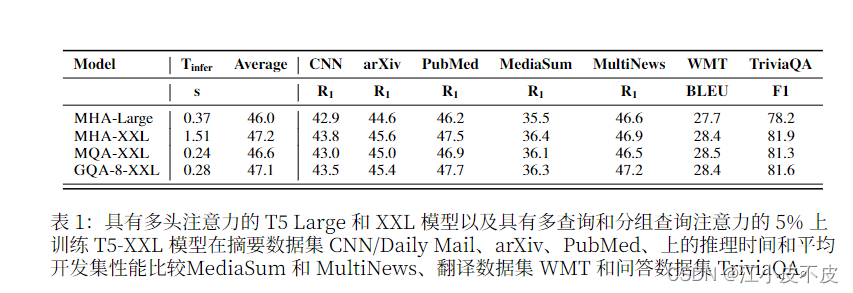
MHD、MQA、GQA注意力机制详解
MHD、MQA、GQA注意力机制详解 注意力机制详解及代码前言:MHAMQAGQA 注意力机制详解及代码 前言: 自回归解码器推理是 Transformer 模型的 一个严重瓶颈,因为在每个解码步骤中加 载解码器权重以及所有注意键和值会产生 内存带宽开销 下图为三种注意力机制的结构图和实验结果 MHA 多头注意力机制是Transformer模型中的核心组
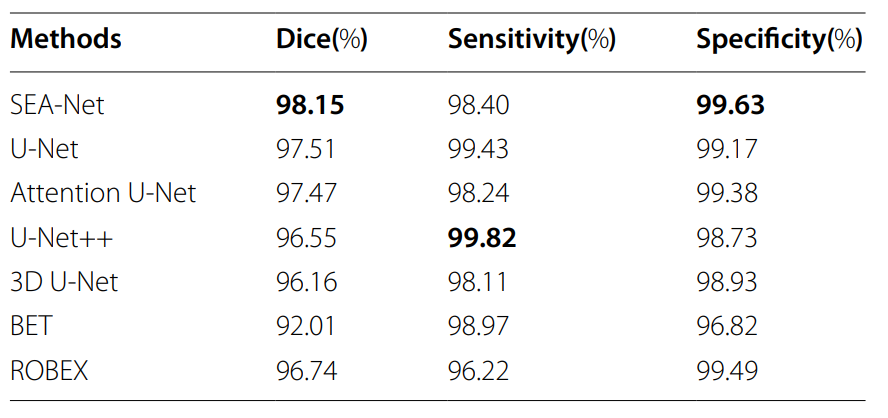
结合创新!通道注意力+UNet,实现高精度分割
在U-Net网络中加入通道注意力机制能显著提升模型的性能! 具体点说是在U-Net的卷积层之后添加一个通道注意力模块,这样这个模块可以学习不同通道之间的权重,并根据这些权重对通道进行加权,从而增强重要通道的特征表示。 这种结合通道注意力的U-Net网络模型对比传统模型,更能捕获图像中的关键信息,并提高模型的分割精度与泛化能力,在面对新的、未见过的图像时也能保持较高的性能。这也是为什么它一直是研
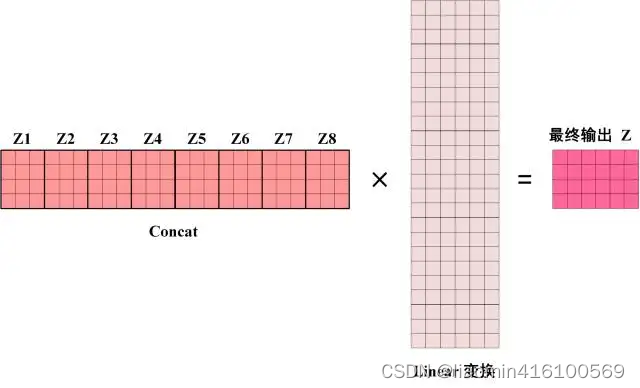
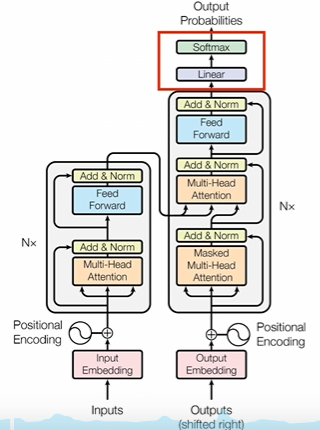
Transformer模型详解03-Self-Attention(自注意力机制)
文章目录 简介基础知识什么是AttentionSelf Attention原理通俗易懂理解矩阵计算Q,K,V计算Self-Attention 的输出 优势 Multi-head self-attention原理通俗易懂理解矩阵计算代码实现 简介 下图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈

YOLOV5中加入CA注意力机制,助力涨点!
首先找到models文件夹中的common.py文件,加入如下模块 #########CA###############class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def f
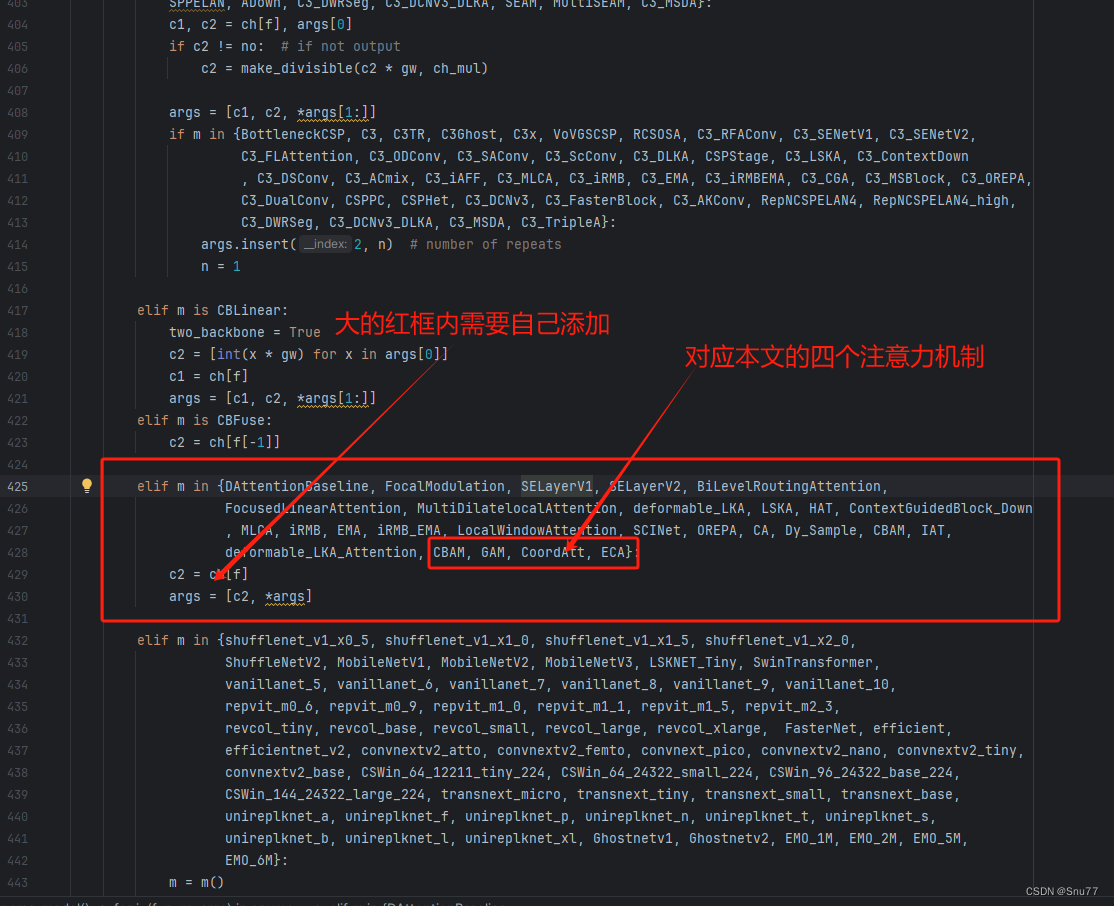
YOLOv9改进策略 | 添加注意力篇 | 一文带你改进GAM、CBAM、CA、ECA等通道注意力机制和多头注意力机制
一、本文介绍 这篇文章给大家带来的改进机制是一个汇总篇,包含一些简单的注意力机制,本来一直不想发这些内容的(网上教程太多了,发出来增加文章数量也没什么意义),但是群内的读者很多都问我这些机制所以单独出一期视频来汇总一些比较简单的注意力机制添加的方法和使用教程,本文的内容不会过度的去解释原理,更多的是从从代码的使用上和实用的角度出发去写这篇教程。 欢迎大家订阅我的专栏一起学习YOLO!

YOLOv8改进CBAM注意力机制
1,CBAM介绍 CBAM(Convolutional Block Attention Module)是一种用于增强卷积神经网络(CNN)性能的注意力机制模块。它由Sanghyun Woo等人在2018年的论文[1807.06521] CBAM: Convolutional Block Attention Module (arxiv.org)中提出。CBAM的主要目标是通过在CNN中引入通道注意

YOLOv9全网最新改进系列:YOLOv9完美融合标准化的注意力模块NAM,高效且轻量级的归一化注意力机制,助力目标检测再上新台阶!
YOLOv9全网最新改进系列:YOLOv9完美融合标准化的注意力模块NAM,高效且轻量级的归一化注意力机制,助力目标检测再上新台阶!!! YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er B站全文戳这里! 详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先! YOLOv9全网最新改进系
态、势、感、知四部分的注意力模型的融合
态、势、感、知在抢占注意力时往往是通过自身具有吸引力、引发情感共鸣或启发思考等方式来引起人们的注意和关注。态、势、感、知在抢占注意力方面的作用可以分别描述如下: 态:人们通常会被某种特定的姿态或面部表情所吸引,因为姿态能够传达出情感、意图或个性,从而引起观察者的共鸣或兴趣。 势:势具有一种引导和吸引注意力的能力,当事物或人物展现出强烈的力量或权威感时,往往会吸引人们的视线和注意力。 感:感情是人

【intro】图注意力网络(GAT)
论文阅读 https://arxiv.org/pdf/1710.10903 abstract GAT,作用于图结构数据,采用masked self-attention layers来弥补之前图卷积或类似图卷积方法的缺点。通过堆叠layers,让节点可以添加其邻居的特征,我们就可以给不同的邻居节点不同的权重,而这一步操作不需要使用任何昂贵的矩阵计算(比如求逆矩阵),也不需要依赖对图结构的了解。
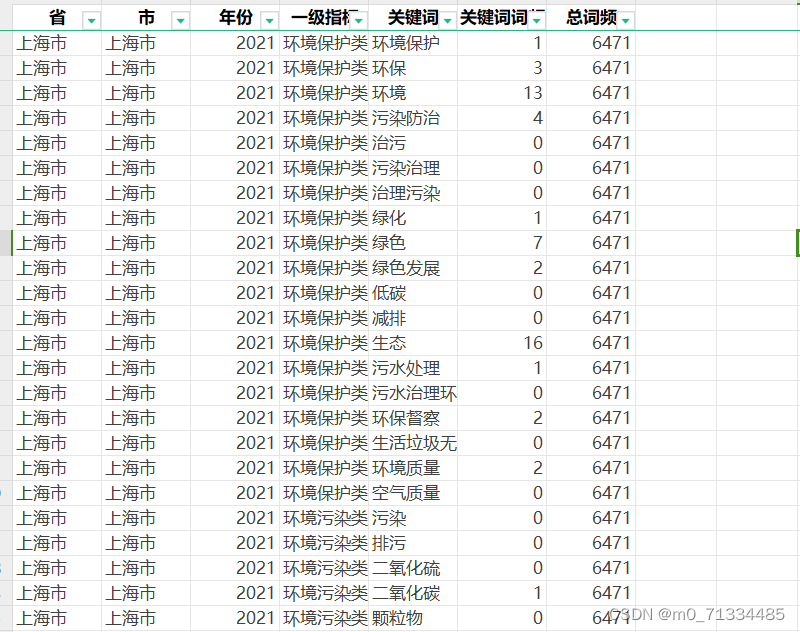
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计)
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 1、时间:2005-2021年 2、范围:270个地级市 3、指标: 省、市、年份、一级指标、关键词、关键词词频、总词频 4、来源:政府工作报告 5、关键词词频: 环境保护类: 关键词-环境保护、环保

#####好好好#####深度学习笔记——Attention Model(注意力模型)学习总结
深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。 AM刚开始也确实是应用在图像

###好好好#######论文浅尝 | 基于图注意力的常识对话生成
论文浅尝 | 基于图注意力的常识对话生成 OpenKG 祝各位读者新春快乐,猪年吉祥! 来源:IJCAI 2018. 论文下载地址:https://www.ijcai.org/proceedings/2018/0643.pdf 项目源码地址:https://github.com/tuxchow/ccm 动机 在以前的工作中,对话生成的信息源是文本与对话记录。但是这样一来
ICLR 2017 | 基于双向注意力流的机器理解
本文提出了双向注意力流(BIDAF)网络,是一种分层的多阶段架构,在不同粒度等级上对上下文进行建模。BIDAF包括字符级(character-level)、单词级(word-level)和上下文(contextual)的embedding,并使用双向注意力流来获取query-aware的上下文表示。 论文地址: https://arxiv.org/abs/1611.01603 代码地址: htt
深度学习中的注意力机制二(Pytorch 16)
一 Bahdanau 注意力 通过设计一个 基于两个循环神经网络的编码器‐解码器架构,用于序列到序列学习。具体来说,循环神经网络编码器将长度可变的序列转换为固定形状的上下文变量,然后循环神经网络 解码器根据生成的词元和上下文变量按词元生成输出(目标)序列词元。然而,即使并非所有输入(源)词 元都对解码某个词元都有用,在每个解码步骤中仍使用编码相同的上下文变量。有什么方法能改变上下文变 量呢?
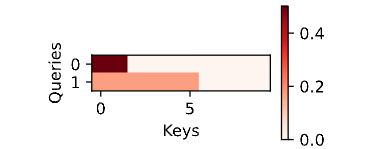
深度学习中的注意力机制一(Pytorch 15)
一 简介 灵长类动物的视觉系统接受了大量的感官输入,这些感官输入远远超过了大脑能够完全处理的程度。然而, 并非所有刺激的影响都是相等的。意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感 兴趣的物体,例如猎物和天敌。只关注一小部分信息的能力对进化更加有意义,使人类得以生存和成功。 自19世纪以来,科学家们一直致力于研究认知神经科学领域的注意力。首先回顾一个经典注意力框架,解释如何
【论文复现】Graph Attention Networks图注意力神经网络
图注意力神经网络 前言一、论文解读1.1 模型架构1.2 数学推导 二、代码复现2.1 数据准备2.1.1 数据转化2.1.2 创建数据集 2.2 模型构建2.2.1 参数设置2.2.2 模型代码2.2.3 pytorch官方GAT源码实现 2.3 模型训练 三、结果展示3.1 复现结果3.2 论文结果 四、代码细节代码链接 前言 这篇论文提出的核心方法就是在计算一个节点的输出的
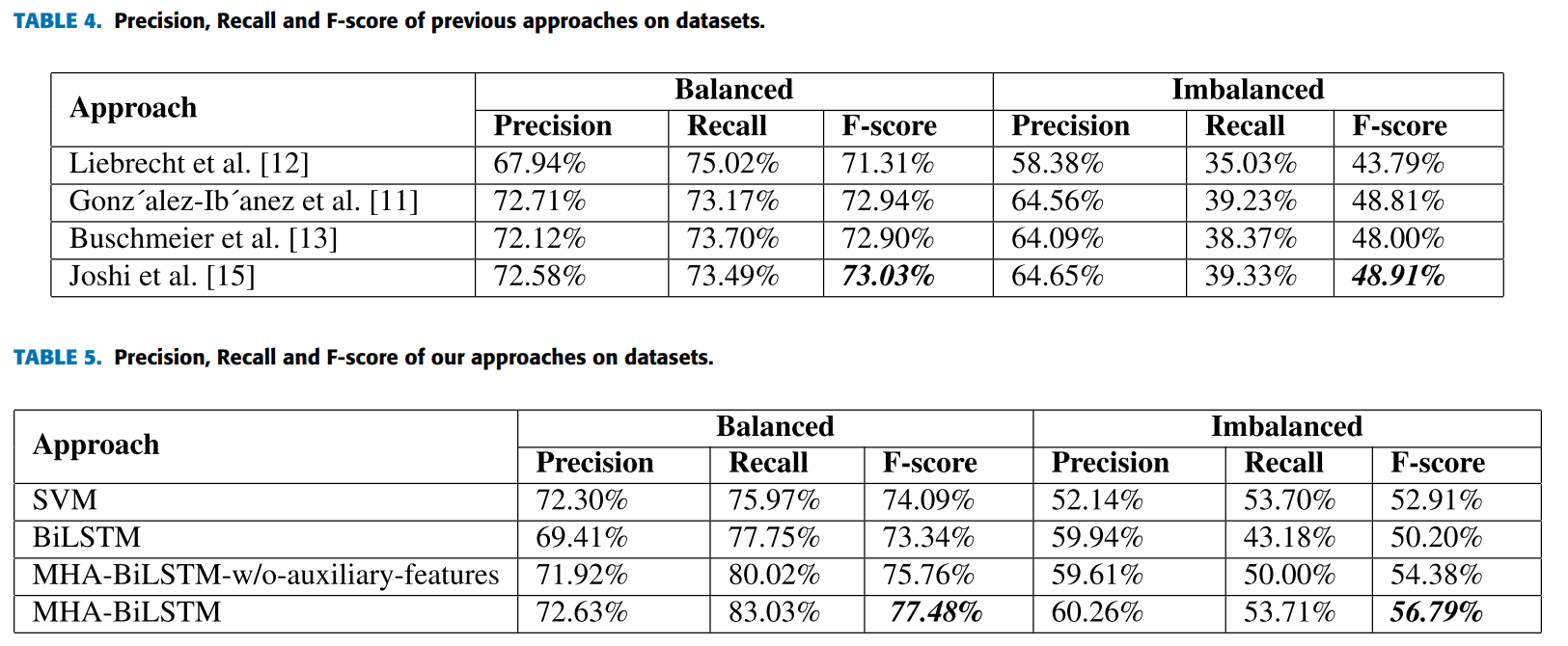
Sarcasm detection论文解析 |使用基于多头注意力的双向 LSTM 进行讽刺检测
论文地址 论文地址:https://ieeexplore.ieee.org/document/8949523 论文首页 笔记框架 使用基于多头注意力的双向 LSTM 进行讽刺检测 📅出版年份:2020 📖出版期刊:IEEE Access 📈影响因子:3.9 🧑文章作者:Kumar Avinash,Narapareddy Vishnu Teja,Aditya Sr