梯度专题

bert 的MLM框架任务-梯度累积
参考:BEHRT/task/MLM.ipynb at ca0163faf5ec09e5b31b064b20085f6608c2b6d1 · deepmedicine/BEHRT · GitHub class BertConfig(Bert.modeling.BertConfig):def __init__(self, config):super(BertConfig, self).__init_
超分辨率重建——梯度下降、坐标下降、牛顿迭代
在阅读相关文献的时候,经常会遇到梯度下降,坐标下降,牛顿迭代这样的术语,今天把他们的概念整理一下。 梯度下降 整理自百度 梯度下降法是一个最优化算法,通常也称为最速下降法。 顾名思义,梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。 其迭代公式为 ,其中 代表梯度负方向, 表示梯度方向上的搜索步长。梯度方向我们可以通过对

全国院校及梯度排序深度解析课(免费下载-帮助更多高考生做出人生重要的选择。)
"全国院校及梯度排序深度解析课"旨在深入探讨全国院校的排名及梯度排序原理。通过系统解析各院校的学术声誉、师资力量、科研水平等因素,帮助学员全面了解院校排名的背后逻辑,为选择合适院校提供理论支持。 课程大小:7G 课程下载:https://download.csdn.net/download/m0_66047725/89299927 更多资源下载:关注我。


Python梯度下降算法
梯度下降(Gradient Descent)是机器学习中用于最小化损失函数的优化算法。在Python中,可以通过手动实现或使用现有的库(如scikit-learn)来应用梯度下降算法。以下是手动实现简单线性回归问题的梯度下降算法的示例: 1. 定义损失函数(Cost Function) 假设我们使用的是均方误差(Mean Squared Error, MSE)作为损失函数: [ \text{

dimension reduce(梯度下降)self-organizing maps(自组织映射)
使数据集的维度减小可以简化问题,带来优化 如更快的处理时间、虚拟化高维度的数据集、抗噪音、增强其他数据挖掘算法 线性降维(Linear dimension reduce) main linear components能使数据在这一轴的变化范围最大 1-st component是使数据在这一维变化最大的轴方向 2-nd component是当投影到1-st component方向时数
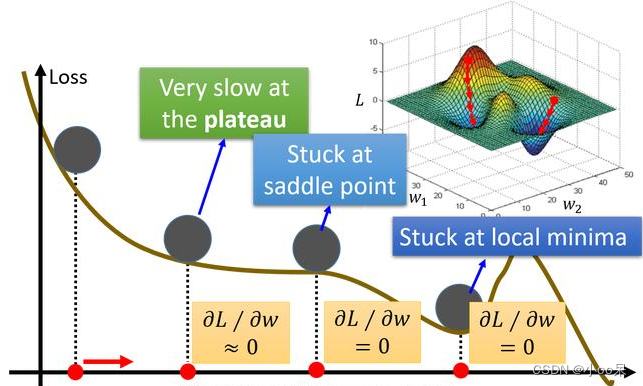
【机器学习300问】83、深度学习模型在进行学习时梯度下降算法会面临哪些局部最优问题?
梯度下降算法是一种常用的优化方法,用于最小化损失函数以训练模型。然而,在使用梯度下降算法时,可能会面临以下局部最优问题。 (一)非凸函数的局部极小值 问题描述:在复杂的损失函数中,如果目标函数是非凸函数,即存在多个局部最小值点,那么梯度下降有可能会在到达某个局部最小值后停止,而非全局最小值。这意味着找到的解决方案可能不是最优的。 解决思路: 增加随机性:通过引入随机性,
【机器学习300问】82、RMSprop梯度下降优化算法的原理是什么?
RMSprop,全称Root Mean Square Propagation,中文名称“均方根传播”算法。让我来举个例子给大家介绍一下它的原理! 一、通过举例来感性认识 建议你第一次看下面的例子时忽略小括号里的内容,在看完本文当你对RMSprop有了一定理解时再回过头来读一次这个小例子,这次带上小括号的内容一起读,相信你会有更深刻的体会。
【C++PCL】点云处理3D-SIFT关键点提取(Z方向梯度约束)
作者:迅卓科技 简介:本人从事过多项点云项目,并且负责的项目均已得到好评! 公众号:迅卓科技,一个可以让您可以学习点云的好地方 重点:每个模块都有参数如何调试的讲解,即调试某个参数对结果的影响是什么,大家有问题可以评论哈,如果文章有错误的地方,欢迎来指出错误的地方。 目录 1.原理介绍 2.代码效果 3.源码展示 4.
【机器学习300问】79、Mini-Batch梯度下降法的原理是什么?
Mini-Batch梯度下降法是一种将训练数据集分成小批次进行学习的优化方法,通过这种方式,可以有效地解决内存限制问题并加速学习过程。 一、为什么要使用Mini-Batch? 在机器学习尤其是深度学习中,我们常常面临海量数据处理的问题。如果我们一次性将所有的数据加载进内存做训练,很可能会遇到内存不足的情况。此外,处理如此大批量的数据也会导致训练速度变慢。为了解决这
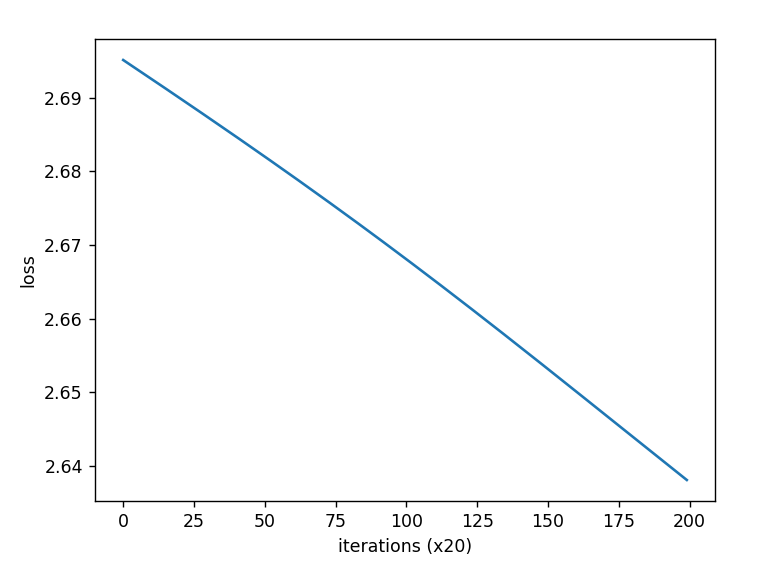
随机梯度下降SGD的理解和现象分析
提出问题:令人疑惑的损失值 在某次瞎炼丹的过程中,出现了如下令人疑惑的损失值变化图像: 嗯,看起来还挺工整,来看看前10轮打印的具体损失值变化: | epoch 1 | iter 5 / 10 | time 1[s] | loss 2.3137 | lr 0.0010| epoch 1 | iter 10 / 10 | time 1[s] | loss 2.2976 | lr 0.00
单位圆内的正交向量多项式,第一部分:由Zernike多项式的梯度导出的基组
clear all;close all;clc;%%I1=double(imread('E:\zhenlmailcom-E8E745\华为家庭存\image\imgs\right\0.bmp'));I2=double(imread('E:\zhenlmailcom-E8E745\华为家庭存储\.法\image\imgs\right\1.bmp'));I3=double(imr
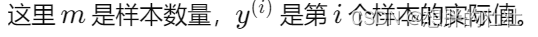
机器学习 - 梯度下降算法推导
要逐步推导多变量线性回归的梯度计算过程,我们首先需要明确模型和损失函数的形式,然后逐步求解每个参数的偏导数。这是梯度下降算法核心部分,因为这些偏导数将指导我们如何更新每个参数以最小化损失函数。 模型和损失函数 考虑一个多变量线性回归模型,模型预测可以表示为: h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n h_{\theta}(x) = \
深度学习常用优化算法笔记介绍,各种梯度下降法详细介绍
优化算法 mini-batch梯度下降法 当一个数据集其数据量非常大的时候,比如上百万上千万的数据集,如果采用普通的梯度下降法,那么运算速度会非常慢,因为如果使用梯度下降法在每一次迭代的时候,都需要将这整个上百万的数据给执行一遍所以我们可以将我们的大的数据分成一个一个小一点的数据集,然后分批次处理,比如我们有100万个数据,那么我们可以将其分成1000份,每份1000个数据,这里的一份就是所谓

用Python进行梯度提升算法的参数调整
引言 或许之前你都是把梯度提升算法(Gradient Boosting Model)作为一个“黑箱”来用,那么现在我们就要把这个黑箱打开来看,里面到底装着什么玩意儿。 提升算法(Boosting)在处理偏差-方差权衡的问题上表现优越,和装袋算法(Bagging)仅仅注重控制方差不同,提升算法在控制偏差和方差的问题上往往更加有效。在这里,我们提供一个对梯度提升算法的透彻理解,希望他能让你在处理
微积分 --- 偏导数,方向导数与梯度(二)
方向导数 上图为一温度图,所反映的是加利福利亚洲和内华达州在十月的一天下午三点的温度。其中,图中的每一点都是温度T关于x,y的函数,即T(x,y)。对于图中的Reno市而言,沿着x方向的偏导反映的是温度沿着x方向,即沿着东方的变化率。沿着y方向的偏导反映了温度沿着北方,即y方向的变化率。这些偏导数的求法在介绍偏导数的时候都已经知道了。但如果我现在要求图中一任意方向的变

最大似然估计、梯度下降、EM算法、坐标上升
机器学习两个重要的过程:学习得到模型和利用模型进行预测。 下面主要总结对比下这两个过程中用到的一些方法。 一,求解无约束的目标优化问题 这类问题往往出现在求解模型,即参数学习的阶段。 我们已经得到了模型的表达式,不过其中包含了一些未知参数。 我们需要求解参数,使模型在某种性质(目标函数)上最大或最小。 最大似然估计:
Grad-CAM(梯度加权类激活图)
Grad-CAM(Gradient-weighted Class Activation Mapping)是一种可视化技术,用于解释卷积神经网络(CNN)的决策过程。它通过生成类激活图(Class Activation Map,CAM)来突出显示对网络预测贡献最大的图像区域。以下是Grad-CAM的基本原理和流程: 原理: 梯度计算:Grad-CAM利用了神经网络在输出层对特定类别的梯度。这些梯
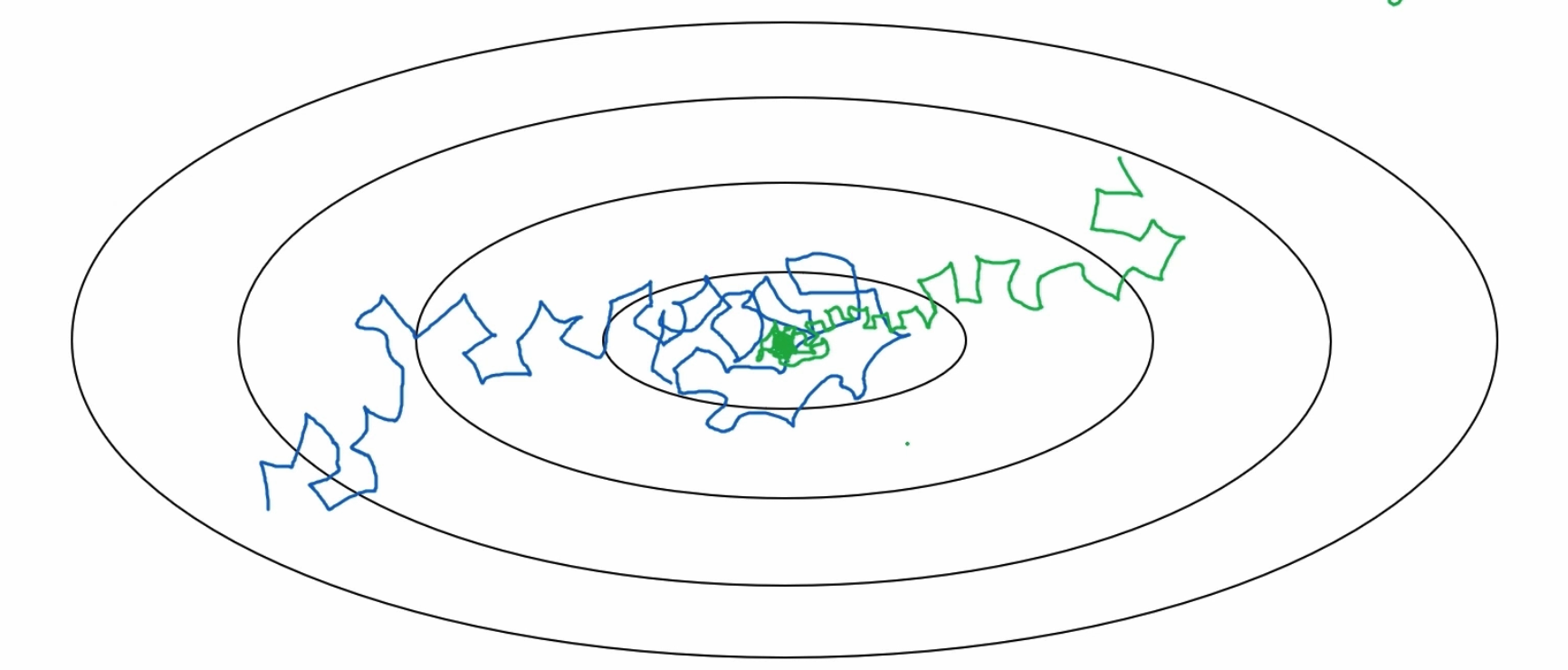
【跟马少平老师学AI】-【神经网络是怎么实现的】(五)梯度消失问题
一句话归纳: 1)用sigmoid激活函数时,BP算法更新公式为: 用sigmoid函数,O取值为0~1,O(1-O)最大值为0.25,若神经网络层数多,则会造成更新项趋近于0,称为梯度消失。 2)GooLeNet解决梯度消失的问题: 在不同的深度构造了3个输出。inception模块: 其中,1*1卷积起到改变维度的作用,减少参数个数,比如,输入为19

scikit-learn linearRegression 1.1.11 随机梯度下降
1.5. 随机梯度下降 Stochastic Gradient Descent (SGD) 是一种简单但又非常高效的方式判别式学习方法,比如凸损失函数的线性分类器如 Support Vector Machines 和 Logistic Regression. 虽然SGD已经在机器学习社区出现很长时间,但是在近期在大规模机器学习上受到了相当大数量的关注。 SGD 已经被成功应用到大规模和稀

第一周-机器学习-梯度下降(gradient descent)
这仅是本人在cousera上学习机器学习的笔记,不能保证其正确性,谨慎参考 1、梯度下降函数,一直重复下面公式直到收敛(repeat until convergence),此时即可收敛得到局部最小值(converge to local minimum),该梯度下降法对多参数也可用(例如θ0,θ1,θ2,θ3,θ4,θ5……θn),注意该过程对每一次的j迭代是需要同步更新参数的(At each i


AI笔记: 线性回归模型梯度下降法求解
梯度 在微积分中,一元函数f(x)在x处的梯度为函数在该点的导数 df⁄dx对多元函数 f ( x 1 , . . . , x D ) f(x_1, ..., x_D) f(x<
反向传播算法与梯度下降的交织乐章:深度学习中的双重奏
一、引言 在深度学习的宏大乐章中,反向传播算法和梯度下降无疑是两大核心旋律。它们交织在一起,共同推动着神经网络的学习与进化。本文旨在深入探讨这两者之间的关系,以及它们如何在深度学习中发挥着不可或缺的作用。我们将从基础概念出发,逐步深入到它们的内在机制和应用实践,以期为读者提供一个全面而深入的理解。 二、梯度下降:深度学习的导航仪 梯度下降,作为一种优化算法,其核心思想是通过迭代地调整参数,使
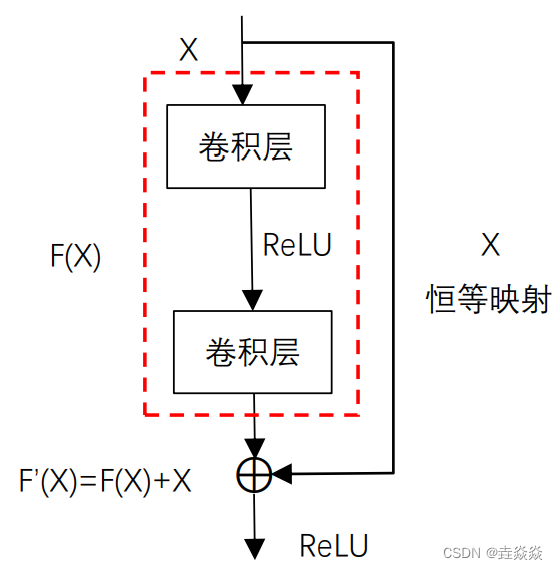
OpenCV12开操作_闭操作_形态学梯度_顶帽_黑帽
/* by txwtech 开操作- open 先腐蚀后膨胀 可以去掉小的对象,假设对象是前景色,背景是黑色 闭操作- close 先膨胀后腐蚀(bin2) 可以填充小的洞(fill hole),假设对象是前景色,背景是黑色 形态学梯度- Morphological Gradient 膨胀减去腐蚀 又称为基本梯度(其它还包括-内部梯度、方向梯度) 顶帽 – top hat 顶帽 是原图像
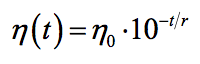
深度学习 | 梯度下降法
梯度下降法(Gradient descent optimization) 理想的梯度下降算法要满足两点:收敛速度要快;能全局收敛 重点问题:如何调整搜索的步长(也叫学习率,Learning Rate)、如何加快收敛速度、如何防止搜索时发生震荡 分类: 批量梯度下降法(Batch gradient descent) 随机梯度下降法(Stochastic gradient descent)