机器专题

机器学习实战——条件随机场(CRF)
声明:本文是在《最优化方法》课程中阅读的Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data这篇文章后的总结。 CRF由来 条件随机场(CRF)这种用来解决序列标注问题的机器学习方法是由John Lafferty于2001年发表在国际机器学习大会ICML上的一篇经典文章
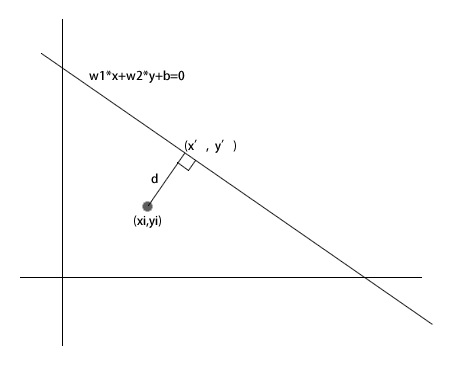
机器学习实战——SVM(3/3)
前面两篇总结了线性支持向量机模型,总体来说,就是在样本输入空间下对每个维度进行线性组合之后使用符号函数判别最终的类别。第一个是理想情况下的线性可分SVM,这是第二个的近似线性可分SVM的基础。而且也是一种递进关系,是为了从数学抽象化的理想模型到现实情形的一种推广,但它们终究是一种线性模型,对于更复杂的现实情形有时候依然会难以描述,需要使用非线性模型去描述。 非线性SVM 由于现实问题的复杂性,
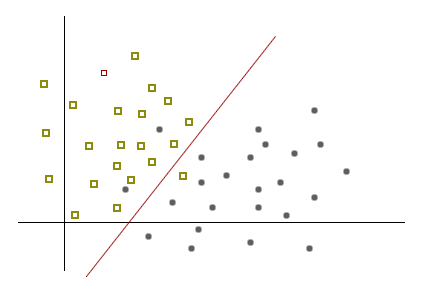
机器学习实战——SVM(2/3)
上一篇总结了对于训练数据集线性可分的理想情况下,使用硬间隔最大化训练得到分类超平面的SVM方法,这种方法在实际应用中并不实用,因为实际的训练数据总是会存在人为或不可控的因素干扰产生各种噪声,因此是无法在特征空间下找到线性可分的超平面的,但是噪声总是有限的,可以对硬间隔这个限制进行放松,引入一个松弛变量来控制分类超平面的训练,从而可以对近似可以线性可分的实际应用数据进行学习和预测。从这里也可以很明显
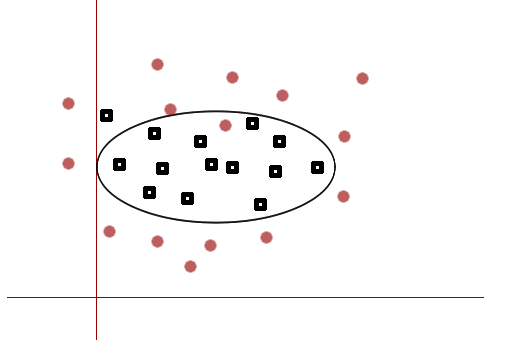
机器学习实战——SVM(1/3)
SVM(支持向量机)是典型的二分类的判别式模型,这种方法以Rosenblatt于1957年提出的感知机模型的基础上,都是通过训练一个分类超平面之后,作为分类的决策函数,然后对未知的样本进行预测。通过对输入特征使用法向量和截距 w=(w1,w2,...wn)、b w=(w_1,w_2,...w_n)、b进行线性组合,得到超平面,最终的决策函数也和感知机一样,为符号函数 f(x)=sign(w⃗ ⋅x

机器学习实战——最大熵模型
信息熵 香农与1948年提出的信息论以其中的信息熵这一基本概念为基础,用来表征人们对客观事件的不确定性的度量,与物理学中的熵表征物质的混乱程度有相似之处。 当处理不确定事件时,最常用的方式就是用概率方式描述,一般假定不确定的事件A每种可能的状态都有一个概率与之对应: P(Ai)s.t.∑i=1nP(Ai)=1P(Ai)≥0 P(A_i)\\ s.t.\sum_{i=1}^nP(A_
机器学习——朴素贝叶斯(NBC)
朴素贝叶斯分类(NBC)是机器学习中最基本的分类方法,是其他众多分类算法分类性能的对比基础,其他的算法在评价性能时都在NBC的基础上进行。同时,对于所有机器学习方法,到处都蕴含着Bayes统计的思想。 朴素贝叶斯基于贝叶斯地理和特征条件独立性假设,首先基于条件独立性假设学习输入 X X和输出YY的联合分布 P(X,Y) P(X,Y),同时利用先验概率 P(Y) P(Y),根据贝叶斯定理计算出后验
机器学习实战——感知机
感知机学习策略具体实现 数据集最大最小规范化训练过程测试最终结果 感知机是二分类的线性分类模型,由Rosenblatt于1957年提出,是支持向量机和神经网络的基础。感知机将学习到一个线性划分的分离超平面,属于判别模型。 感知机 输入空间为 Rn R^n空间, n n是特征数目,输出空间y={+1,−1}y=\{+1,-1\}。感知机学习一个如下的符号函数: f

sklearn机器学习编程练习大全(一)
sklearn机器学习编程练习大全 第1题 计算DataFrame每列的缺失值比例第2题 填充缺失值第3题 使用常量填充缺失值第4题 使用最频繁出现的值填充缺失值第5题 过滤掉存在空值的行第6题 使用常量填充字符串列第7题 数值离散化第8题 虚拟编码第9题 提取元素的个数第10题 特征提取--是否包含某个元素 第1题 计算DataFrame每列的缺失值比例 DataFrame如下
机器学习 - 朴素贝叶斯
朴素贝叶斯是基于贝叶斯定理的一种简单且高效的分类方法,特别适用于文本分类和情感分析等任务。 1. 贝叶斯定理简介 贝叶斯定理描述了后验概率(即在已知某些证据后某事件发生的概率)如何通过先验概率(即事件在未观测到任何证据前的概率)和似然(即在事件发生时观测到某些证据的概率)来计算。其公式如下: P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B
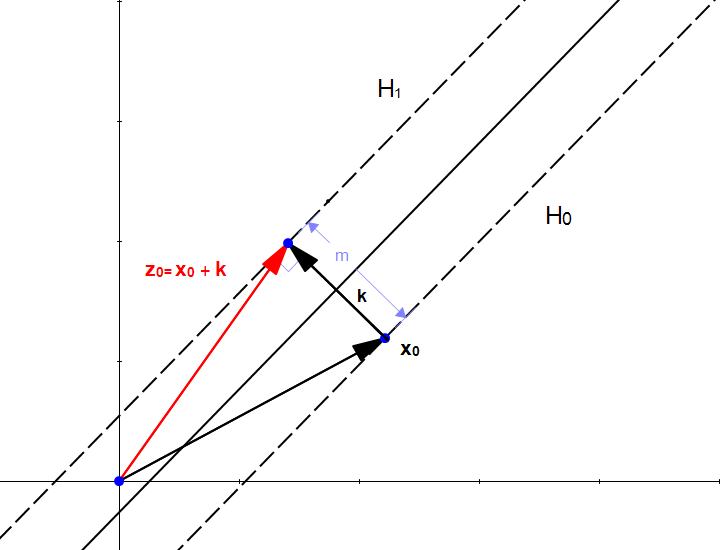
机器学习系列(15)_SVM碎碎念part3:如何找到最优分离超平面
作者:寒小阳 时间:2016年9月。 出处:http://blog.csdn.net/han_xiaoyang/article/details/52683653 声明:版权所有,转载请联系作者并注明出处 1.引言 是的,咱们第1篇blog介绍了目标;第2篇blog介绍了向量相关的背景数学知识,看到了如何求解Margin的值;今天这个部分主要目的是和大家一起来看看,选择
贴几个用PYTHON的机器学习的入门贴
PYTHON 学机器学习,我是初学者,都是自学。已经工作了,时间不多,困难不少。 贴一些我认为入门必须的文章。供没有基础的同学参考。水平有限,还没入门呢,一起进步吧。 刚开始准备从tensorflow开始。发现看不懂。算了,还是从基础的开始。不会tensorflow也能玩机器学习。有了基础后再学tensorflow不迟。 需要的基础知识,包括用python的基础,np的数组、矩阵,ma
![Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明](https://img-blog.csdnimg.cn/direct/09c88a3f23d54bb4ba5b0a52a1ad87c6.png)
Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明
Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明 目录 Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明 一、简单介绍 二、监督学习 算法 说明前的 数据集 说明 三、监督学习 之 神经网络(深度学习) 1、神经网络模型 2、神经网络调参 3、优点、缺点和参数 附录 一、如果报错 ModuleN
机器学习算法那些事 | 60个“特征工程”计算函数(Python代码)
本文来源公众号“机器学习算法那些事”,仅用于学术分享,侵权删,干货满满。 原文链接:60个“特征工程”计算函数(Python代码) 近期一些朋友询问我关于如何做特征工程的问题,有没有什么适合初学者的有效操作。 特征工程的问题往往需要具体问题具体分析,当然也有一些暴力的策略,可以在竞赛初赛前期可以带来较大提升,而很多竞赛往往依赖这些信息就可以拿到非常好的效果,剩余的则需要结合业务逻辑以及很多其
node.js 版本切换——一台机器快速使用不同的nodejs版本
nodejs 版本切换(windows版) 一、按健win+R弹出窗口,键盘输入cmd,然后敲回车。然后进入命令控制行窗口,并输入where node查看之前本地安装的node的路径。 二、找到上面找到的路径,将node.exe所在的父目录里面的所有东西都删除。 三、从官网下载安装包 https://github.com/coreybutler/nvm-windows/release
机器学习-MLP预测
本文使用机器学习MLP对数据进行预测。 1、数据 1.1 训练数据集: medol.xlsx文件示例 otv3015-1.9153622093018-1.9634097763021-1.7620284083024-1.789477583 1.2 预测数据集 test.xlsx文件示例 ot35163519 2、模型训练 train.py import pandas as

机器学习算法之线性回归的推导及应用
“ 阅读本文大概需要 3 分钟。 ” 之前说过会陆续写一些基本的机器学习算法的原理、推导和应用的文章,今天开始连载啦。 每篇文章的思路是这样的: 如果大家觉得有哪些可以优化的地方可以留言给我,我会慢慢完善的。再后面会陆续放送各个机器学习算法、深度学习模型及相关的实例实践,希望对大家有帮助。 今天首先讲解最基本的机器学习算法,线性回归。 线性回归是机器学习中最基本的算法了,一般要学习机器学习

美国 AI 顶级院校博士机器学习课程是什么样的?
训练营采用美国顶级院校的教学体系,帮助你在 4-6 个月内找到一份人工智能、机器学习、深度学习、数据科学家、算法工程师等AI相关岗位,或协助你申请美国、欧洲相关院校 AI 方向的学位。 由于 AI 领域的飞速发展,课程也会与时俱进。由 11 位美国 AI 博士组成的教研团队会确保在 2 周之内新出的重要技术,第一时间可以让你学会并熟练应用。 让我们来了解一下这个课程深度对标卡耐基梅隆大
小马的零基础机器学习推荐
“ 阅读本文大概需要 7 分钟。 ” 哈喽大家好,这里是编辑部小马。今天想分享我自己的机器学习入门的感想,希望能对大家有借鉴价值。 我本人(小马,不是崔哥)本科其实是自动化毕业的,目前在北京读研,读研期间转的数据挖掘方向,开始学习 Python。学习编程是个大趋势,别说是自动化专业本身就有涉及,很多经济学甚至是心理学这种看似无关的研究生同学,也都在学习相关的内容。但一开始的学习非常痛苦——尤其

机器学习过拟合和欠拟合!看这一篇文章就够了 建议收藏!(上篇)
在机器学习中,有一项非常重要的概念,那就是:过拟合(Overfitting)和欠拟合(Underfitting)。 它们涉及到机器学习中常见的两种模型性能问题,分别表示模型在训练数据上表现得过于复杂或过于简单。 下面咱们先来简单聊聊关于过拟合和欠拟合的特征和防止性能问题的方法。 大家伙如果觉得还不错!可以点赞、转发安排起来,让更多的朋友看到。 ok,咱们一起来看看~ 过拟合(Overfi
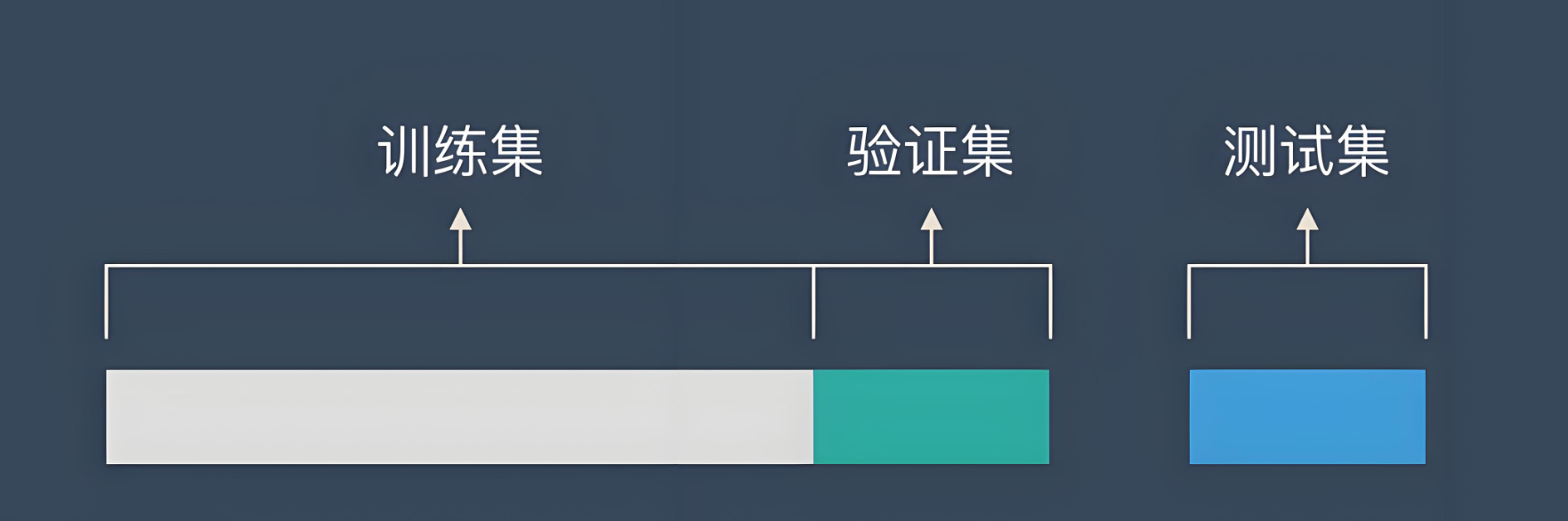
训练集、测试集与验证集:机器学习模型评估的基石
在机器学习中,为了评估模型的性能,我们通常会将数据集划分为训练集(Training Set)、验证集(Validation Set)和测试集(Test Set)。这种划分有助于我们更好地理解模型在不同数据上的表现,并据此调整模型参数,避免过拟合和欠拟合。本文将详细介绍这三个集合的作用,并通过代码演示如何进行数据集的划分。 目录 一、训练集、验证集与测试集的作用 二、为什么需要这样
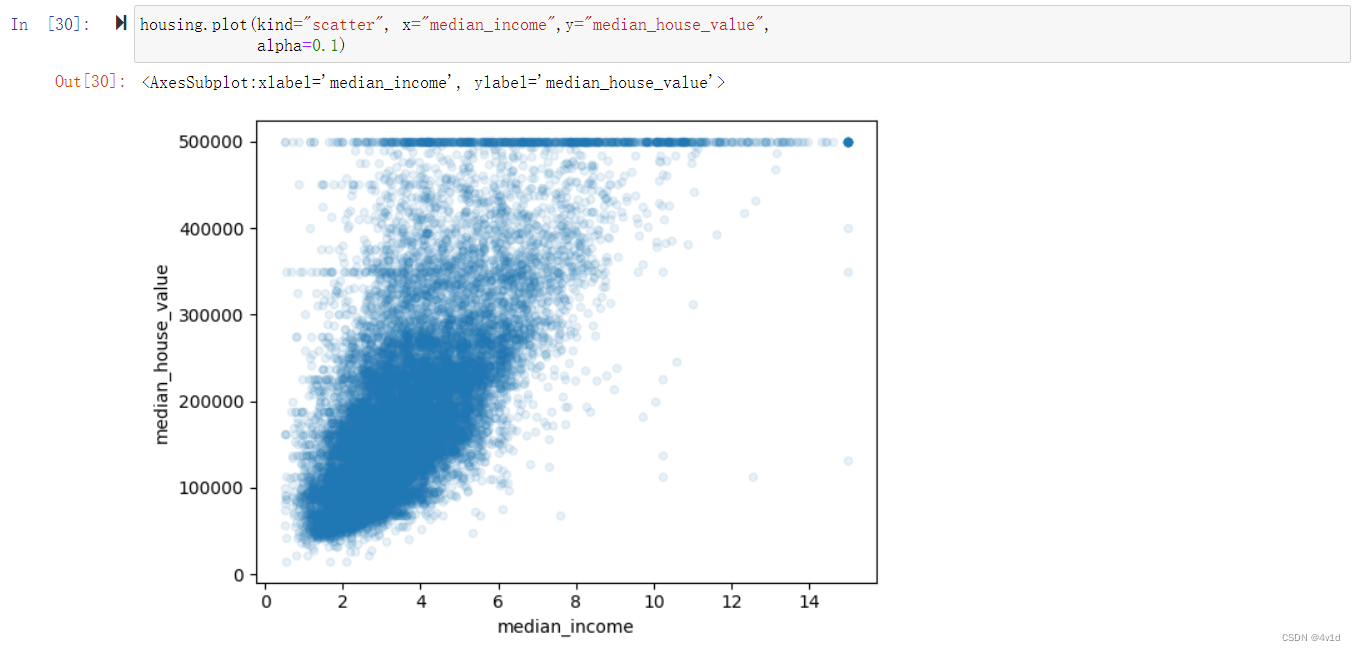
机器学习案例:加州房产价格(四)
参考链接:https://hands1ml.apachecn.org/2/#_12 数据探索和可视化、发现规律 通过之前的工作,你只是快速查看了数据,对要处理的数据有了整体了解,现在的目标是更深的探索数据。 首先,保证你将测试集放在了一旁,只是研究训练集。 另外,如果训练集非常大,你可能需要再采样一个探索集,保证操作方便快速。 在这个案例中,因为数据集很小,所以可以在全集上直接工作。创建一个
机器学习数据表示为阵列
机器学习数据表示为阵列。 在Python中,数据几乎被普遍表示为Numpy阵列。 可能会因访问数据的一些Pythonic方法(例如负索引和数组切片)感到困惑。 在本教程中,您将发现如何在Numpy阵列中正确操纵和访问数据。 完成本教程后,您将知道: 1 如何将列表数据转换为Numpy数组。 2 如何使用Pythonic索引和切片访问数据。 3 如何调整数据以满足某些机器学习API的期望。 教程概
机器学习概念:一些基本概念
目录 数据集 (Dataset):用于训练和评估模型的数据集合。 特征 (Feature):描述数据的属性或变量,用于训练模型。 标签 (Label):在监督学习中,与输入数据相关联的输出结果。 模型 (Model):对数据的某种假设或概括,用于进行预测或推断。 训练 (Training):使用数据集来调整模型参数以使其能够适应数据。 测试 (Testing):使用独立的数据集来评估模
使用 Python 和机器学习预测股票涨跌幅
使用 Tushare API 获取深圳股市历史数据 引言 这篇文章将会演示如何使用 Tushare Pro API 获取深圳股市的历史交易数据,并将数据保存到CSV文件中。Tushare 是一款提供实时和历史金融市场的数据服务,支持多种语言,具有丰富的数据源和强大的功能。 安装 Tushare 在开始之前,你需要先安装 Tushare 库。可以通过 pip 安装: pip insta
机器学习和数据挖掘在个性化推荐系统中的应用
个性化推荐系统出了满足用户的需求,也应兼顾信息提供者的利益,将他们的信息以最高的效率投放给对信息感兴趣的用户。 个性化推荐系统的算法都是来自于机器学习和数据挖掘,特殊之处在于对用户行为和用户心理的研究。 根据兴趣将用户聚类,也就是一种降维方法。机器学习的降维方法可以分为硬聚类和软聚类,硬聚类的代表算法是Kmeans和层次聚类,硬聚类的缺点是限制了用户兴趣只能属于一种类别,而在现实生
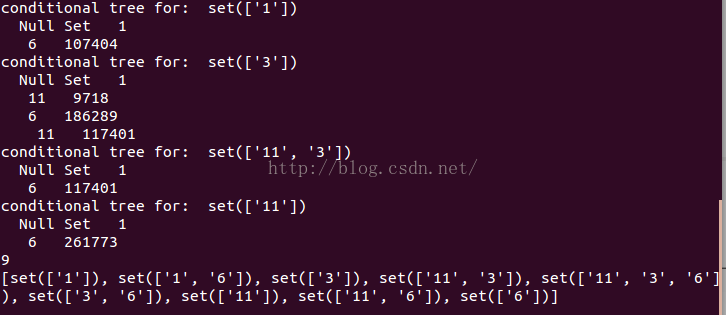
《机器学习实战》笔记之十二——使用FP-Growth算法来高效发现频繁项集
第十二章 使用FP-Growth算法来高效发现频繁项集 FP-growth算法,基于Apriori构建,但在完成相同任务时采用了不同的技术,其只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此其比Apriori算法快。FP算法需要将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对。 12.1 FP树:用于编