中文专题

solr4.3之配置中文分词IK
[size=x-large][b] 上一篇讲了使用solr4.3自带的smartcn进行中文分词,这一篇说一下,怎么使用IK进行分词, 在这之前先对中文分词的种类介绍一下,目前的中文分词主要有两种 1,基于中科院ICTCLAS的隐式马尔科夫hhmm算法的中文分词器,例如smartcn等。(不支持自定义扩展词库) 2,基于正向迭代最细粒度切分算法(正向最大匹配并且最细分词)例如IK,庖丁等(

solr4.3之配置中文分词smartcn
[b][size=x-large] solr4.3默认的分词器是一元分词器,这个本来就是对英文进行分词的,英文大部分就是典型的根据空格进行分词,而中文如果按照这个规则,那么显然是要有很多的冗余词被分出来,一些没有用的虚词,数词,都会被分出来,影响效率不说,关键是分词效果不好,所以可以利用solr的同步发行包smartcn进行中文切词,smartcn的分词准确率不错,但就是不能自己定义新的词库,不
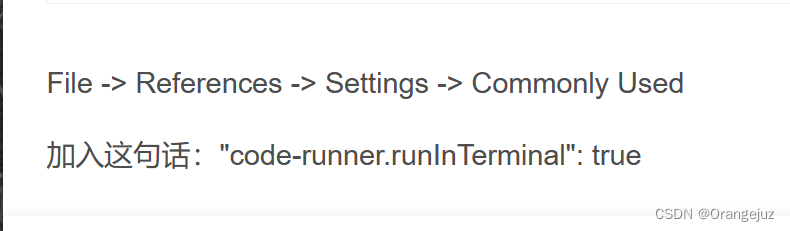
vscode 之 output 输出中文乱码,终端输出中文正常
# 1. 背景 因为没钱买正版的软件,所以转战 vscode 编译器。 在编译 python 文件时,发现直接右键 runner code,输出中文乱码。 但是在 teiminal 终端 执行py test.py 时,输出正常,中文正常。 output 输出中文样式(中文乱码) 终端输出样式(中文正常) 2. 【失败】尝试的解决办法 修改当前 vscode 的编码样式为 : GB

专业矢量绘图软件Sketch for mac v100中文激活版
Sketch for Mac 是一款专业的矢量图形设计工具,主要用于 UI/UX 设计、网页设计、图标设计等领域。它的界面简洁、易用,功能强大,可以帮助设计师快速创建高质量的设计作品。 Sketch for Mac 可以轻松地创建矢量图形、图标、网页布局、移动应用程序界面等设计元素。它的功能包括:创建形状、文本、颜色、渐变、图层样式、图标和标志、矢量和位图导入、自动布局等。 Sketch for

Java面试八股之一个char类型变量能不能存储一个中文字符
Java中一个char类型变量能不能存储一个中文字符?为什么? Java中一个char类型变量可以存储一个中文字符。原因如下: Unicode编码支持:Java语言采用Unicode字符集作为其内建字符编码方式。Unicode是一种广泛接受的字符编码标准,设计目标是容纳世界上所有书面语言的字符。它为每个字符分配一个唯一的编号,称为Unicode码点(code point),范围从U+0000到

java中含中文字符串的编码和解码问题。
1、在Java开发中经常被文字乱码的问题困扰。下面全面解释下字符串的编码和解码。 如 String str = "中国" 编码:byte[] bts = str.getBytes("编码方式");//常用编码方式 gbk、utf-8、gb2312、iso-8859-1等等。 解码:String b = new String(bts,"解码方式");//解码方式对应常用编码方式。 2、

cmd命令行下javac 编译 无法识别中文
使用命令行javac命令编译java文件, 提示错误:编码GBK的不可映射字符。 在编译的时候,如果我们没有用-encoding参数指定我们的JAVA源程序的编码格式,则javac.exe会获得我们操作系统默认采用的编码格式。 JDK根据操作系统的file.encoding参数(它保存的就是操作系统默认的编码格式,如WIN2k,它的值为GBK),把源程序从默认编码格式
springboot log打印日志时中文乱码,file.encoding=ANSI_X3.4-1968
springboot项目启动后,发现log中打印的日志有中文乱码问题,一开始以为是CentOS7没有安装中文字符集 [root@izbp15jhfolqh6oj1ahcu6z springboot]# localeLANG=zh_CN.UTF-8LC_CTYPE="zh_CN.UTF-8"LC_NUMERIC="zh_CN.UTF-8"LC_TIME="zh_CN.UTF-8"LC_C
MediaRecorder类介绍 方法已经翻译成中文了
转自http://blog.csdn.net/mark_dev/article/details/7249415 1 类得介绍... 2 2 嵌套、关联的类... 2 3 主要方法:... 3 4 流程分析... 8 一、 java层... 8 1、java应用层... 9 2、JAVAFramework层... 10 3、JAVA本地调用部分(JNI):... 10 二、 多
看到一篇关于eclipse导入项目,java文件中文乱码的解决方案,先mark下
转自http://blog.csdn.net/jasonzhou613/article/details/8753628 注:本文来自eclipse导入项目,java文件中文乱码的解决方案 [java] view plain copy /** * 建议在转换前先将代码备份 * * @date 2012-5-23 */ public class
cocos2dx3.0 中文支持显示
转自:http://www.58player.com/article-84994-1.html #ifndef _SUPPORT_TOOL_H_ 02 #define _SUPPORT_TOOL_H_ 03 // 04 #include "cocos2d.h" 05 06 07 //
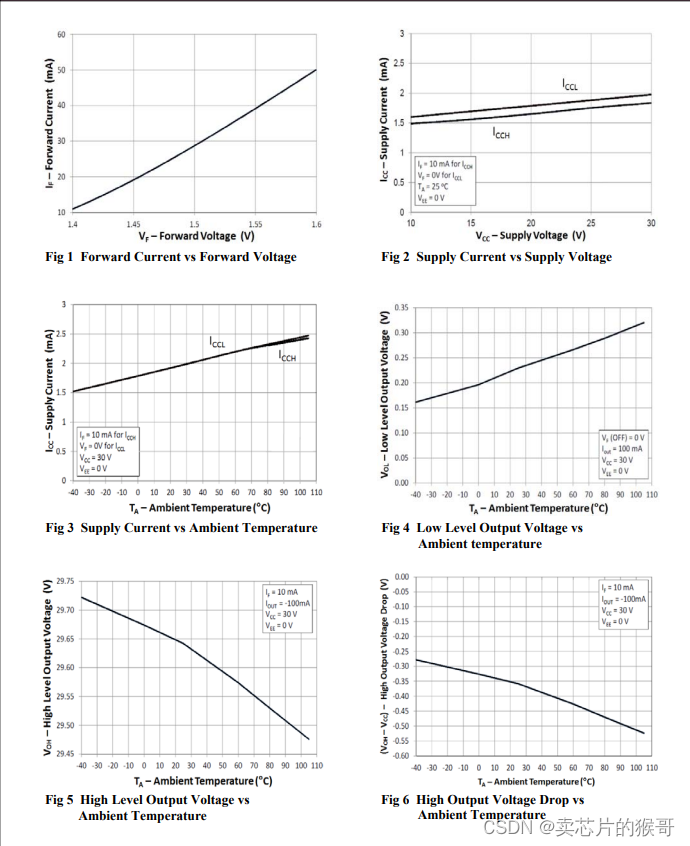
光耦 IS314W中文资料 IS314W引脚图及功能说明
IS314W是一款IGBT/MOSFET输出型光耦,由Isocom公司制造。它主要用于驱动用于电机控制和电源系统变频器的功率IGBT和MOSFET。以下是该产品的部分功能和参数: - 两个独立的光耦输出通道 - 轨对轨输出电压 - 最大峰值输出电流:1.0A - 最小峰值输出电流:0.8A - 共模抑制比(VCM=1500V时):20kV/μs - 最大传播延迟:200ns - 最大传播延迟差:

GoLand 支持中文设置方法
版本 GoLand版本:GoLand-2020.1.3 设置方法 GoLand 2020版本官方已经有中文语言包插件了,GoLand设置中文界面的方法有两种,分别是:在线安装和离线安装两种方式。下面分别介绍这两种中文设置方法。 方法1 - 在线安装 在线安装方法比较方便,推荐使用这种方法。 1、启动GoLand软件后,打开:文件-》设置-》插件。 2、在文本框输入:Chinese,就
头图的标题内容没有中文但无法显示
编译引擎问题: 确保你使用的编译引擎支持中文字符的显示。如果你在使用 XeLaTeX 或 LuaLaTeX 编译引擎,请确保你的文档中正确设置了中文字体,并且编译引擎能够正确识别和渲染中文字符。 字体设置问题: 如果你在文档中设置了中文字体,确保设置的中文字体包含了需要显示的字符。有时候可能会因为字体缺失或设置错误导致中文字符无法正确显示。 编译日志查看: 查看编译过程中生成的日志文件,查找
Respberry pi 安装中文输入法
Respberry pi 安装中文输入法 转自:http://www.linuxidc.com/Linux/2013-04/82805.htm 默认的raspbian操作系统是不带中文字库的,所以不能正常显示中文字体 我们可以用apt来安装开源字库的安装包 实现中文的显示 输入命令 sudo apt-get install ttf-wqy-zenhei 这条命令安装的是文泉驿的正黑体 s
JDK8中文文档——ServerSocket
JDK8中文文档由“毕设帮”翻译——“毕业设计在线求助平台” PS:毕设帮招募编程大神,为大四学生完成毕业设计,获取相应报酬,点击链接查看详情:毕设帮官网 类名 ServerSocket 所属包 java.net.ServerSocket 所有被实现的接口 Cloneable,AutoCloeable 直接父类 SSLServerSocket 类
MySQL 第三方客户端工具显示中文乱码
通过第三方工具连接数据库,表中的中文显示为乱码,但是通过 MySQL 的命令行工具却没有问题。 字符集相关变量设置: > SHOW VARIABLES LIKE '%character%'; Variable_name Value ------------------------ ---------------------------- character_set_client ut
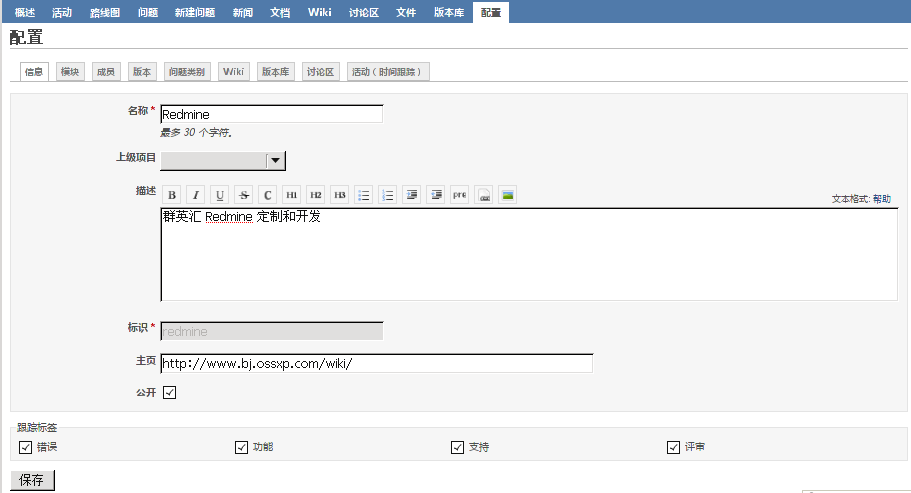
Redmine 中文用户使用手册
Redmine 中文用户手册 此文章是 基于Redmine 0.9 版本编写的 目前比较流行的管理工具大概都有:BugFree,Bugzilla,Redmine,Jira,TestLink,禅道等 BugFree和B

问题解决记录 | kettle中出现中文乱码
spoon.bat的启动文件中进行修改 if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms1024m" "-Xmx2048m" "-Dfile.encoding=UTF-8"
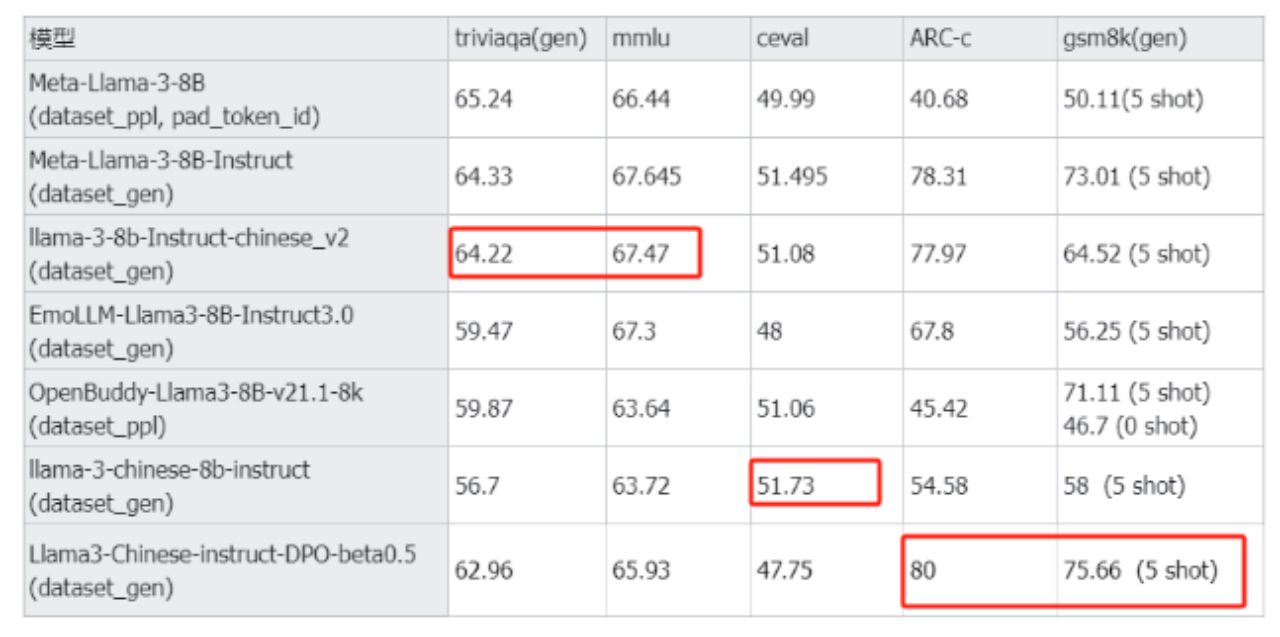
Llama3中文聊天项目全能资源库
Llama3 中文聊天项目综合资源库,集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文SFT版、Instruct偏好强化学习版、趣味版等。此外,还有Phi3模型中文资料仓库的链接,和性能超越了8b版本的Llama3。2. 部署与使
Java读取中文目录、文件
String jar_v4 = new String("D:\\Spring平台_V2\\10_fw_core\\target\\11_fw_core-1.0.16.jar".getBytes(), "UTF-8"); JarFile v4 = new JarFile(jar_v4 );

WordPress中文tag标签出现404解决方案
WordPress搭建的博客或网站常出现一个问题就是中文tag链接不存在,google管理员工具提示抓取404错误,特别是Windows主机常出现中文标签链接抓取错误,中文标签不能正常显示;或者中文标签能够正常显示,但是点击链接后即出现404错误,给用户带来非常大的不便,极大降低了网站的友好性。 该怎样解决这个问题呢? 第一种方法: 打开 WP-include/classes
ngram模型中文语料实验step by step(1)-分词与统计
ngram模型是统计语言的最基本的模型了,这里将给出用中文语料做实验建立ngram模型的个人总结,主要参考sun拼音2.0的代码以及有点意思拼音输入法,会参考srilmstevejian.cublog.cn。我会尽量逐步完成所有的实验总结。 分词与统计 对于中文语料和英文不同需要我们先进行分词,当然如果是切分好空格隔开的语料就简单许多。假设是普通的语料,sun拼音的做法是采用正向最大匹配分词

ngram模型中文语料实验step by step(2)-ngram模型数据结构表示及建立
n元ngram模型本质上就是trie树的结构 ,逐层状态转移。在sun拼音中是采用的是逐层按照顺序用vector表示,查找的时候逐层二分查找。sun拼音的建立ngram模型的方法也是以按照字典序排好序的<ngram元组,次数>序列作为输入建立起来的。 利用顺序存储+二分查找应该是最节省空间的了。但是效率要受一定影响。其余的trie树实现包括可以利用map(hash_map更耗费空间一点),su

redhat7中Codeblocks编译c程序乱码问题 中文乱码解决方法
1.修改源文件保存编码 settings->Editor->gernal settings 右边的Encoding group Box Use encoding when opening files: 这个表示打开文件用的格式,第一次保存文件的时候也会用这个格式。 As default encoding: 表示设置为文件缺省保存和打开编码格式 注意,要先设置好,然后保存文件,才有效。

Solr6+中文分词(mmseg4j)
在搭建Solr服务器的基础上(http://blog.csdn.net/u010379996/article/details/51790743) 1. 下载mmseg4j包和字典(.dic) 2. 搭建mmseg4j中文分词 在Solr_Home创建dic文件夹,并把mmseg4j的.dic文件复制到此 下载mmseg4j-solr-2.3.0.jar, mmseg4j-core-1.1