momentum专题

Mxnet (28): 动量(Momentum)
执行随机梯度下降时,面对噪声时选择学习速率需要格外注意。如果学习速率下降的太快,就会过早停止,如果下降的太慢,就会导致无法得到足够的收敛,以至于噪音使我们不但远离最有解。 1. 收敛与发散问题 通过一个例子说明问题: f ( x ) = 0.1 x 1 2 + 2 x 2 2 . f(\mathbf{x}) = 0.1 x_1^2 + 2 x_2^2. f(x)=0.1x12+2x22

论文解读:(MoCo)Momentum Contrast for Unsupervised Visual Representation Learning
文章汇总 参数的更新,指encoder q的参数,为encoder k,sampling,monentum encoder 的参数。 值得注意的是对于(b)、(c)这里反向传播只更新,的更新只依赖于。 对比学习如同查字典 考虑一个编码查询和一组编码样本是字典的键。假设字典中只有一个键(记为)与匹配。对比损失[29]是指当与它的正键相似,且与其他所有键不相似时(认
MTM(Momentum)动量指标及其发明人J. Welles Wilder的前世今生
J. Welles Wilder是谁? 这是个熟悉的名字,在上一篇《量化指标ATR(Average True Range真实波动幅度均值)及其发明人Welles Wilder的前世今生》,其中有介绍。 这个MTM指标也是这位老哥发明的(大约在1970年代末期),还是那本书。 MTM指标 MTM(Momentum),动量,就是考察证券价格变化的速度。 现在,基本但凡是从技术分析角度

talib.MOM动量(Momentum)指标MTM、MAMTM
动量指标是一个模糊概念,狭义指MTM指标(Momentum Indictor),广义1讲是基于动量的各类指标:MTM、MAMTM、CMO、RSI… 《MTM(Momentum)动量指标及其发明人J. Welles Wilder的前世今生》 做量化,一定听说过动量指标,也大概知道RSI之类的,然而,动量指标的具体定义及背景是什么呢? Momentum Momentom在物理学中翻译为“动

sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找 简单logistic分类中的 的应用
参考博文 (4条消息) sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找函数最值的应用_tcuuuqladvvmm454的博客-CSDN博客 在这里随机选择一些数据 生成两类 核心代码如下: def __init__(self, loss,

sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找函数最值的应用
1\sgd q=q-a*gt a是学习率 gt是函数的梯度 也就是沿着梯度的反方向得到下降最快的,最快能找到函数的最值 2 Momentum 然后q=q-mt 3 RMSprop 4 Adam Adam[6] 可以认为是 RMSprop 和 Momentum 的结合。和 RMSprop 对二阶动量使用指数移动平均类似,Adam 中对一阶动量也是用指

Adagrad求sqrt SGD Momentum Adagrad Adam AdamW RMSProp LAMB Lion 推导
随机梯度下降(Stochastic Gradient Descent)SGD 经典的梯度下降法每次对模型参数更新时,需要遍历所有的训练数据。随机梯度下降法用单个训练样本的损失来近似平均损失。 θ t + 1 = θ t − η g t ( 公式 1 ) \theta_{t+1} = \theta_{t}-\eta g_t (公式1) θt+1=θt−ηgt(公式1) 小批量梯度下降法(
深度模型中的优化(四)、动量(momentum)和Nesterov动量
参考 动量(momentum)和Nesterov动量 - 云+社区 - 腾讯云 一、动量 虽然随机梯度下降仍然是非常受欢迎的优化方法,但其学习过程有时会很慢。动量方法旨在加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。从形式上看,动量算法引入了变量v充当速度角色------它代表参数在参数空间移动的方向和速率。

【2024美赛】C题 Momentum in Tennis网球运动中的势头 25页中英文论文及Python代码
【2024美赛】C题 Momentum in Tennis网球运动中的势头 25页中文论文 1 题目 A题:2024MCM问题C:网球运动中的势头 在2023年温布尔登网球公开赛男子组决赛中,20岁的西班牙新星卡洛斯-阿尔卡拉斯击败了36岁的诺瓦克-德约科维奇。这是德约科维奇自2013年以来首次在温布尔登输掉比赛,也结束了这位大满贯历史上最伟大球员之一的辉煌战绩。 [1]德约科维奇似乎
【2024美赛】C题 Problem C: Momentum in Tennis网球运动中的势头26页完整论文
1 题目 引言 本人是计算机博士,拥有10年网球球龄,2023年的温网决赛,熬夜到半夜全称观看完了直播,对于网球规则、比赛的数据非常熟悉,这个题应该没有人比我更懂了。我们团队将会陆续更新问题分析、数学模型和实现代码,最后发布完整的论文。 更新进展: (1)2024年2月1日22:00发布博客 (2)2024年2月2日6:00发布题目 (3)2024年2月2日7:00发布问题分析 (4)20
【已更新】2024美赛C题代码教学思路数据处理数学建模分析Momentum in Tennis
问题一完整的代码已给出,预计2号晚上或者3号凌晨全部给出。 代码逻辑如下: C题第一问要求我们开发一个模型,捕捉得分时的比赛流程,并将其应用于一场或多场比赛。你的模型应该确定哪名球员在比赛的特定时间表现得更好,以及他们的表现有多好。那么换句话说,就是评价球员在比赛期间的一个实时的状态, 因此对于这个问题求解的关键在于如何从给出的数据中提取特征,而不是侧重于套用模型进行评价 在于我们需要根据提供的

【2024美赛】C题(中英文):网球中的势头Problem C: Momentum in Tennis
【2024美赛】C题(中英文):网球中的势头Problem C: Momentum in Tennis 写在最前面2024美赛翻译 —— 跳转链接 中文赛题问题C:网球中的势头使用数据来:提供的文件:词汇表关键术语/概念的词汇表: 参考文献: 英文赛题Problem C: Momentum in TennisUse the data to:Files provided:GlossaryGl

2024美赛C题网球运动势头Momentum in Tennis
赛题下载地址 https://www.immchallenge.org/mcm/index.html 比赛期间建议多关注一下官网,试题有可能性调整,调整后第一时间会在官网发布,还有模板可以下载 选题建议 个人认为试题难度排序:E<B=C=F<A=D 计算机背景的伙伴大概率会选C题,恰好有时间就简单分析了下C题 工具推荐 论文检索工具:谷歌学术、dplp、sci-hub 国内的镜像网站数

2024美赛MCM 问题 C 网球运动的动量(Momentum in Tennis)
2024 MCM Problem C: Momentum in Tennis In the 2023 Wimbledon Gentlemen’s final, 20-year-old Spanish rising star Carlos Alcaraz defeated 36-year-old Novak Djokovic. The loss was Djokovic’s first at W

关于梯度下降与Momentum通俗易懂的解释
sgd与momentum都是常见的梯度优化方法。本文想从代码方面对这两种方法进行总结。 关于理论。建议参考: https://www.cnblogs.com/jungel24/p/5682612.html 这篇博文写的很好。很形象。本文也是建立在它的基础上写的,同时代码参考: https://github.com/hsmyy/zhihuzhuanlan ?。交代完毕,开始学习之旅。 之前在学习无
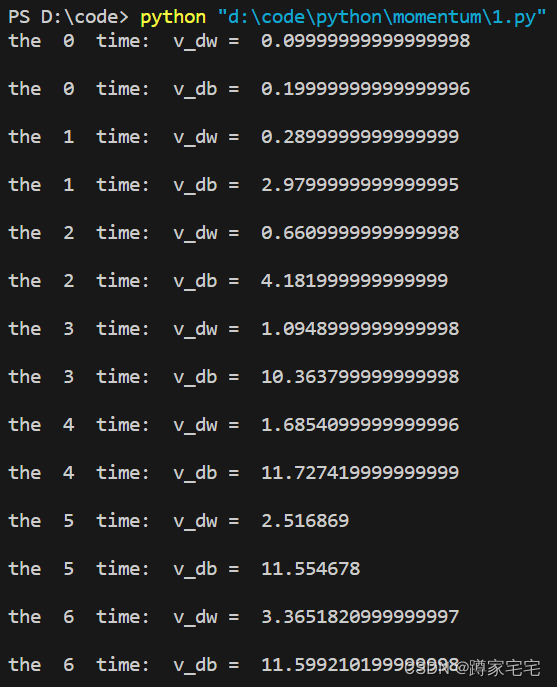
深度学习记录--Momentum gradient descent
Momentum gradient descent 正常的梯度下降无法使用更大的学习率,因为学习率过大可能导致偏离函数范围,这种上下波动导致学习率无法得到提高,速度因此减慢(下图蓝色曲线) 为了减小波动,同时加快速率,可以使用momentum梯度下降: 将指数加权平均运用到梯度下降,成为momentum梯度下降(图中红色曲线) 原理: 纵轴上,平均过程中正负数相互抵消,所以纵轴上的平
momentum超参数
momentum 是优化算法中的一个超参数,主要用于改善梯度下降的收敛性能,特别是在处理非凸优化问题时。它在随机梯度下降(Stochastic Gradient Descent, SGD)和其变种中经常被使用。 以下是动量的主要作用和原理: 加速收敛: 动量的引入旨在加速模型训练的收敛过程。它模拟了物体在运动过程中的动量,帮助模型在梯度更新时更快地前进。 克服局部极小值: 动量有助于克服梯
TA-Lib学习研究笔记(八)——Momentum Indicators 上
TA-Lib学习研究笔记(八)——Momentum Indicators 上 Momentum Indicators 动量指标,是最重要的股票分析指标,能够通过数据量化分析价格、成交量,预测股票走势和强度,大部分指标都在股票软件中提供。 1. ADX-Average Directional Movement Index 函数名:ADX 名称:平均趋向指数 简介:使用ADX指标,指标判断盘整、
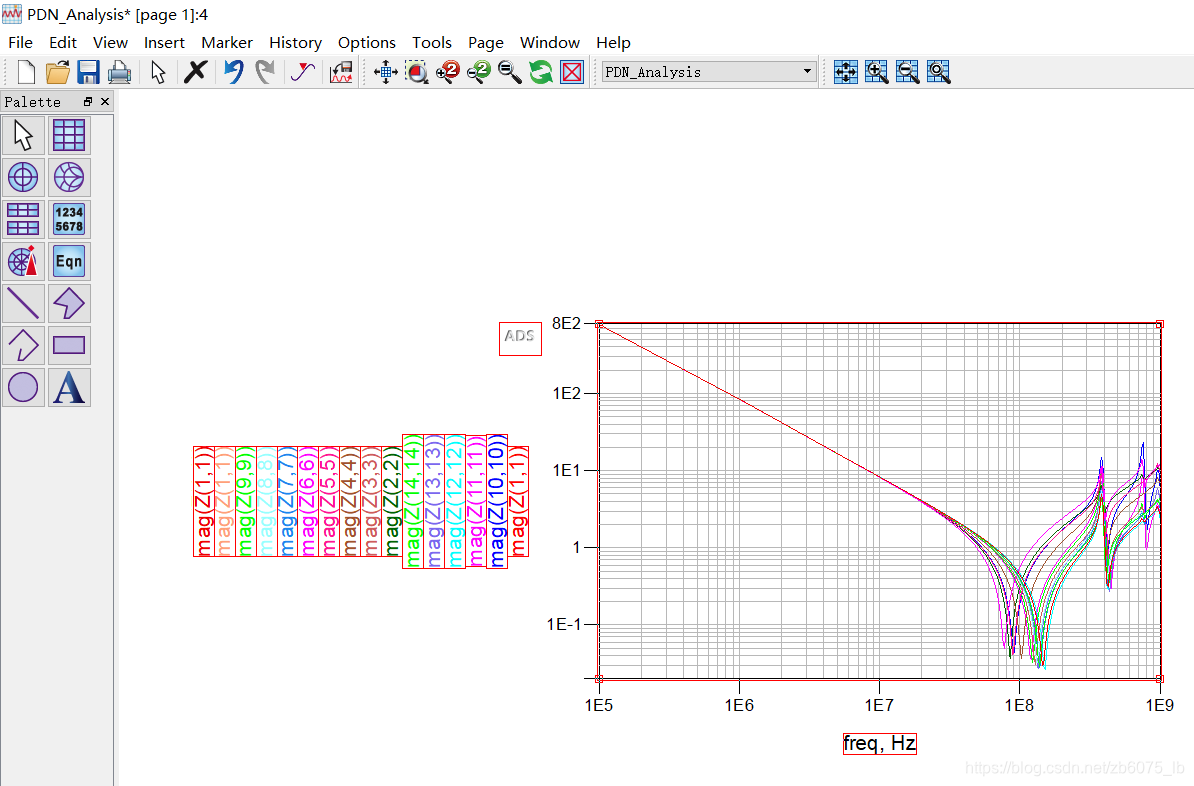
ADS中使用Momentum进行电源完整性分析示例
这个应用可以帮助工程师用更快的时间使用ADS Momentum完成PDN分析。该应用描述了利用ADS Momentum RF模拟器进行PDN分析的方法,大大缩短了计算时间。 该分析主要应用与高速数字设计。 在此应用中使用了以下ADS特性: ADS设计流程集成(ADFI)。电磁协同仿真。Momentum仿真。 仿真流程如下: 在Allegro中创建ADFI文件 要将Allegro
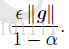
Deep Learning 最优化方法之Momentum(动量)
本文是Deep Learning 之 最优化方法系列文章的Momentum(动量)方法。主要参考Deep Learning 一书。 整个优化系列文章列表: Deep Learning 之 最优化方法 Deep Learning 最优化方法之SGD Deep Learning 最优化方法之Momentum(动量) Deep Learning 最优化方法之Nesterov(牛顿动量) Deep L
![[work] 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam](https://img-blog.csdn.net/20170806001149509?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMDA4OTQ0NA==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[work] 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
1. SGD Batch Gradient Descent 在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新: Θ=Θ−α⋅▿ΘJ(Θ)Θ=Θ−α⋅▽ΘJ(Θ) 优点: cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值 缺点
为什么Momentum可以加速训练?
文章目录 一、Momentum优化器二、Momentum加速训练原理 一、Momentum优化器 动量优化器(Momentum Optimizer)是一种优化算法,用于训练神经网络和其他机器学习模型。它通过引入动量的概念,改进了传统的梯度下降算法,加速参数更新过程,从而在训练过程中更快地收敛并避免陷入局部极小值。 动量优化器的原理如下: 动量项: 动量是一个介于0和1之

深度学习中所使用的优化方法综述,包括SGD,Adagrad,Momentum,Adadelta等
前言: 本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式可以去认真啃论文了。话不多说,直接上图!!! 本文转载自:https://zhuanlan.zhihu.com/p/22252270 SGD SGD英文全称为mini-batch gradient descent,关于batch gradient descent, stochastic gradi

Tensorflow入门教程(三十三)优化器算法简介(Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
# #作者:韦访 #博客:https://blog.csdn.net/rookie_wei #微信:1007895847 #添加微信的备注一下是CSDN的 #欢迎大家一起学习 # ------韦访 20181227 1、概述 上一讲中,我们发现,虽然都是梯度下降法,但是不同算法之间还是有区别的,所以,这一讲,我们就来看看它们有什么不同。 2、梯度下降常用的三种方法 为了博客的完整性,这里