inference专题

成功解决No module named ‘huggingface_hub.inference._text_generation‘
成功解决No module named 'huggingface_hub.inference._text_generation' 目录 解决问题 解决思路 解决方法 解决问题 No module named 'huggingface_hub.inferen

Secure Transformer Inference Made Non-interactive
目录 1.概述2.Attention2.1 Matrix multiplication (ciphertext-plaintext).2.2 Matrix multiplication (ciphertext-ciphertext)2.3 Placement of bootstrapping3.SIMD密文压缩和解压缩4.SIMD槽折叠5.实验结果 1.概述 我们提出了NEXUS

centernet笔记 - inference阶段后处理
预备知识,mxnet.ndarray的一些操作 shape_array shape_array([[1,2,3,4], [5,6,7,8]]) = [2,4] # 获取ndarry的shape# Returns a 1D int64 array containing the shape of data. split Splits an array along a particular

quantizing deep convolutional networks for efficient inference
标题: 量化深层卷积网络用于有效推理 摘要 本文综述了一种量化卷积神经网络的方法,用于整数权重和激活的推理。 采用每个通道权重量化和每层激活量化到8位精度方法, 会对网络模型测试精度下降2%左右. 优点是适用于各种CNN架构。通过将权重量化为8位,模型大小可以减少4倍. 即使不支持8位算法,也可以通过简单的训练后权重量化来实现。我们对CPU和DSP上网络量化产生的延迟进行基准测试,并观察到量
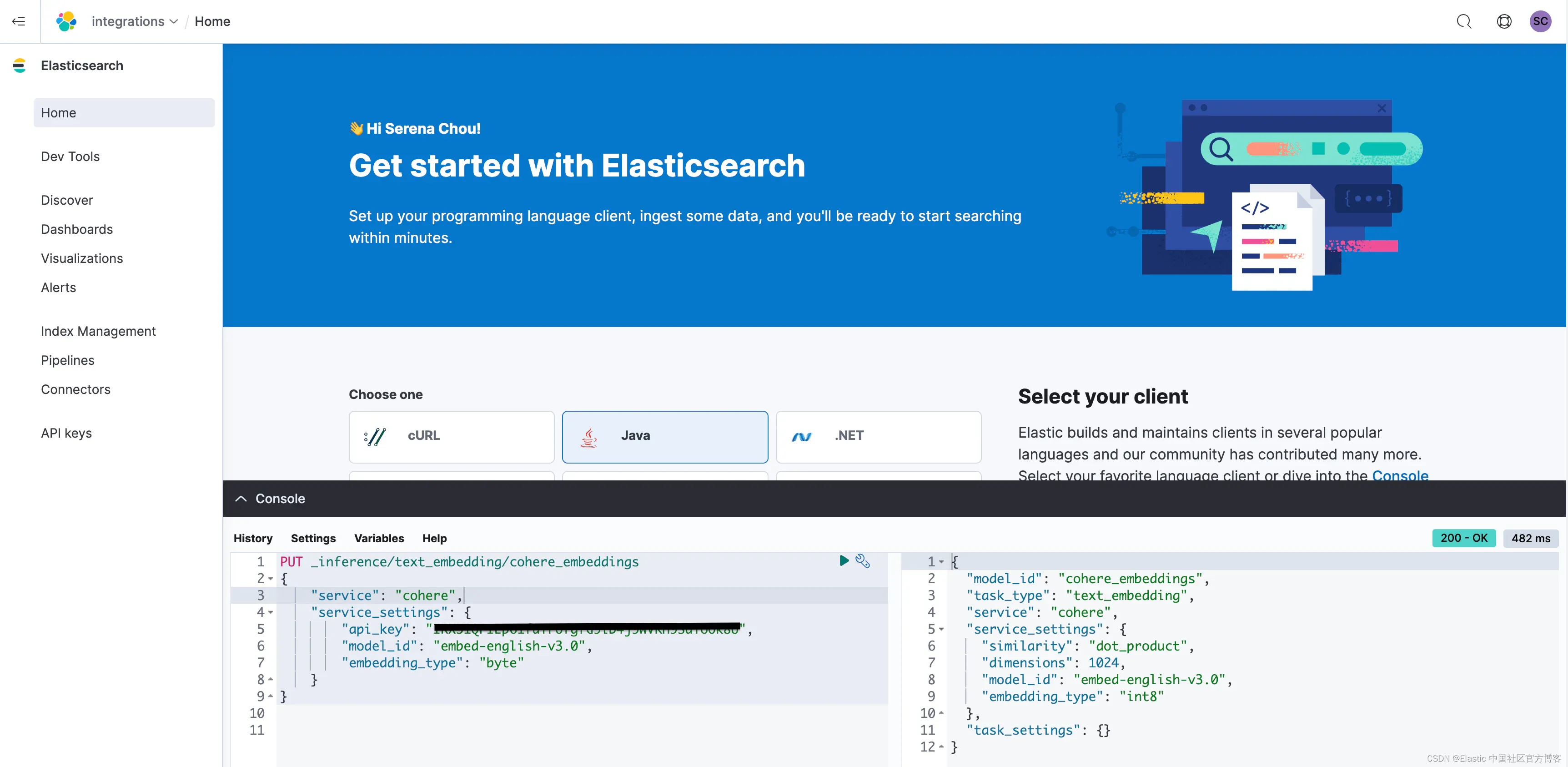
Elasticsearch 开放 inference API 增加了对 Cohere Embeddings 的支持
作者:来自 Elastic Serena Chou, Jonathan Buttner, Dave Kyle 我们很高兴地宣布 Elasticsearch 现在支持 Cohere 嵌入! 发布此功能是与 Cohere 团队合作的一次伟大旅程,未来还会有更多合作。 Cohere 是生成式 AI 领域令人兴奋的创新者,我们很自豪能够让开发人员使用 Cohere 令人难以置信。 Elastic
(Inference:7714): Gtk-ERROR **: 19:29:39.303: GTK+ 2.x symbols detected. Using GTK+ 2.x and GTK+ 3 i
未解决: (Inference:7714): Gtk-ERROR **: 19:29:39.303: GTK+ 2.x symbols detected. Using GTK+ 2.x and GTK+ 3 in the same process is not supported Trace/breakpoint trap (core dumped)

Towards Accurate Latency Prediction of Deep-Learning Model Inference on Diverse Edge Devices
nn-Meter: Towards Accurate Latency Prediction of Deep-Learning Model Inference on Diverse Edge Devices nn-Meter:精准预测深度学习模型在边缘设备上的推理延迟 nn-Meter:面向多样化边缘设备的深度学习模型精准延迟预测 深度模型端侧推理时间预测系统 nn-Meter Li Lyn
guidance快速配置流程-for LLM inference
conda create conda create -n guidance python=3.10 pytorch conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia pip install guidance guidance copy code pip transfor
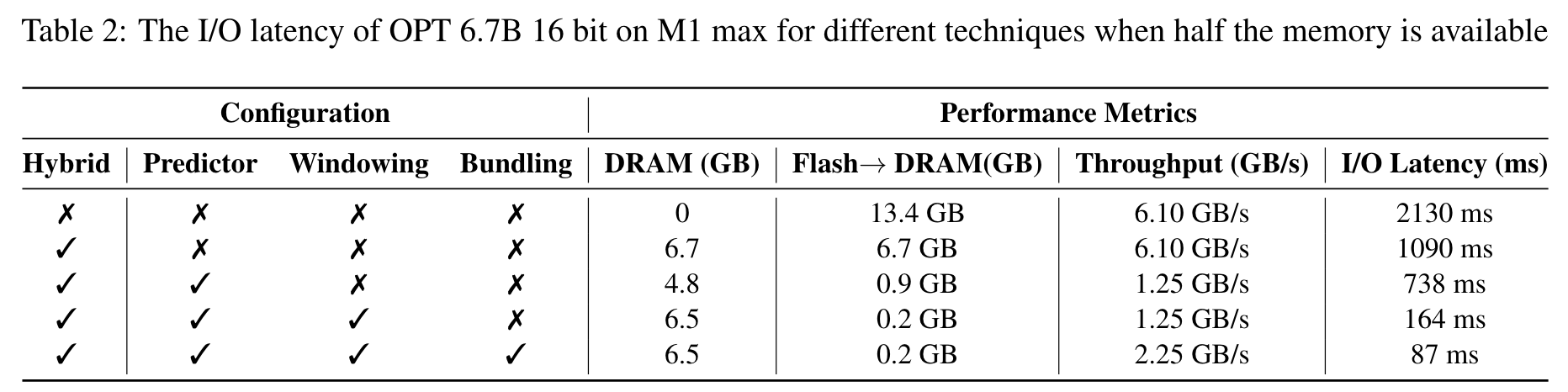
《LLM in a Flash: Efficient Large Language Model Inference with Limited Memory》论文解读
作者:Gary Li 时间:2024-1-9 (由于我不是研究大模型的,对AI也知之甚少,我主要关注存储相关的内容。并且本文并未正式发表有许多不规范和写作表达不清的地方,因此有许多我不理解的地方,也有许多我按照自己的理解记下的内容,如有错误请见谅。) 背景:大模型难以运行在内存受限的边端设备上(使用半浮点精度加载有7B参数的模型时需要约14GB内存)。当可用内存小于模型参数规模,会导致大量的

阅读文献:LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference 1.四个问题 要解决什么问题 在高速状态下,平衡图像分类方法的精度和效率 用什么方法解决 提出一种网络模型LeViT方法,在ViT模型基础上,引入卷积模块而不是学习类卷积特征的转换器组件,用特征金字塔替换Transformer中用以的结构(类似LeNet架
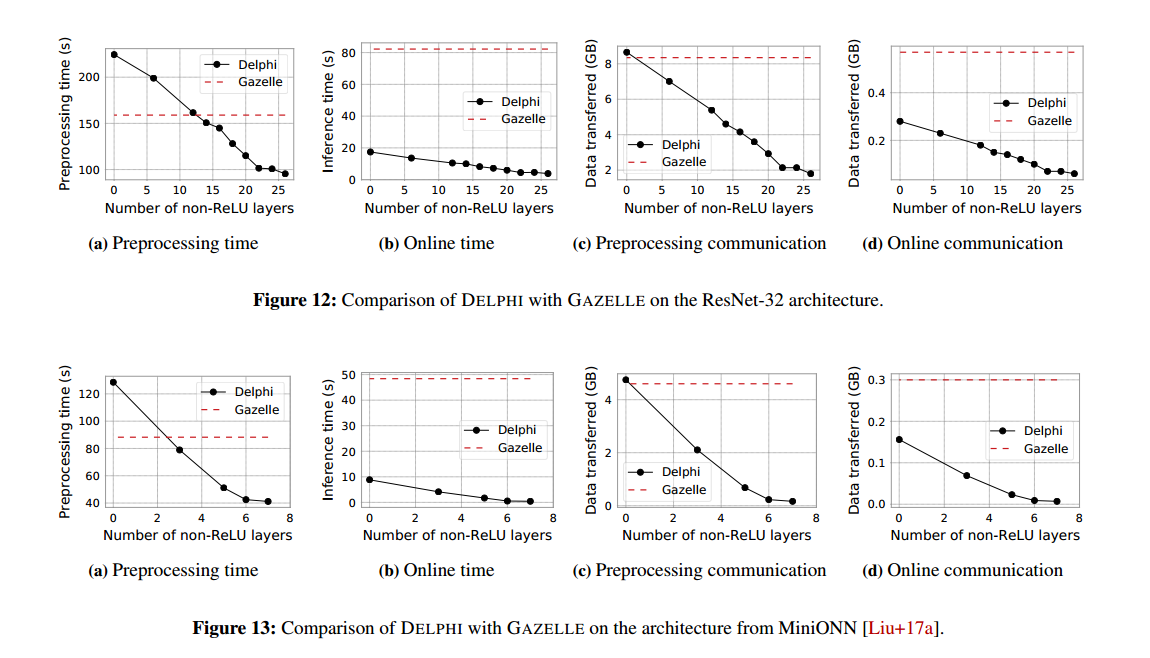
Delphi 论文阅读 Delphi: A Cryptographic Inference Service for Neural Networks
摘要 许多公司为用户提供神经网络预测服务,应用范围广泛。然而,目前的预测系统会损害一方的隐私:要么用户必须将敏感输入发送给服务提供商进行分类,要么服务提供商必须将其专有的神经网络存储在用户的设备上。前者损害了用户的个人隐私,而后者暴露了服务提供商的专有模式。 我们设计、实现并评估了DELPHI,这是一个安全的预测系统,允许双方在不泄露任何一方数据的情况下执行神经网络推理。DELPHI通过同时联
Object_Detection_API之Inference
导入包 import numpy as npimport osimport six.moves.urllib as urllibimport sysimport tarfileimport tensorflow as tfimport zipfilefrom distutils.version import StrictVersionfrom collections import

TensorFlow on Android(4): 输入数据预处理和Inference
Graph,Op, Tensor 在开始输入数据之前,我们先简单讲一下TensorFlow中的一些概念 一个 TensorFlow 的计算任务, 叫做Graph, 一个Graph由很多节点(Op)组成, Op通过Tensor获取输入,Op完成计算以后再通过Tensor把输出传递到下一个节点。 Tensor一般来说是一个数组(1维或多维),我们用Feed操作将一个Tensor的数据输入到一个O
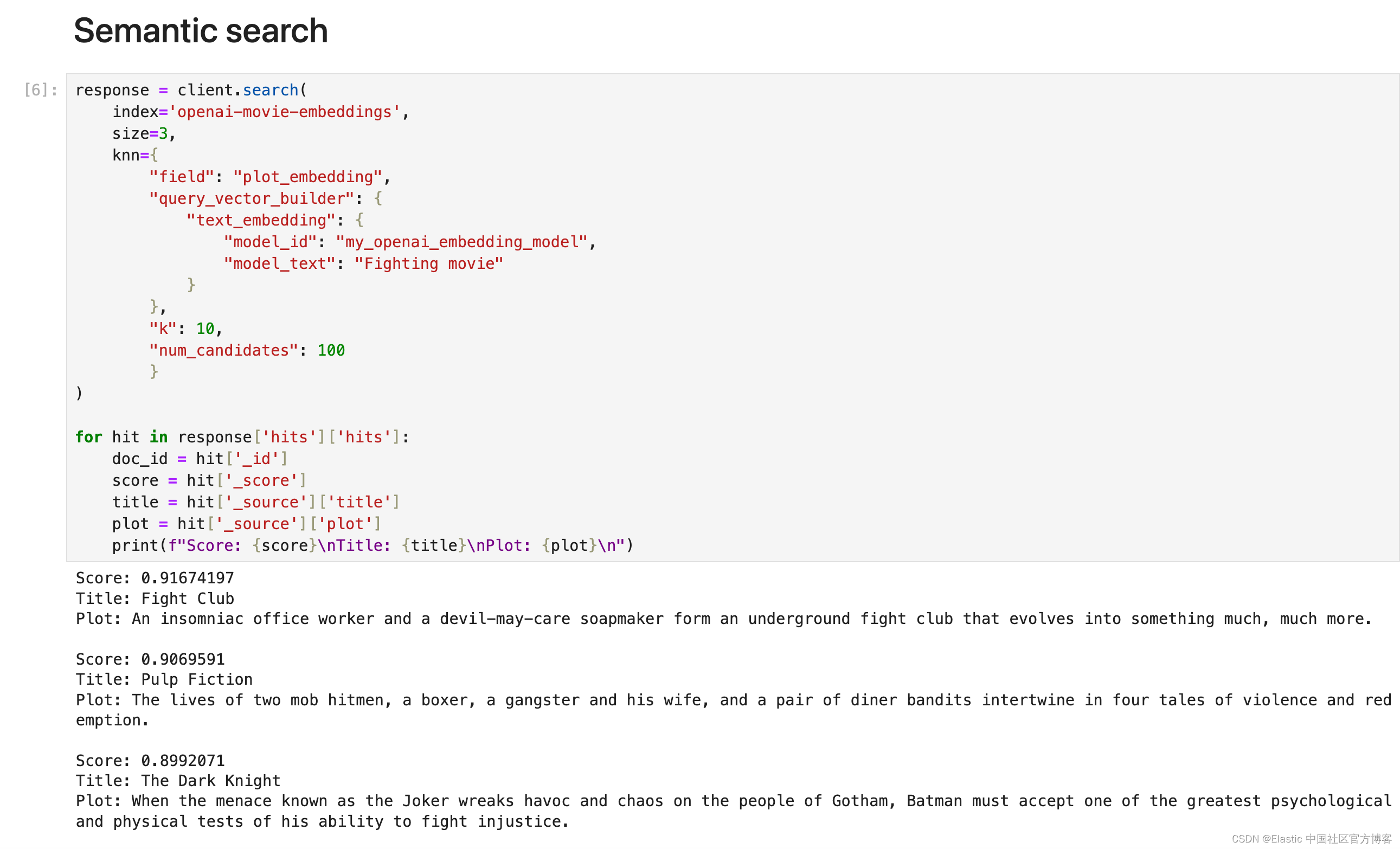
Elasticsearch:使用 Inference API 进行语义搜索
在我之前的文章 “Elastic Search 8.12:让 Lucene 更快,让开发人员更快”,我有提到 Inference API。这些功能的核心部分始终是灵活的第三方模型管理,使客户能够利用当今市场上下载最多的向量数据库及其选择的转换器模型。在今天的文章中,我们将使用一个例子来展示如何使用 Inference API 来进行语义搜索。 前提条件 你需要安装 Elastic

神经网络水印(文章解读Dataset Inference: Ownership Resolution in Machine Learning)
这篇发在ICPR上。介绍了一种数据集推理的方法(dataset inference)。实际上也是模型水印方法,但是却属于完全不同的大类。之前介绍的模型水印的方法,其实大概就两种,一种是白盒,包括在训练的时候直接加入惩罚项使得最终模型参数变成一个特定的“形状”,或者是在顶会上发了很多次的passport layers。在验证阶段需要打开模型,计算参数向量与特定的向量之间的距离。这样的验证是比较难实现
【论文阅读】Membership Inference Attacks Against Machine Learning Models
基于confidence vector的MIA Machine Learning as a Service简单介绍什么是Membership Inference Attacks(MIA)攻击实现过程DatasetShadow trainingTrain attack model Machine Learning as a Service简单介绍 机器学习即服务(Machine
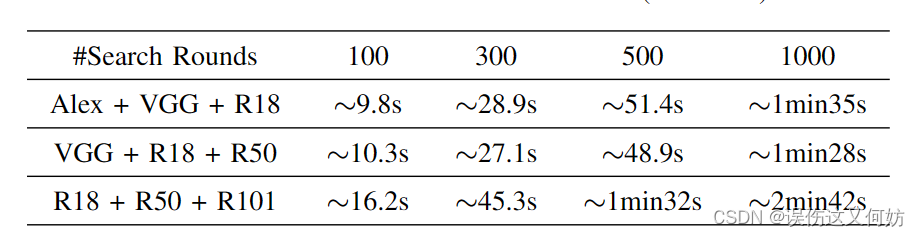
【论文阅读】Automated Runtime-Aware Scheduling for Multi-Tenant DNN Inference on GPU
该论文发布在 ICCAD’21 会议。该会议是EDA领域的顶级会议。 基本信息 AuthorHardwareProblemPerspectiveAlgorithm/StrategyImprovment/AchievementFuxun YuGPUResource under-utilization ContentionSW SchedulingOperator-level scheduling

triton inference server翻译之Metrics
link Metrics Triton Inference服务器提供Prometheus度量标准,指示GPU和请求统计信息。 默认情况下,这些指标可从http://localhost:8002/metrics获得。 度量标准仅可通过访问端点来使用,而不会推送或发布到任何远程服务器。 推理服务器的--allow-metrics=false选项可用于禁用度量标准报告,而--metrics-por
triton inference server翻译之Model Repository
link Triton Inference Server访问模型文件的方式可以是本地可访问文件路径,Google Cloud Storage和Amazon S3,用–model-repository选项启动服务器时,将指定这些路径。 对于本地可访问的文件系统,必须指定绝对路径,例如--model-repository=/path/to/model/repository;对于驻留在Google
triton inference server翻译之Quickstart
link Quickstart Triton Inference Server两种获取途径: NVIDIA GPU Cloud (NGC),预编译好的container;GitHub上源码,可用cmake自行编译container; Run Triton Inference Server 运行server $ nvidia-docker run --rm --shm-size=1g -
triton inference server翻译之user guide
link NVIDIA Triton Inference Server提供了针对NVIDIA GPU优化的云推理解决方案。 服务器通过HTTP或GRPC端点提供推理服务,从而允许远程客户端为服务器管理的任何模型请求推理。 对于边缘部署,Triton Server也可以作为带有API的共享库使用,该API允许将服务器的全部功能直接包含在应用程序中。 最新版是1.13.0 更新KFserving

triton inference server翻译之Models And Schedulers
link 通过整合多个框架和自定义后端,Triton Inference Server支持多种模型。 同时,推理服务器还支持多种调度和批处理配置,从而进一步扩展了推理服务器可以处理的模型类别。 本节描述模型的无状态,有状态和组合模式,以及推理服务器如何提供调度程序以支持那些模型类型。 Stateless Models 对于推理服务器的调度程序,无状态模型(或无状态自定义后端)不会维持推理请

triton inference server翻译之Model Configuration
link Model Configuration 模型库中的每个模型都必须包括一个模型配置,该配置提供有关该模型的必需和可选信息。 通常,此配置在指定为ModelConfig protobuf的config.pbtxt文件中提供。 在某些情况下,如生成的模型配置中所述,模型配置可以由推理服务器自动生成,因此不需要显式提供。 最小的模型配置必须指定name, platform, max_bat
triton inference server翻译之Optimization
link Optimization Triton Inference Server具有许多功能,可用于减少模型的延迟和增加吞吐量。 本节讨论了这些功能并演示了如何使用它们来改善模型的性能。 作为先决条件,您应该遵循快速入门,以使服务器和客户端示例与示例模型存储库一起运行。 除非您已经拥有一个适合在推论服务器上测量模型性能的客户端应用程序,否则您应该熟悉perf_client。 perf_cl
triton inference server翻译之model managment
link Model Management 推理服务器以以下三种模型控制模式之一进行操作:NONE,POLL或EXPLICIT。 Model Control Mode NONE 服务器尝试在启动时加载模型存储库中的所有模型。 服务器无法加载的模型在服务器状态中将标记为UNAVAILABLE,并且不可用于推理。 服务器运行时对模型存储库的更改将被忽略。 使用模型控制API的模型控制请求将不