本文主要是介绍Linux下Hadoop的安装(单机版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.安装前准备
1.1创建hadoop用户
首先创建hadoop用户组和用户,如果对linux命令不熟悉,可以参考http://blog.csdn.net/huhui_bj/article/details/8878701中的命令。
sudo addgroup hadoop #添加hadoop用户组
sudo adduser --ingroup hadoop hduser #在hadoop用户组中添加hduser1.2下载hadoop安装程序
我所用的是hadoop1.0.4,也是目前比较稳定的版本,下载地址:http://download.csdn.net/detail/huhui_bj/6028891
下载完之后,把文件放在hadoop用户目录的software目录下,然后用tar命令解压缩(请确保是用hadoop用户解压缩,否则需要改变文件夹的用户和用户组):
- tar -zxvf hadoop-1.0.4.tar.gz

1.3安装ssh
请确保你的Linux系统中已经安装了ssh软件,一般的Linux发行版都已经在安装完操作系统之后自带ssh软件。如果没有,执行以下命令安装:
请确保你的Linux中已经安装了rsync,不然,请执行以下命令安装:
- ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
- cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第一步,在https://launchpad.net/ubuntu/lucid/i386/openssh-client/1:5.3p1-3ubuntu3
下载文件并安装:$ sudo dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
第二步,在https://launchpad.net/ubuntu/lucid/i386/openssh-server/1:5.3p1-3ubuntu3
下载文件并安装:$ sudo dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
第三步,在https://launchpad.net/ubuntu/lucid/i386/ssh/1:5.3p1-3ubuntu3
下载文件并安装:$ sudo dpkg -i ssh_5.3p1-3ubuntu3_all.deb
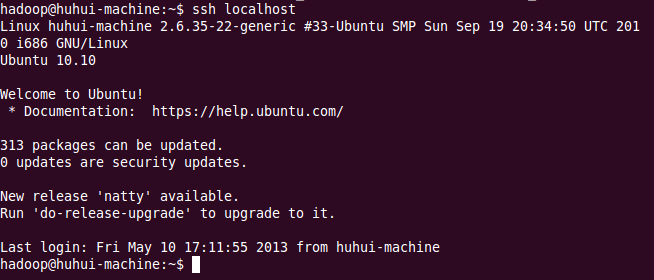
验证ssh免登录是否配置成功:
- ssh localhost
方法二:
- #生成公钥和私钥
- ssh-keygen -q -t rsa -N "" -f ~/.ssh/id_rsa
- cd .ssh
- cat id_rsa.pub > authorized_keys
- chmod go-wx authorized_keys
出现如下信息,则说明ssh免登录配置成功:
1.6安装并配置JDK
JDK的安装和配置,请参考博文http://blog.csdn.net/huhui_bj/article/details/8596388中关于JDK的安装说明。
2.安装并配置单机版Hadoop
2.1修改hadoop-env.sh
在hadoop目录下的conf目录下,找到hadoop-env.sh文件(针对hadoop-2.2.0版本,在hadoop-2.2.0/etc/hadoop/目录下),将JAVA_HOME配置进去(这里默认是使用的$JAVA_HOME,$JAVA_HOME已定义但是因为新建的用户无法识别,需要修改为固定目录):
- vi conf/hadoop-env.sh
- JAVA_HOME=/home/hadoop/software/jdk1.6.0_21
2.2修改hadoop的核心配置文件core-site.xml(针对hadoop-2.2.0版本,在hadoop-2.2.0/etc/hadoop/目录下),配置HDFS的地址和端口号
- vi conf/core-site.xml
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
2.3修改hadoop中HDFS的配置(针对hadoop-2.2.0版本,在hadoop-2.2.0/etc/hadoop/目录下)
- vi conf/hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
2.4修改hadoop中MapReduce的配置文件(针对hadoop-2.2.0版本,在hadoop-2.2.0/etc/hadoop/目录下),配置的是JobTracker的地址和端口
- vi conf/mapred-site.xml
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
以上就是单机版Hadoop的最小化配置
2.5格式化一个新的分布式文件系统
- bin/start-all.sh
3.验证Hadoop是否安装成功
- HDFS的web页面: - http://localhost:50070/
- MapReduce的web页面: - http://localhost:50030/
如果这两个页面能打开,说明你的hadoop已经安装成功了。
3.1运行WordCount例子
在HDFS的根目录下创建input文件夹(bin目录下执行):
- ./hadoop fs -mkdir /input
将start-all.sh文件放入hadoop的文件系统input目录下 :
- ./hadoop fs -put start-all.sh /input
- bin/hadoop jar hadoop-examples-1.0.4.jar wordcount /input /output
这篇关于Linux下Hadoop的安装(单机版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!