本文主要是介绍网易传媒数据指标体系建设实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是指标体系?为什么建设指标体系?如何使用OSM模型和AARRR模型搭建指标体系?本文将为大家带来网易传媒数据指标体系建设的实践分享。
1
什么是指标体系?
百度百科的定义:指标体系是指由若干个反映社会经济现象总体数量特征的相对独立又相互联系的统计指标所组成的有机整体。
通俗讲,指标体系是将零散单点的具有相互联系的指标,系统化的组织起来,通过单点看全局,通过全局解决单点的问题。完整的指标体系是由指标和维度组成的。
指标
指将业务单元细分后量化的度量值,它使得业务目标可描述、可度量、可拆解,它是业务和数据的结合,是统计的基础,也是量化效果的重要依据,一般通过对某个字段的某种计算得到(比如求和、均值等)。
维度
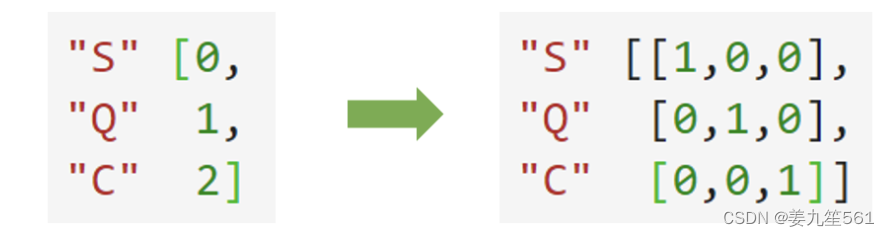
其实是指把指标按什么角度拆分来看,这个角度用的字段就是维度(比如按照平台,内容类型,性别等),维度可以理解为我们看问题的角度。
一个好的指标体系
能准确快速的下结论,能定义业务运作好坏的结论;
能满足多数场景的归因,即使出现异动,也能快速定位原因。
2
为什么建设指标体系?
现阶段互联网发展已经进入精细化运营时代,精细化运营则要求产品能拥有完整、准确且有效的数据。因此为自己的产品搭建一套数据指标体系,对于促进产品和业务增长是至关重要的。
指标能够量化的衡量业务的好坏,评价业务当前情况,为业务的发展提供有效的指引,同时能使团队成员建立共同的目标并为之努力。
3
如何搭建指标体系?
3.1 北极星指标法
北极星指标也叫唯一关键指标(OMTM,One metric that matters),产品现阶段最关键的指标。其实简单说来就是公司制定的发展目标,不同阶段会有不同的目标。为什么叫“北极星”指标,其实大概的寓意就是要像北极星一样指引公司前进的方向,目标制定最好是能符合SMART原则。
3.2 OSM模型
OSM模型是三个词缩写:目标(Objective)、策略(Strategy)、度量(Measurement)。
它是一套业务分析框架,并非算法模型,适用于目标已经清晰、行动方向已经明确的情况。

以网易新闻业务为例:
O:结合北极星指标法,首先确定公司级的目标,DAU增长。接下来运行OSM模型可以把宏大的目标拆解,对应到部门内各个小组具体的、可落地、可度量的行为上,从保证执行计划没有偏离大方向。
S:DAU增长,可以做哪些策略呢?
提高新用户规模
提高留存用户规模
提高回流用户规模
M:用什么来评价策略是否达成?
新用户数
留存用户数
回流用户数
这只是做了第一级拆解,我们还可以把评价的度量再做成目标,继续拆解。
O:新增用户数
S:新用户数增长,可以做哪些策略?比如站外渠道引流、老用户拉新等
M:评价指标是渠道新增用户数、老用户拉新人数。
通过一级一级的拆解,这样就形成了指标体系。

3.3 AARRR模型
麦克卢尔将创业公司最需要关注的指标分为五大类:获取用户(Acquisition)、提高活跃(Activation)、提高留存率(Retention)、获取营收(Revenue)和自传播(Referral),简称AARRR。每个环节都有这个环节应该关注的指标,这些环节并不一定遵循严格的先后顺序。
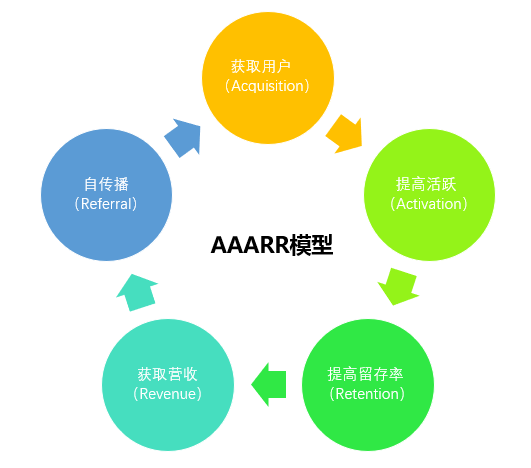
以新闻业务为例:

在实际运用中,会多种模型相结合,毕竟适合的才是最好的。
4
网易传媒数仓体系架构
网易传媒大数据建设方法论:从业务架构设计到模型设计,从数据研发到数据服务,做到数据可管理、可追溯、可规避重复建设。杭研把这套方法论沉淀为产品,网易有数大数据平台(模型设计中心、指标系统、数据地图、离线开发、自助分析、质量管理、资产管理等),方便各角色的同事使用。

4.1 业务线
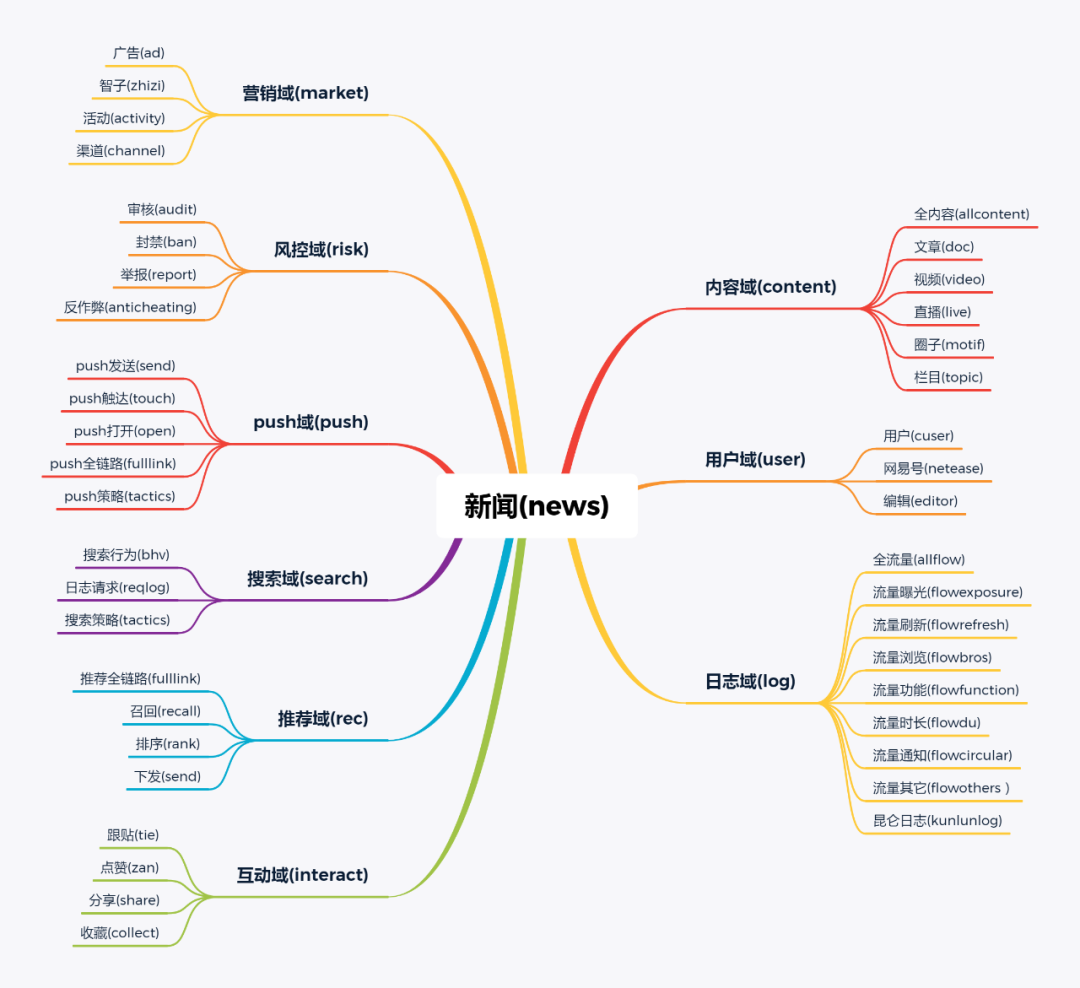
传媒业务线包括新闻、公开课、红彩等。新闻主题域如下图:
4.2 规范定义
概念:以维度建模作为理论基础,构建总线矩阵,定义业务域、数据域、业务过程、度量/原子指标、维度、维度属性、修饰词、修饰类型、时间周期、派生指标等。
业务域:比数据域更高维度的业务划分方法,适用于特别庞大的业务系统,且业务板块之间的指标或业务重叠性较小。例如传媒业务可以分为新闻、公开课、红彩等业务板块。新闻业务板块包含内容、用户、智子、PUSH、搜索、推荐等。
业务过程:业务过程可以概括为一个个不可拆分的行为事件,如曝光,点击,浏览等业务过程/事件。这里的事件跟埋点的事件类似。
看到这一系列的名词,很多人可能就开始懵逼了,业务域倒还能理解,简单来说就是对不同业务的分类;业务过程也容易理解,相当于画业务流程图呗。
那数据域又是何方神圣?
数据域,是联系较为紧密的数据主题的集合,是对业务对象高度概括的概念层归类,目的是便于数据管理与应用。简而言之,数据域就类似于我们电脑桌面要建立不同的文件夹来存储数据,这些个文件夹名就是数据域。
维度、维度属性、修饰这些怎么理解?有什么用途?
维度:是度量的环境,用来反映业务的一类属性,这类属性的集合构成一个维度,可以从who-where-when-what层面来看。
维度属性:维度属性隶属于维度,相当于维度的具体说明,如用户维度中性别为男、女。
修饰词:指除了统计维度以外指标的业务场景。
修饰类型:对修饰词的抽象划分。
敲黑板!!!
修饰词和维度可以理解为原子指标的一些限定条件,懂sql的会更好理解一些,一般是写sql时,放在where语句后边的就是修饰词,放在group by后面的就是维度。
指标类型:包含原子指标、派生指标、复合指标。
度量/原子指标:原子指标和度量含义相同,某一业务行为事件下的度量,是业务定义中不可拆分的指标,如推荐量、搜索次数。
时间周期:用来明确数据统计的时间范围或是时间点,如最近7天、自然月、截至当日等。
派生指标
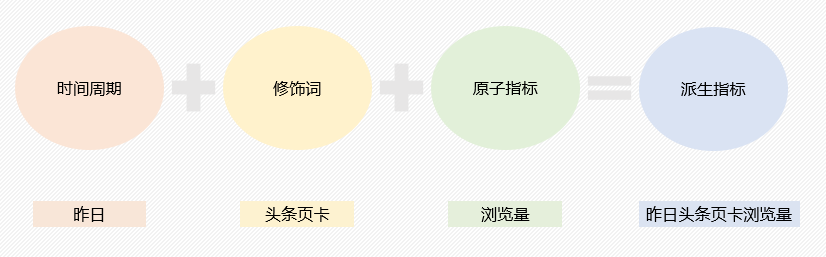
派生指标分为事务型指标、存量型指标
事务型:指标是指对业务活动进行衡量的指标,一般会对应一个事件。例如新增用户数
存量型:指标是指对实体对象某些状态的统计,例如文章总数、用户总数,这类指标需维护原子指标及修饰词,在此基础上创建派生指标,对应的时间周期一般为“历史截至当前某时间”。
复合指标:建立在原子指标、派生指标之上,通过一定运算规则形成的计算指标集合,如CTR,次均浏览时长等。
4.3 模型设计
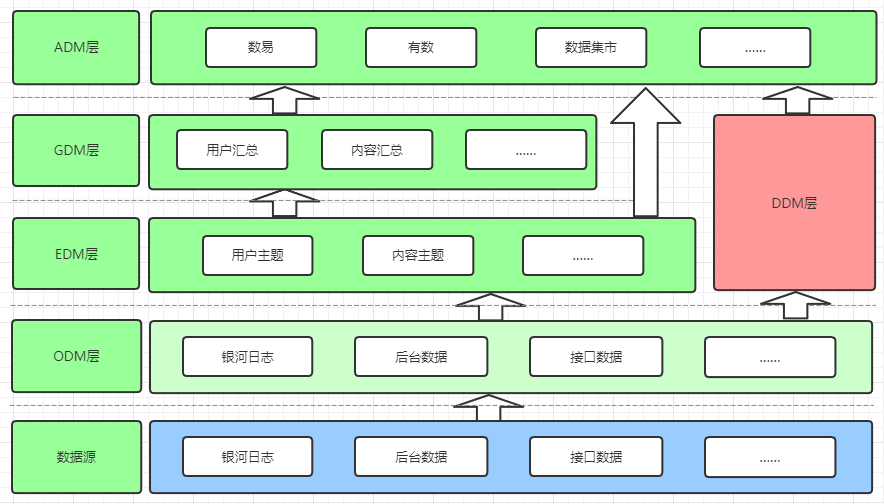
(1)模型层次
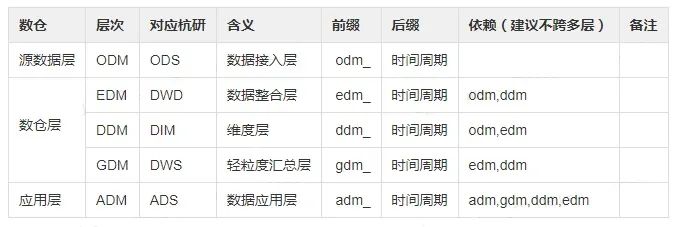
(2)表命名
ods(odm)层
数据表名:odm_{业务线}_{数据源}_{库名}_{表名}_{增量(incr)/全量(full)}_{更新时间频次}
例子:
1)mysql:odm_{业务线}_mysql_{db_name}_{mysql_table_name}_incr_day
2)hbase:odm_{业务线}_hbase_{db_name}_{hbase_table_name}_incr_day
3)kafka:odm_{业务线}_kafka_{cluster_name}_{topic_name}_incr_day
4)redis:odm_{业务线}_redis_{cluster_name}_incr_day
5)kudu:odm_{业务线}_kudu_{db_name}_{kudu_table_name}_incr_day
dwd(edm)层
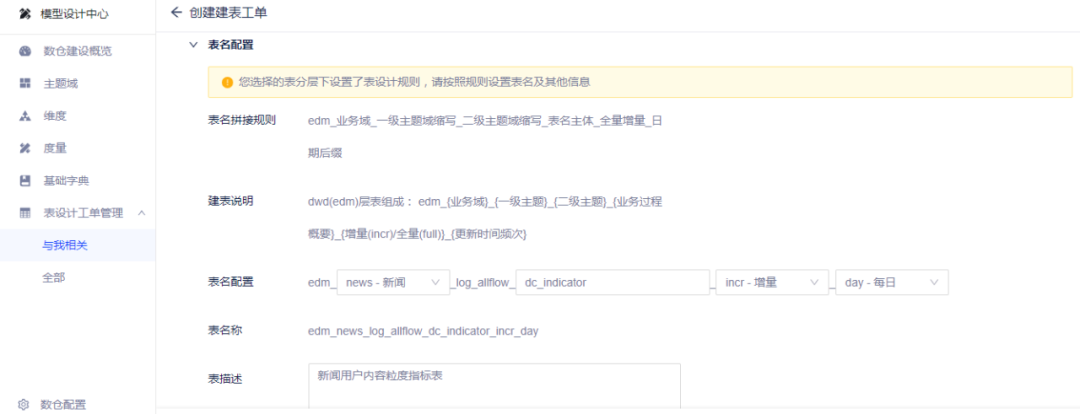
数据表名:edm_{业务域}_{一级主题}_{二级主题}_{业务过程概要}_{增量(incr)/全量(full)}_{更新时间频次}
例子:
edm_news_content_operation_bros_detail_incr_day:新闻业务,内容主题,内容运营每日增量入池内容头条阅读表
dws(gdm)层
数据表名:gdm_{业务域}_{一级主题}_{二级主题}_{业务过程概要}_{增量(incr)/全量(full)}_{更新时间频次}
app(adm)层
数据表名:adm_{业务域}_{功能域}_{统计描述}_{更新时间频次}
例子:
adm_news_zhizi_second_bid_ad_report_day:新闻业务,按天增量统计的智子二期竞价广告侧报表
dim(ddm)层
数据表名:ddm_{业务域}_{主题}_{实体}_{增量(incr)/全量(full)}_{更新时间频次}
例子:
ddm_content_doc_full_day:文章信息天级全量表
5
网易传媒数仓指标体系建设
之前,业务方经常出现不同表里的指标对不上的情况,开发查询半天发现,两个指标口径是不一样的,一个是整体的浏览量,一个是去掉异常数据的浏览量;分析师经常会问,表里的浏览时长是毫秒还是秒?每每遇到这种问题,开发都要去代码里看看,是除了1000还是没有;原来的指标都是写到WIKI里,当指标口径发生变化时,无法及时更新,就算更新了也无法在表里体现出来......
自从用了网易有数大数据平台的指标系统和模型设计中心,这些情况少多了。下面介绍一下网易传媒数仓在大数据平台上的应用。
5.1 准备工作
(1)主题域配置
前面我们已经根据业务线拆分了主题域,现在要把他配置到模型设计中心中,如图:

(2)分层配置
(3)字典集配置

(4)表设计规则管理
根据我们确定的表命名规范,录入系统
5.2 维度建设
(1)查找维度
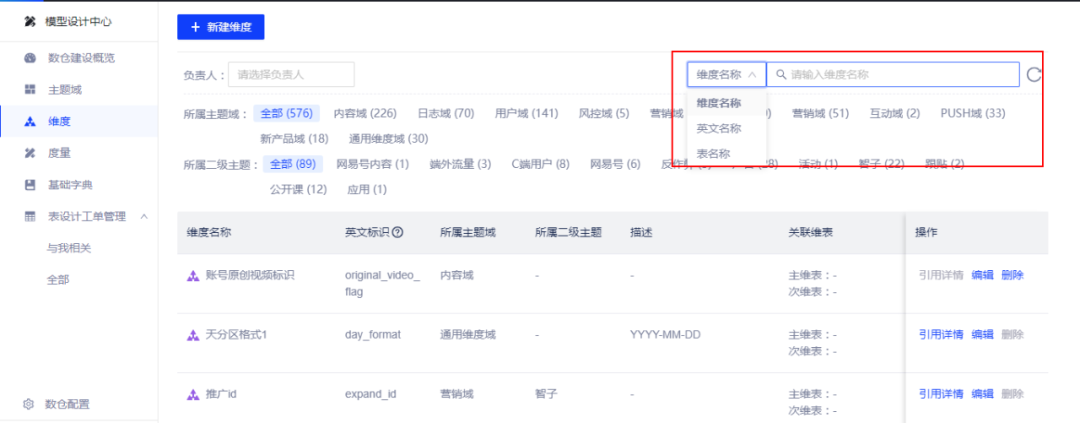
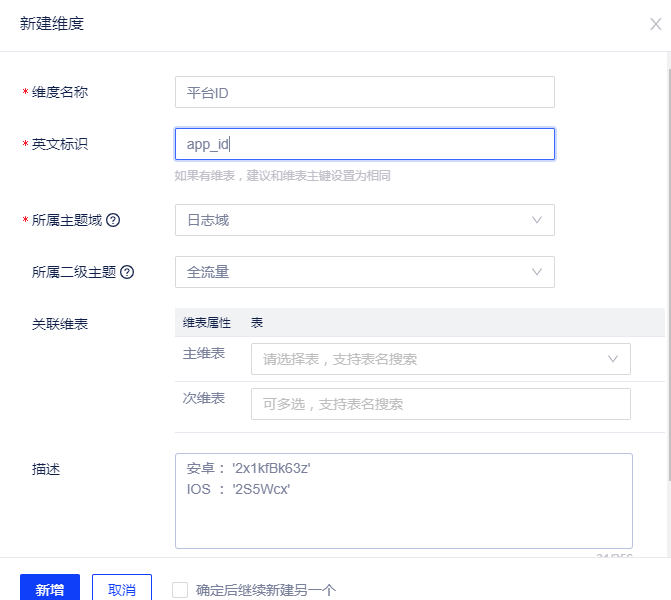
(2)新建维度
5.3 指标建设
(1)查找指标
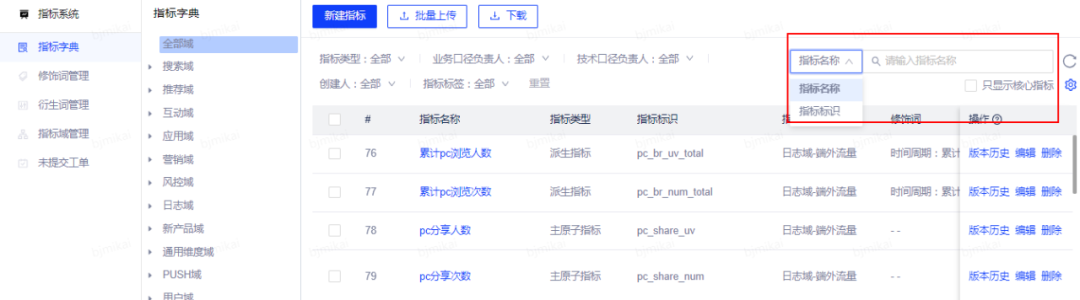
(2)新建修饰词

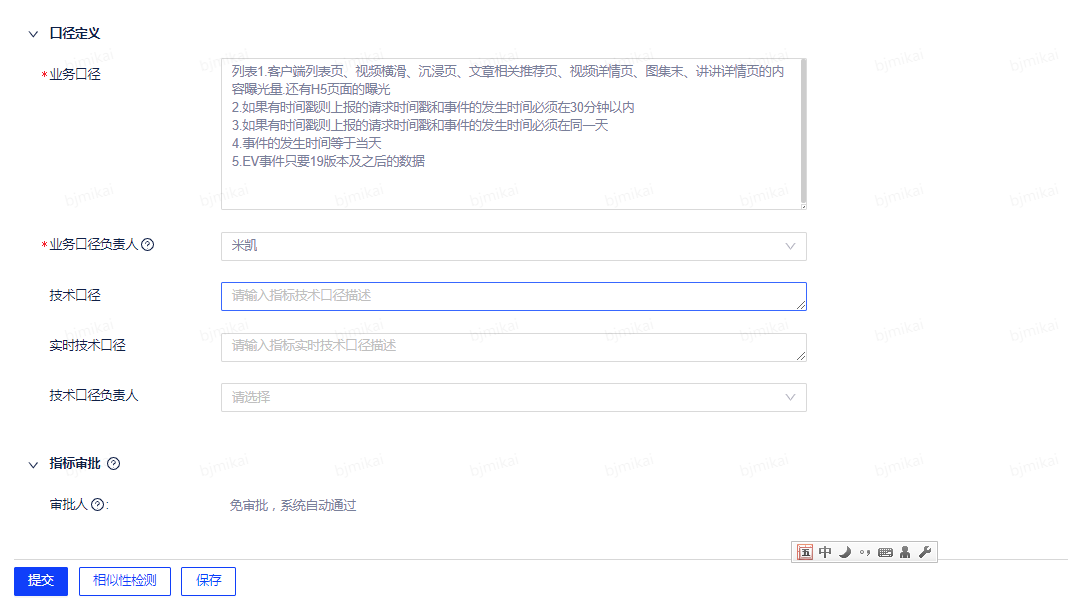
(3)新建指标
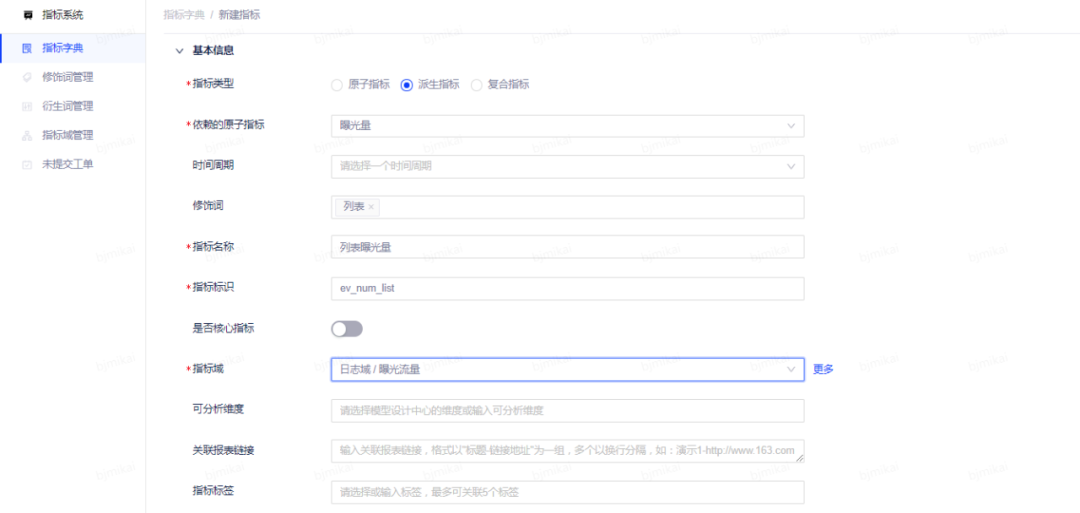
5.4 表建设
(1)表命名
(2)基础属性及字段
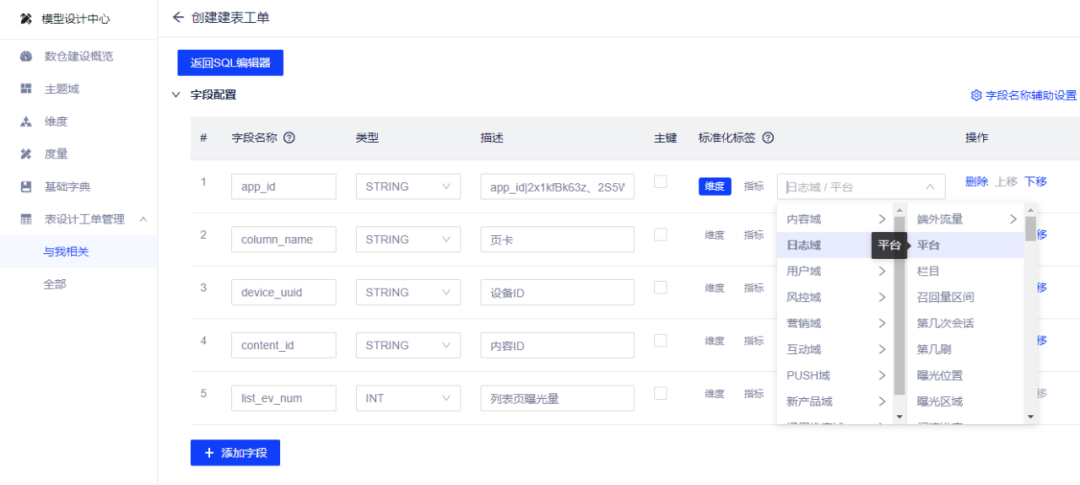
字段命名

关联维度和指标

5.5 收益
(1)指标系统
方便的查询指标间血缘关系
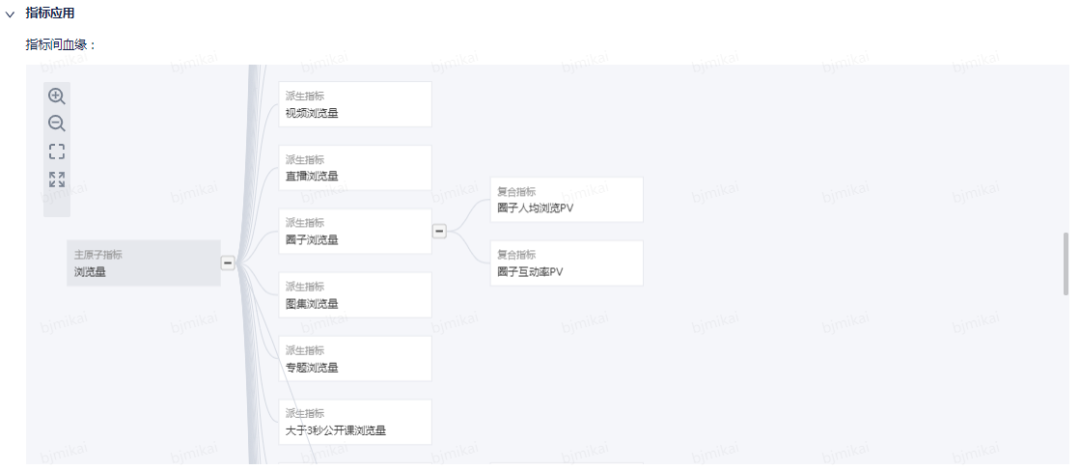
方便查询指标被表引用情况,了解字段的口径
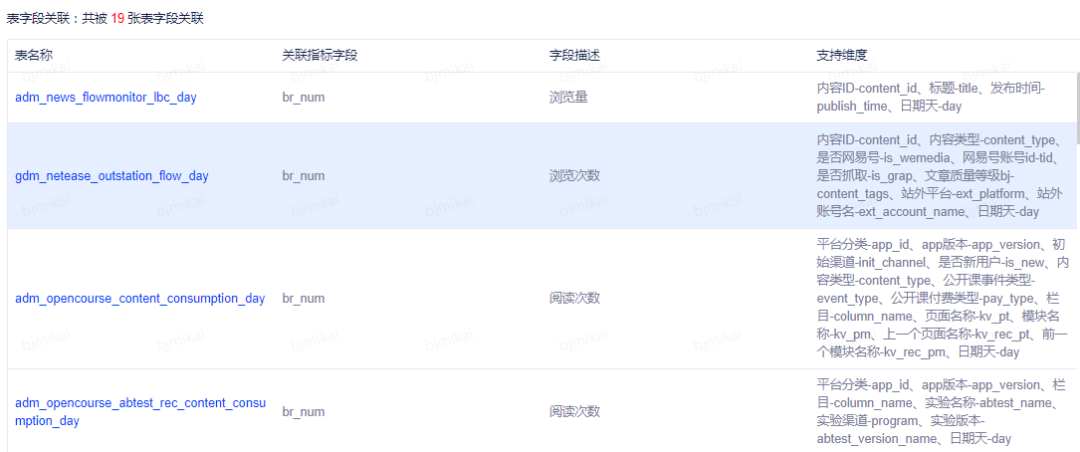
开发人员在建立指标时,一定要先确定指标的口径,这对于后面表脚本开发非常有帮助。
(2)模型设计中心
规范表的命名
清晰分层
维度一致性
数仓使用指标系统来管理指标的业务口径、计算逻辑和数据来源,通过流程化的方式,建立从指标需求、指标开发、指标审核、指标发布的全套协作流程。
数仓使用模型设计中心按照主题域、业务过程,分层的设计方式,以维度建模作为基本理论依据,按照维度、度量设计模型,确保模型、字段有统一的命名规范。
6
未来展望
文章整体介绍了网易传媒数据指标体系的建设情况,网易有数大数据平台已经成为数仓的主要工具,其对于维度、指标和表设计支持的很好,极大的满足了数仓的需求。希望传媒的大数据平台用户不仅是数仓,其他角色也都能参与进来。
好啦,今天的分享就到这里,谢谢大家。
作者简介
螺丝钉,网易传媒数仓开发工程师。2017年入职网易,负责传媒数仓模型设计、指标体系建设。
转自:网易有数 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于网易传媒数据指标体系建设实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!